
本文使用Dify v1.4.0版本,使用qwen-vl-max-latest作为多模态大模型。本文主要介绍负责为大语言模型(LLM)准备提示消息的_fetch_prompt_messages()函数。源码位置:dify\api\core\workflow\nodes\llm\node.py
一.Chatflow流程例子
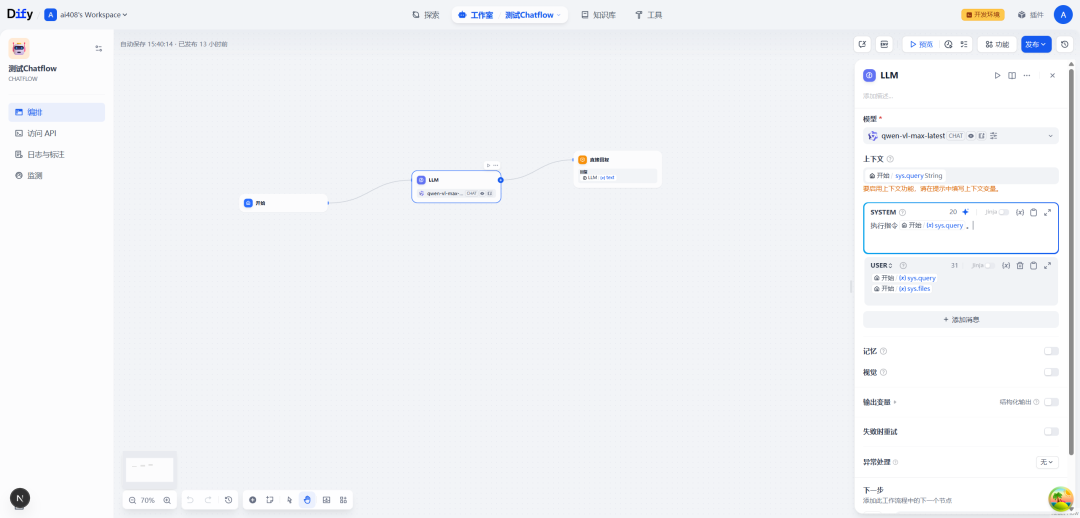
SYSTEM:
执行指令{{#sys.query#}}。
USER:
{{#sys.query#}}
{{#sys.files#}}
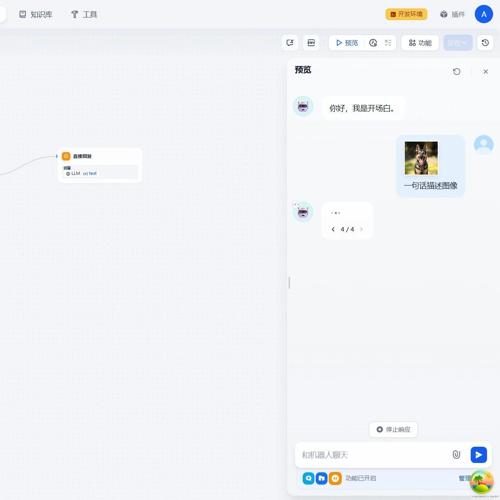
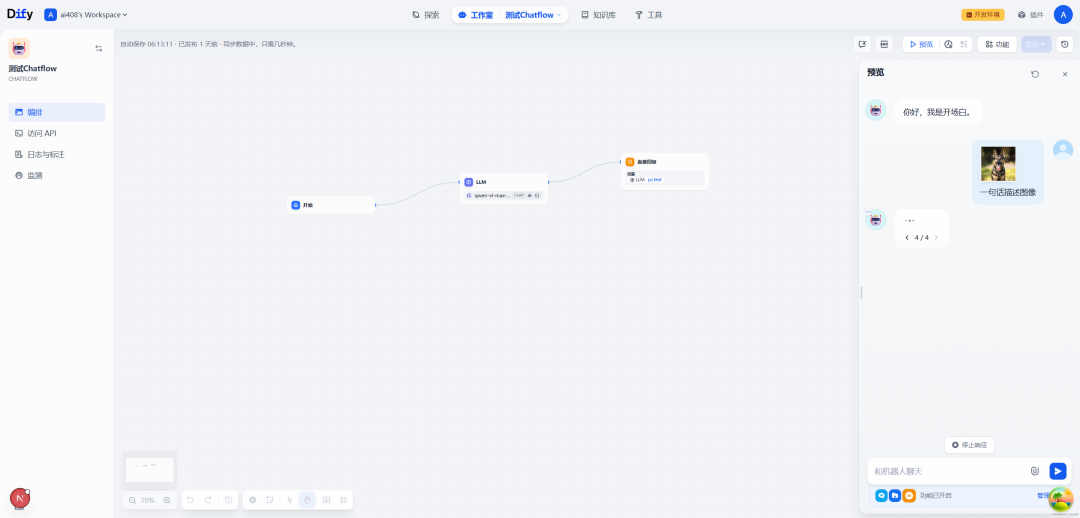
比如,用户在对话的时候,上传了一张图像,并且配上文字:一句话描述图像
二._fetch_prompt_messages函数
该方法负责为大语言模型(LLM)准备提示消息,是LLM节点处理流程的核心部分。方法根据不同模型类型(聊天模型或补全模型)进行处理,并整合各种上下文信息。此方法是连接用户输入与LLM之间的桥梁,确保模型能够理解并正确处理各种格式的输入和上下文信息。主要功能,如下所示:
-
提示模板处理:根据模型类型(聊天模型/补全模型)处理不同格式的提示模板
-
多模态支持:处理图像、视频、音频等多种媒体类型
-
内存管理:集成对话历史记录
-
上下文整合:添加检索的上下文信息
-
结构化输出:支持结构化JSON输出
def_fetch_prompt_messages(
self,
*,
sys_query: str | None = None,
sys_files: Sequence["File"],
context: str | None = None,
memory: TokenBufferMemory | None = None,
model_config: ModelConfigWithCredentialsEntity,
prompt_template: Sequence[LLMNodeChatModelMessage] | LLMNodeCompletionModelPromptTemplate,
memory_config: MemoryConfig | None = None,
vision_enabled: bool = False,
vision_detail: ImagePromptMessageContent.DETAIL,
variable_pool: VariablePool,
jinja2_variables: Sequence[VariableSelector],
) -> tuple[Sequence[PromptMessage], Optional[Sequence[str]]]:
prompt_messages: list[PromptMessage] = []
if isinstance(prompt_template, list):
# For chat model
prompt_messages.extend(
self._handle_list_messages(
messages=prompt_template,
context=context,
jinja2_variables=jinja2_variables,
variable_pool=variable_pool,
vision_detail_config=vision_detail,
)
)
# Get memory messages for chat mode
memory_messages = _handle_memory_chat_mode(
memory=memory,
memory_config=memory_config,
model_config=model_config,
)
# Extend prompt_messages with memory messages
prompt_messages.extend(memory_messages)
# Add current query to the prompt messages
if sys_query:
message = LLMNodeChatModelMessage(
text=sys_query,
role=PromptMessageRole.USER,
edition_type="basic",
)
prompt_messages.extend(
self._handle_list_messages(
messages=[message],
context="",
jinja2_variables=[],
variable_pool=variable_pool,
vision_detail_config=vision_detail,
)
)
elif isinstance(prompt_template, LLMNodeCompletionModelPromptTemplate):
# For completion model
prompt_messages.extend(
_handle_completion_template(
template=prompt_template,
context=context,
jinja2_variables=jinja2_variables,
variable_pool=variable_pool,
)
)
# Get memory text for completion model
memory_text = _handle_memory_completion_mode(
memory=memory,
memory_config=memory_config,
model_config=model_config,
)
# Insert histories into the prompt
prompt_content = prompt_messages[0].content
# For issue #11247 - Check if prompt content is a string or a list
prompt_content_type = type(prompt_content)
if prompt_content_type == str:
prompt_content = str(prompt_content)
if"#histories#"in prompt_content:
prompt_content = prompt_content.replace("#histories#", memory_text)
else:
prompt_content = memory_text + "\n" + prompt_content
prompt_messages[0].content = prompt_content
elif prompt_content_type == list:
prompt_content = prompt_content if isinstance(prompt_content, list) else []
for content_item in prompt_content:
if content_item.type == PromptMessageContentType.TEXT:
if"#histories#"in content_item.data:
content_item.data = content_item.data.replace("#histories#", memory_text)
else:
content_item.data = memory_text + "\n" + content_item.data
else:
raise ValueError("Invalid prompt content type")
# Add current query to the prompt message
if sys_query:
if prompt_content_type == str:
prompt_content = str(prompt_messages[0].content).replace("#sys.query#", sys_query)
prompt_messages[0].content = prompt_content
elif prompt_content_type == list:
prompt_content = prompt_content if isinstance(prompt_content, list) else []
for content_item in prompt_content:
if content_item.type == PromptMessageContentType.TEXT:
content_item.data = sys_query + "\n" + content_item.data
else:
raise ValueError("Invalid prompt content type")
else:
raise TemplateTypeNotSupportError(type_name=str(type(prompt_template)))
# The sys_files will be deprecated later
if vision_enabled and sys_files:
file_prompts = []
for file in sys_files:
file_prompt = file_manager.to_prompt_message_content(file, image_detail_config=vision_detail)
file_prompts.append(file_prompt)
# If last prompt is a user prompt, add files into its contents,
# otherwise append a new user prompt
if (
len(prompt_messages) > 0
and isinstance(prompt_messages[-1], UserPromptMessage)
and isinstance(prompt_messages[-1].content, list)
):
prompt_messages[-1] = UserPromptMessage(content=prompt_messages[-1].content + file_prompts)
else:
prompt_messages.append(UserPromptMessage(content=file_prompts))
# Remove empty messages and filter unsupported content
filtered_prompt_messages = []
for prompt_message in prompt_messages:
if isinstance(prompt_message.content, list):
prompt_message_content: list[PromptMessageContentUnionTypes] = []
for content_item in prompt_message.content:
# Skip content if features are not defined
ifnot model_config.model_schema.features:
if content_item.type != PromptMessageContentType.TEXT:
continue
prompt_message_content.append(content_item)
continue
# Skip content if corresponding feature is not supported
if (
(
content_item.type == PromptMessageContentType.IMAGE
and ModelFeature.VISION notin model_config.model_schema.features
)
or (
content_item.type == PromptMessageContentType.DOCUMENT
and ModelFeature.DOCUMENT notin model_config.model_schema.features
)
or (
content_item.type == PromptMessageContentType.VIDEO
and ModelFeature.VIDEO notin model_config.model_schema.features
)
or (
content_item.type == PromptMessageContentType.AUDIO
and ModelFeature.AUDIO notin model_config.model_schema.features
)
):
continue
prompt_message_content.append(content_item)
if len(prompt_message_content) == 1and prompt_message_content[0].type == PromptMessageContentType.TEXT:
prompt_message.content = prompt_message_content[0].data
else:
prompt_message.content = prompt_message_content
if prompt_message.is_empty():
continue
filtered_prompt_messages.append(prompt_message)
if len(filtered_prompt_messages) == 0:
raise NoPromptFoundError(
"No prompt found in the LLM configuration. "
"Please ensure a prompt is properly configured before proceeding."
)
support_structured_output = self._check_model_structured_output_support()
if support_structured_output == SupportStructuredOutputStatus.UNSUPPORTED:
filtered_prompt_messages = self._handle_prompt_based_schema(
prompt_messages=filtered_prompt_messages,
)
stop = model_config.stop
return filtered_prompt_messages, stop
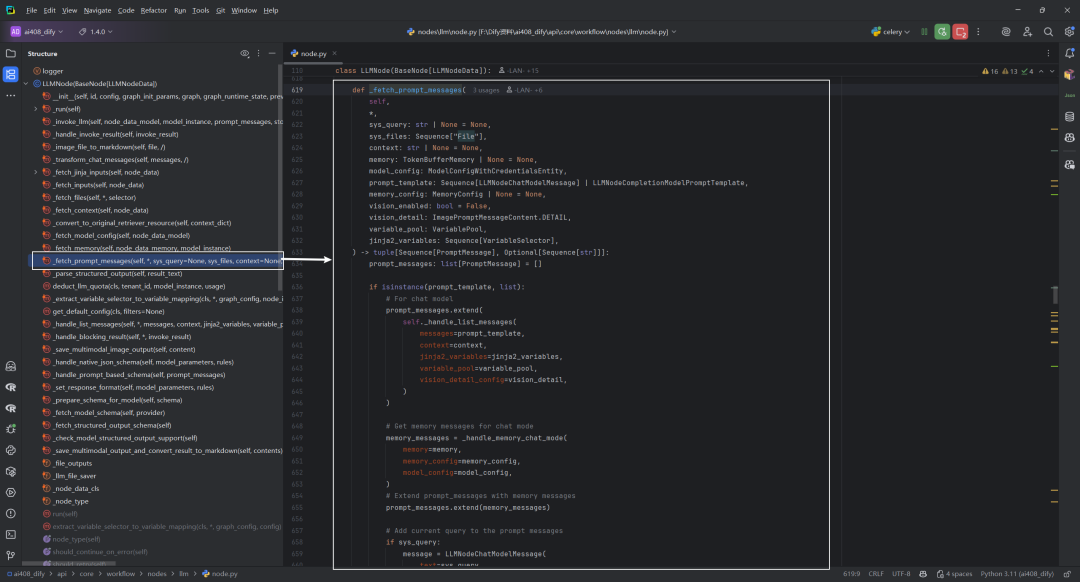
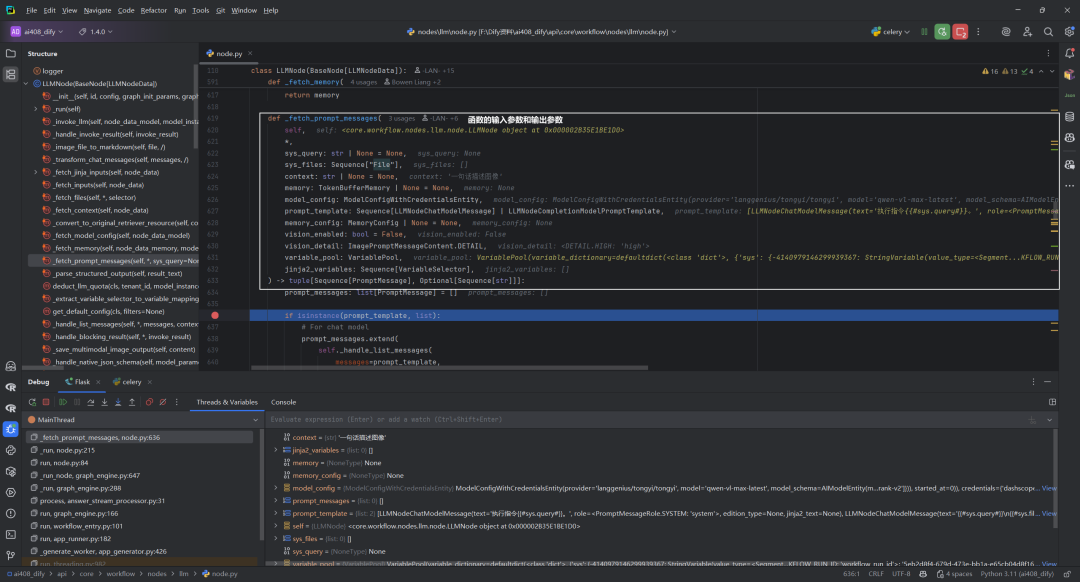
1.输入参数和输出参数
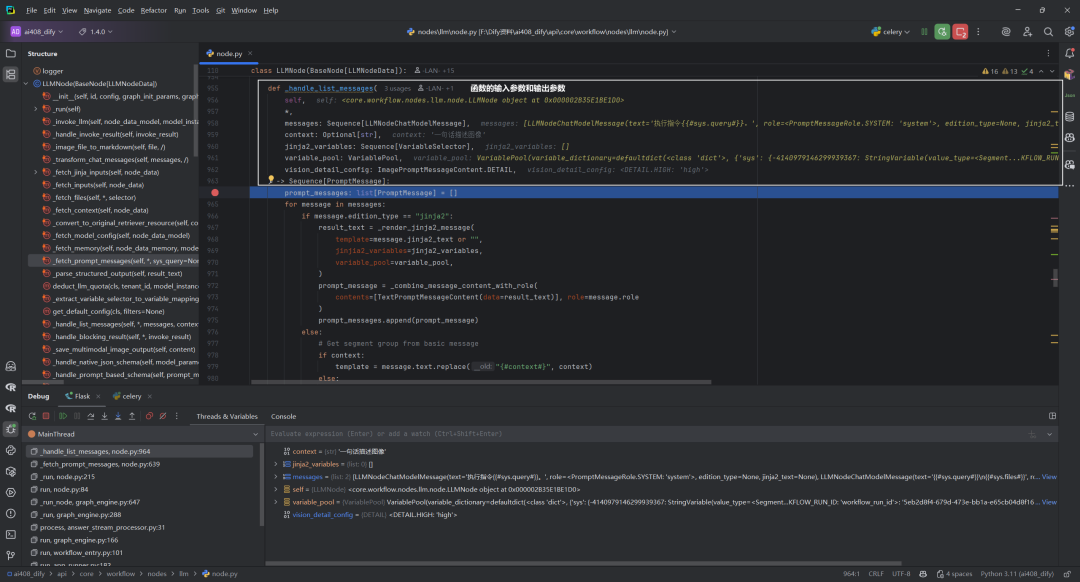
函数的输入参数和输出参数,如下所示:
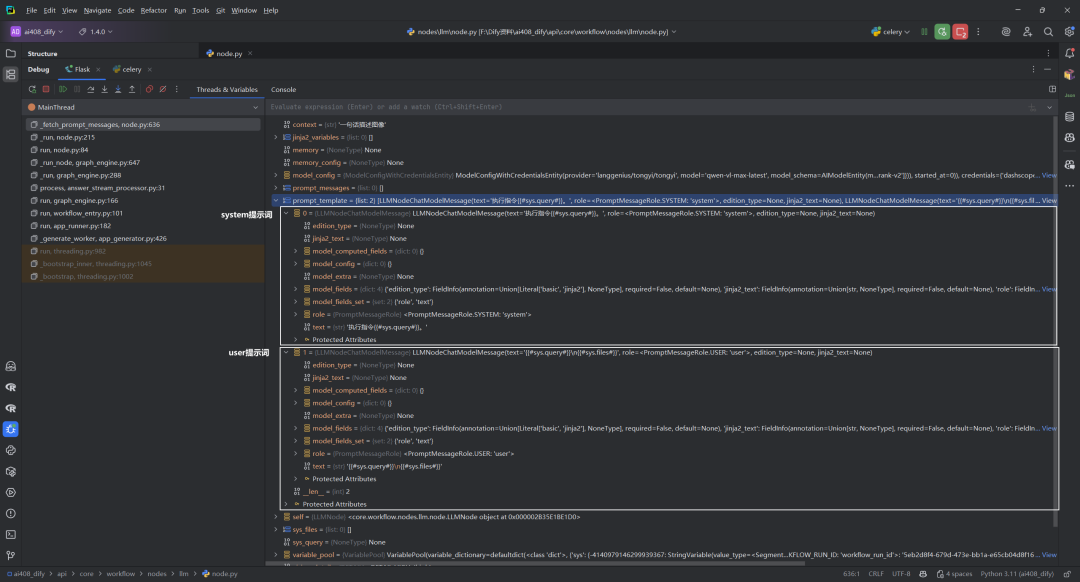
默认的prompt_template,如下所示:
2._handle_list_messages函数
该函数返回的prompt_messages,如下所示:
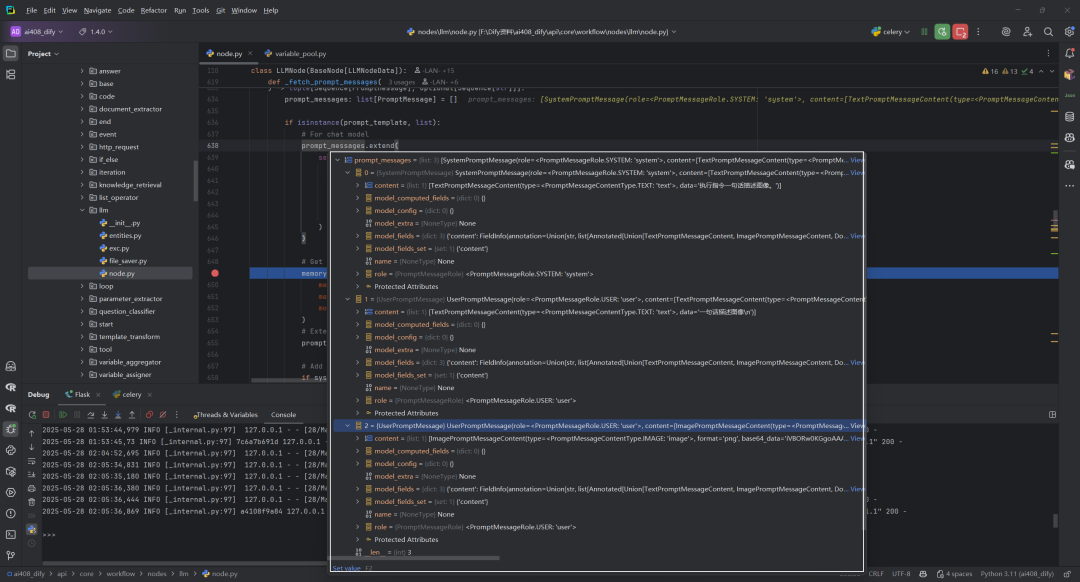
(1)一个SystemPromptMessage,内容为”执行指令一句话描述图像。”
(2)二个UserPromptMessage,即文字(一句话描述图像\n)+图像(base64)。
3._handle_memory_chat_mode 函数
这个函数负责处理聊天模型中的历史对话记忆功能,它从对话历史中获取之前的消息,以便模型能够保持连贯的对话上下文。
def_handle_memory_chat_mode(
*,
memory: TokenBufferMemory | None,
memory_config: MemoryConfig | None,
model_config: ModelConfigWithCredentialsEntity,
) -> Sequence[PromptMessage]:
memory_messages: Sequence[PromptMessage] = []
# Get messages from memory for chat model
if memory and memory_config:
rest_tokens = _calculate_rest_token(prompt_messages=[], model_config=model_config)
memory_messages = memory.get_history_prompt_messages(
max_token_limit=rest_tokens,
message_limit=memory_config.window.size if memory_config.window.enabled elseNone,
)
return memory_messages
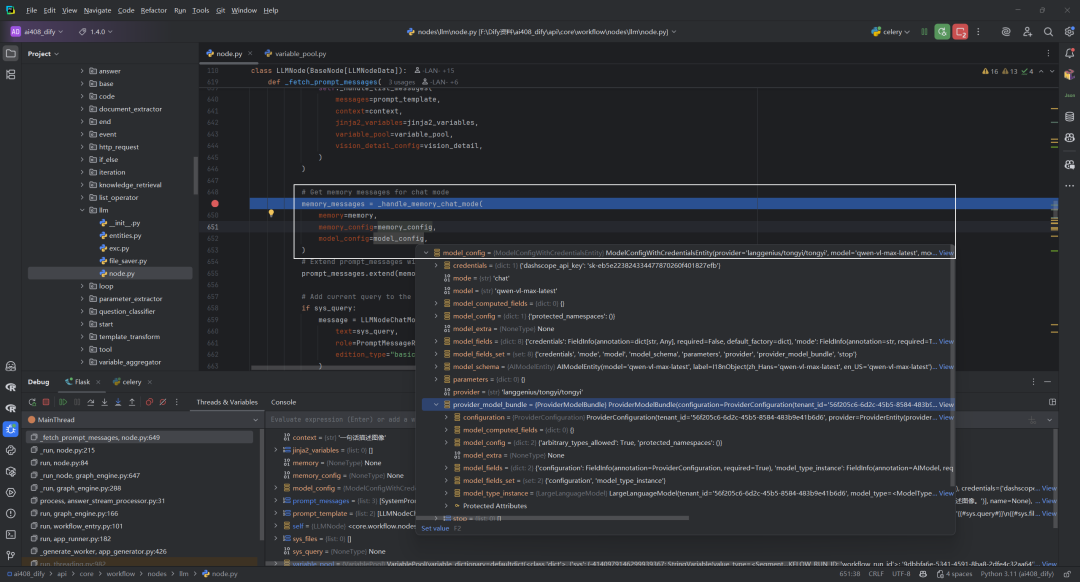
(1)函数参数
-
memory:TokenBufferMemory类型或None,用于存储和管理对话历史 -
memory_config:MemoryConfig类型或None,包含记忆功能的配置参数 -
model_config:ModelConfigWithCredentialsEntity类型,包含当前使用的模型配置
(2)函数逻辑
-
初始化一个空的
memory_messages序列,用于存储历史消息 -
检查是否同时存在有效的
memory和memory_config -
如果都存在,那么:
-
max_token_limit: 最大token数限制,确保不超过模型的上下文长度 -
message_limit: 如果开启了窗口设置,则限制回溯的消息数量 -
调用
_calculate_rest_token计算剩余可用的token数量 -
从
memory中获取历史提示消息,同时应用两种限制:
(3)作用
这个函数对于实现连续对话至关重要,它确保大语言模型能够”记住”之前的对话内容,同时通过token和消息数量限制来优化性能和资源使用。
4.文件处理逻辑
这段代码处理在LLM节点中如何将视觉文件(如图像)整合到提示消息中,这种处理方式确保视觉文件能够被正确地整合到提示上下文中,使模型能够”看到”并处理这些图像信息。
# 注释表明sys_files将被弃用
if vision_enabled and sys_files:
file_prompts = []
for file in sys_files:
# 将文件转换为模型可理解的提示内容格式
file_prompt = file_manager.to_prompt_message_content(file, image_detail_config=vision_detail)
file_prompts.append(file_prompt)
# 智能合并文件内容到现有提示中
if (
len(prompt_messages) > 0
and isinstance(prompt_messages[-1], UserPromptMessage)
and isinstance(prompt_messages[-1].content, list)
):
# 如果最后一条是用户消息且内容为列表,将文件添加到现有内容中
prompt_messages[-1] = UserPromptMessage(content=prompt_messages[-1].content + file_prompts)
else:
# 否则创建新的用户消息
prompt_messages.append(UserPromptMessage(content=file_prompts))
5.消息过滤与兼容性检查
这段代码负责过滤和处理提示消息(prompt messages),确保只向模型发送其支持的内容类型。
# 创建过滤后的消息列表
filtered_prompt_messages = []
for prompt_message in prompt_messages:
if isinstance(prompt_message.content, list):
prompt_message_content = []
for content_item in prompt_message.content:
# 两个主要过滤条件:
# 1. 如果模型没有定义特性,只保留文本内容
# 2. 根据模型支持的特性过滤掉不支持的内容类型(图像、文档、视频、音频)
# 内容优化:如果列表中只有一个文本项,直接使用文本字符串
if len(prompt_message_content) == 1and prompt_message_content[0].type == PromptMessageContentType.TEXT:
prompt_message.content = prompt_message_content[0].data
else:
prompt_message.content = prompt_message_content
# 跳过空消息
if prompt_message.is_empty():
continue
filtered_prompt_messages.append(prompt_message)
6.错误处理与结构化输出支持
这段代码确保了发送给语言模型的提示是有效的,并根据模型能力对结构化输出需求进行了处理。当模型不支持原生JSON模式时,会使用基于提示的方法引导模型生成格式化输出,这是处理不同模型能力差异的一种重要策略。
# 确保至少有一条提示消息
if len(filtered_prompt_messages) == 0:
raise NoPromptFoundError(
"No prompt found in the LLM configuration. "
"Please ensure a prompt is properly configured before proceeding."
)
# 结构化输出处理
support_structured_output = self._check_model_structured_output_support()
if support_structured_output == SupportStructuredOutputStatus.UNSUPPORTED:
# 如果模型不支持原生结构化输出,使用提示工程方式实现
filtered_prompt_messages = self._handle_prompt_based_schema(
prompt_messages=filtered_prompt_messages,
)
三._handle_list_messages
源码位置:dify\api\core\workflow\nodes\llm\node.py
这个函数负责将LLMNodeChatModelMessage消息序列转换为系统可以处理的PromptMessage对象序列。它处理两种类型的消息模板:Jinja2模板和基本文本模板。
这个函数是LLM节点处理不同类型提示模板的关键组件,支持从简单文本替换到复杂的Jinja2模板渲染,并能处理多模态内容(文本、图像、视频等)。
def_handle_list_messages(
self,
*,
messages: Sequence[LLMNodeChatModelMessage],
context: Optional[str],
jinja2_variables: Sequence[VariableSelector],
variable_pool: VariablePool,
vision_detail_config: ImagePromptMessageContent.DETAIL,
) -> Sequence[PromptMessage]:
prompt_messages: list[PromptMessage] = []
for message in messages:
if message.edition_type == "jinja2":
result_text = _render_jinja2_message(
template=message.jinja2_text or"",
jinjia2_variables=jinja2_variables,
variable_pool=variable_pool,
)
prompt_message = _combine_message_content_with_role(
contents=[TextPromptMessageContent(data=result_text)], role=message.role
)
prompt_messages.append(prompt_message)
else:
# Get segment group from basic message
if context:
template = message.text.replace("{#context#}", context)
else:
template = message.text
segment_group = variable_pool.convert_template(template)
# Process segments for images
file_contents = []
for segment in segment_group.value:
if isinstance(segment, ArrayFileSegment):
for file in segment.value:
if file.type in {FileType.IMAGE, FileType.VIDEO, FileType.AUDIO, FileType.DOCUMENT}:
file_content = file_manager.to_prompt_message_content(
file, image_detail_config=vision_detail_config
)
file_contents.append(file_content)
elif isinstance(segment, FileSegment):
file = segment.value
if file.type in {FileType.IMAGE, FileType.VIDEO, FileType.AUDIO, FileType.DOCUMENT}:
file_content = file_manager.to_prompt_message_content(
file, image_detail_config=vision_detail_config
)
file_contents.append(file_content)
# Create message with text from all segments
plain_text = segment_group.text
if plain_text:
prompt_message = _combine_message_content_with_role(
contents=[TextPromptMessageContent(data=plain_text)], role=message.role
)
prompt_messages.append(prompt_message)
if file_contents:
# Create message with image contents
prompt_message = _combine_message_content_with_role(contents=file_contents, role=message.role)
prompt_messages.append(prompt_message)
return prompt_messages
1.函数参数
-
messages: 要处理的聊天模型消息序列 -
context: 可选的上下文字符串,用于替换模板中的{#context#} -
jinja2_variables: Jinja2变量选择器列表 -
variable_pool: 变量池对象,用于提取和转换变量 -
vision_detail_config: 图像处理细节配置
2.执行流程
函数初始化一个空的prompt_messages列表,然后遍历每条输入消息:
(1)Jinja2模板处理流程
当消息的edition_type为"jinja2"时:
-
调用
_render_jinja2_message函数渲染模板 -
使用
_combine_message_content_with_role函数创建带有文本内容的提示消息 -
将新创建的消息添加到结果列表
(2)基本消息处理流程
当消息是基本类型时:
-
处理上下文替换:如果有上下文,将
{#context#}替换为实际上下文 -
使用
variable_pool.convert_template将模板转换为分段组(segment_group)
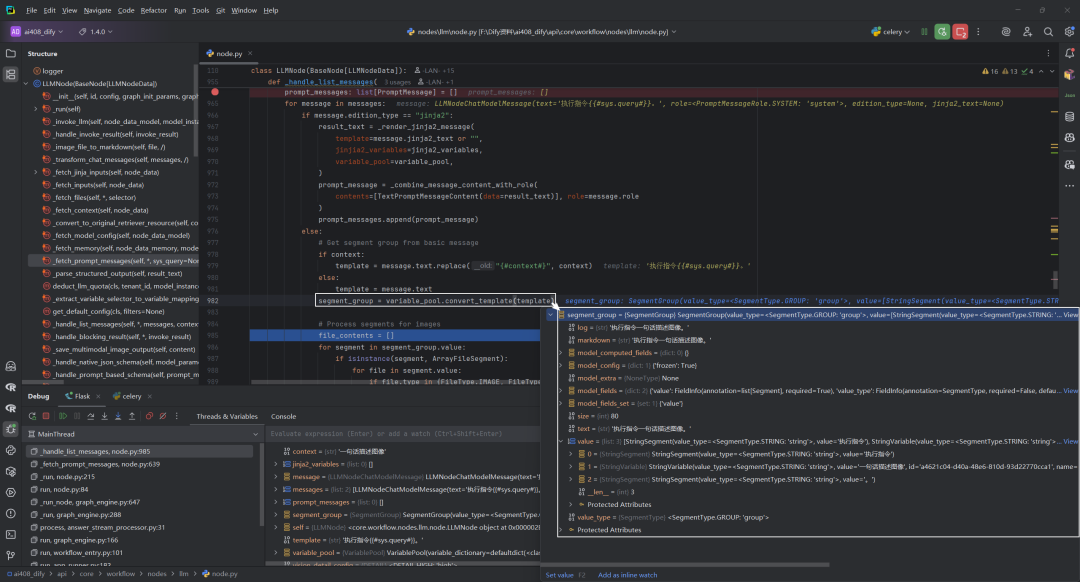
遍历messages[0]时,segment_group结果,如下所示:
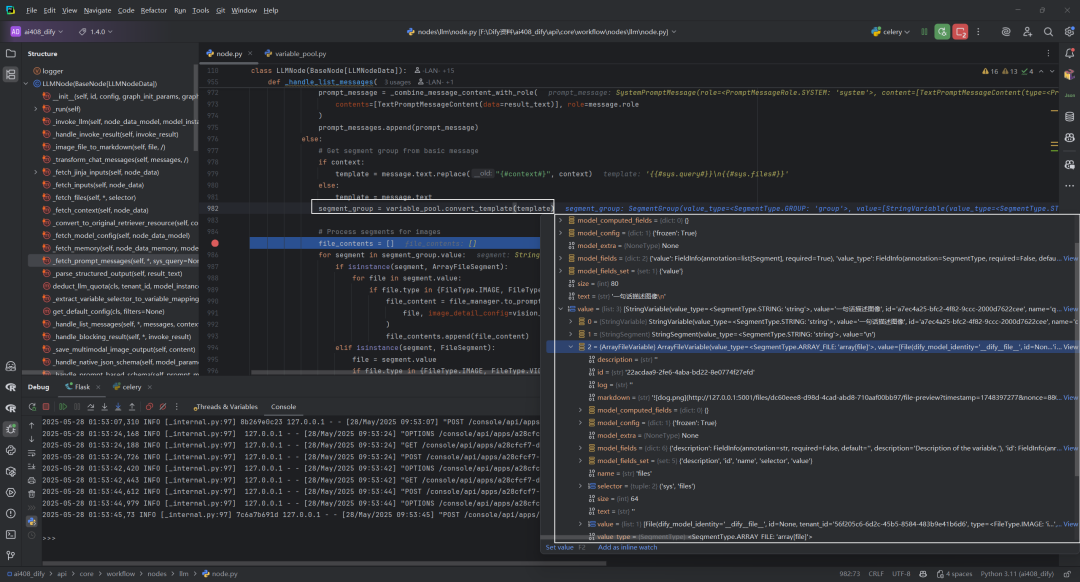
遍历messages[1]时,segment_group结果,如下所示:
-
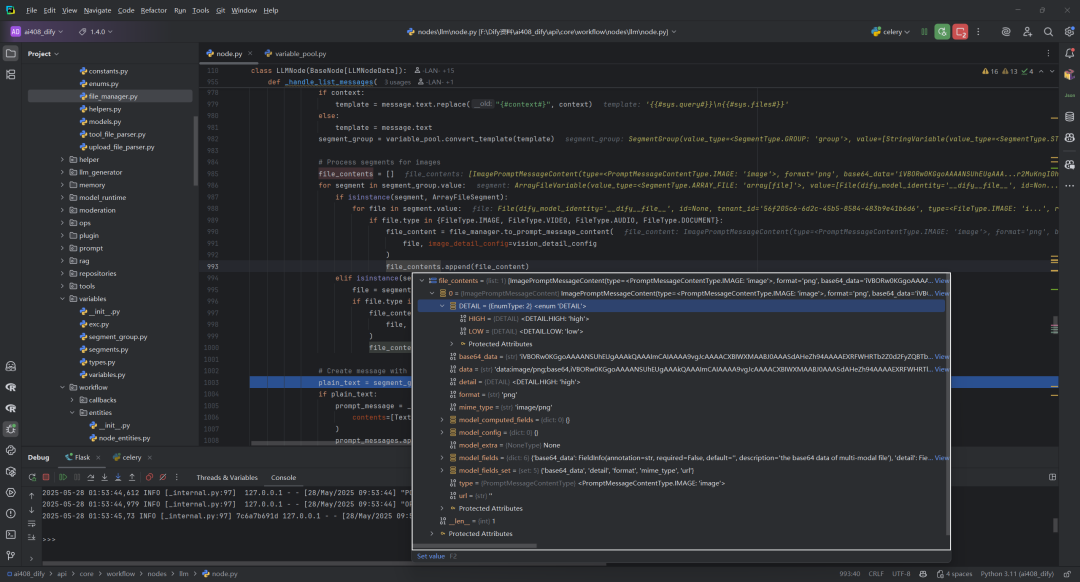
多媒体文件处理:
-
遍历所有段(
segment) -
对
ArrayFileSegment(文件数组)和FileSegment(单个文件)进行特殊处理 -
对图像、视频、音频和文档类型的文件,使用
file_manager.to_prompt_message_content创建相应的内容对象 -
收集所有文件内容到
file_contents列表
-
创建并添加消息:
-
如果有纯文本内容,创建文本消息并添加到结果列表
-
如果有文件内容,创建多媒体消息并添加到结果列表
3.返回结果
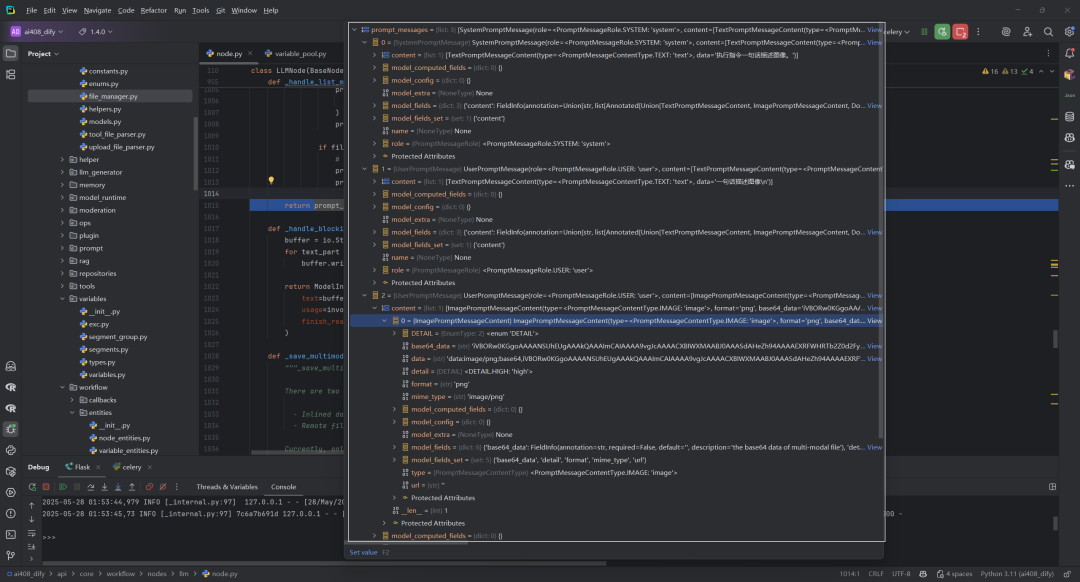
函数返回处理后的PromptMessage对象列表,这些对象保留了原始消息的角色,并包含转换后的内容(文本或多媒体)。
四.to_prompt_message_content函数
源码位置:dify\api\core\file\file_manager.py
这个函数将 File 对象转换成适合在多模态提示中使用的消息内容对象。这个函数是多模态AI处理的关键组件,它能将不同类型的文件转换为统一格式的提示消息内容,便于模型处理多种媒体类型。
defto_prompt_message_content(
f: File,
/,
*,
image_detail_config: ImagePromptMessageContent.DETAIL | None = None,
) -> PromptMessageContentUnionTypes:
if f.extension isNone:
raise ValueError("Missing file extension")
if f.mime_type isNone:
raise ValueError("Missing file mime_type")
params = {
"base64_data": _get_encoded_string(f) if dify_config.MULTIMODAL_SEND_FORMAT == "base64"else"",
"url": _to_url(f) if dify_config.MULTIMODAL_SEND_FORMAT == "url"else"",
"format": f.extension.removeprefix("."),
"mime_type": f.mime_type,
}
if f.type == FileType.IMAGE:
params["detail"] = image_detail_config or ImagePromptMessageContent.DETAIL.LOW
prompt_class_map: Mapping[FileType, type[PromptMessageContentUnionTypes]] = {
FileType.IMAGE: ImagePromptMessageContent,
FileType.AUDIO: AudioPromptMessageContent,
FileType.VIDEO: VideoPromptMessageContent,
FileType.DOCUMENT: DocumentPromptMessageContent,
}
try:
return prompt_class_map[f.type].model_validate(params)
except KeyError:
raise ValueError(f"file type {f.type} is not supported")
函数签名,如下所示:
defto_prompt_message_content(
f: File, # File对象作为位置参数
/, # 斜杠表示后面的参数必须是关键字参数
*, # 星号表示后面所有参数必须通过关键字传递
image_detail_config: ImagePromptMessageContent.DETAIL | None = None, # 图像细节配置,可选
) -> PromptMessageContentUnionTypes:# 返回类型是各种提示消息内容类型的联合类型
执行流程,如下所示:
1.参数验证
检查文件是否有扩展名和MIME类型,缺少任一项都会抛出异常。
2.构建参数字典
params = {
"base64_data": _get_encoded_string(f) if dify_config.MULTIMODAL_SEND_FORMAT == "base64"else"",
"url": _to_url(f) if dify_config.MULTIMODAL_SEND_FORMAT == "url"else"",
"format": f.extension.removeprefix("."),
"mime_type": f.mime_type,
}
-
根据配置决定使用base64格式还是URL格式
-
提取文件格式和MIME类型信息
3.图像特殊处理
-
如果是图像文件,额外添加细节级别配置
4.类型映射
定义一个字典,将文件类型映射到对应的提示消息内容类:
-
图像 →
ImagePromptMessageContent -
音频 →
AudioPromptMessageContent -
视频 →
VideoPromptMessageContent -
文档 →
DocumentPromptMessageContent
5.创建对象
-
尝试使用对应类的
model_validate方法创建实例 -
如果文件类型不受支持,抛出
ValueError异常
五.convert_template
源码位置:dify\api\core\workflow\entities\variable_pool.py
这个方法的作用是将包含变量引用的模板字符串转换为 SegmentGroup 对象。简单来说,这个方法将模板中的变量引用(如{{#system.user_name#}})替换为实际变量值,并将整个模板转换为由文本和变量组成的段组。
defconvert_template(self, template: str, /):
parts = VARIABLE_PATTERN.split(template)
segments = []
for part in filter(lambda x: x, parts):
if"."in part and (variable := self.get(part.split("."))):
segments.append(variable)
else:
segments.append(variable_factory.build_segment(part))
return SegmentGroup(value=segments)
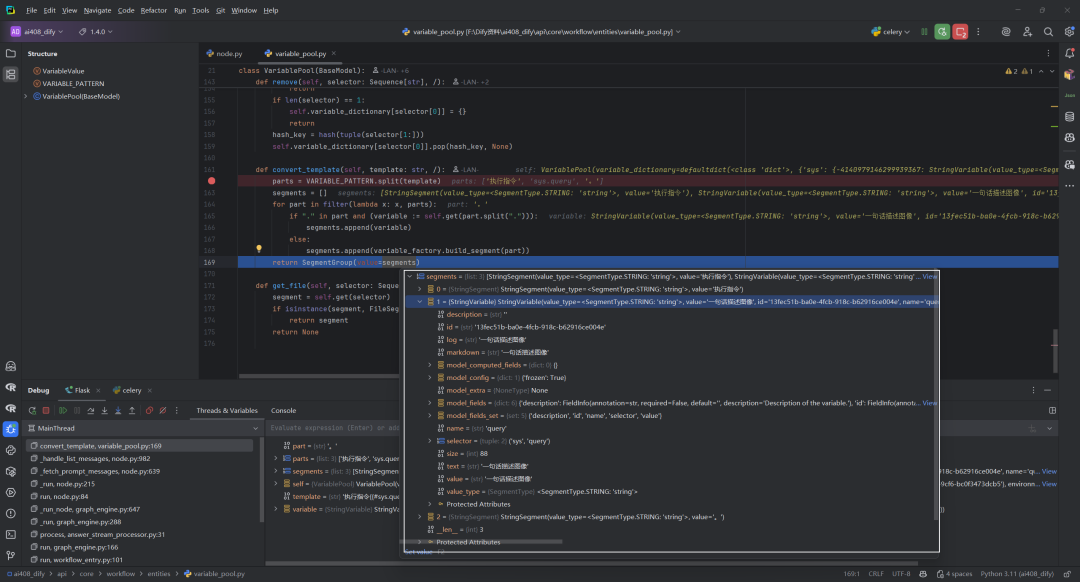
1.参数接收
-
接收一个模板字符串 template(仅位置参数)
2.变量解析过程
-
使用
VARIABLE_PATTERN正则表达式分割模板字符串 -
这个正则匹配形如
{{#node_id.variable_name#}}的变量引用
3.变量替换逻辑
-
创建空列表
segments存储处理结果 -
过滤掉空字符串后遍历剩余部分:
-
如果部分包含”.”且能从变量池获取到对应变量,则添加该变量
-
否则,将该部分作为普通文本构建成段并添加
4.返回结果
-
将所有处理后的段组合成 SegmentGroup对象返回
六.build_segment
源码位置:dify\api\factories\variable_factory.py
这个函数的作用是将任意类型的值转换为对应的 Segment 对象,是一个类型转换工具。该函数实现了一个类型系统转换器,将 Python 原生数据类型映射到应用内部的 Segment 类型系统中,确保系统可以以统一的方式处理各种类型的数据。这是工厂模式的一种实现,根据输入值的类型创建相应的 Segment 对象。
defbuild_segment(value: Any, /) -> Segment:
if value isNone:
return NoneSegment()
if isinstance(value, str):
return StringSegment(value=value)
if isinstance(value, int):
return IntegerSegment(value=value)
if isinstance(value, float):
return FloatSegment(value=value)
if isinstance(value, dict):
return ObjectSegment(value=value)
if isinstance(value, File):
return FileSegment(value=value)
if isinstance(value, list):
items = [build_segment(item) for item in value]
types = {item.value_type for item in items}
if len(types) != 1or all(isinstance(item, ArraySegment) for item in items):
return ArrayAnySegment(value=value)
match types.pop():
case SegmentType.STRING:
return ArrayStringSegment(value=value)
case SegmentType.NUMBER:
return ArrayNumberSegment(value=value)
case SegmentType.OBJECT:
return ArrayObjectSegment(value=value)
case SegmentType.FILE:
return ArrayFileSegment(value=value)
case SegmentType.NONE:
return ArrayAnySegment(value=value)
case _:
raise ValueError(f"not supported value {value}")
raise ValueError(f"not supported value {value}")
1.函数签名
defbuild_segment(value: Any, /) -> Segment:
-
接收任意类型的值作为输入
-
/表示后面的参数必须是位置参数 -
返回一个
Segment类型的对象
2.基本类型处理
-
None→ 返回NoneSegment() -
字符串 → 返回
StringSegment(value=value) -
整数 → 返回
IntegerSegment(value=value) -
浮点数 → 返回
FloatSegment(value=value) -
字典 → 返回
ObjectSegment(value=value) -
File对象 → 返回FileSegment(value=value)
3.列表类型处理
-
递归调用
build_segment处理列表中的每个元素 -
收集所有元素的
value_type并去重 -
如果元素类型不唯一或都是
ArraySegment,返回ArrayAnySegment -
根据唯一类型匹配相应的数组段类型:
-
字符串数组 →
ArrayStringSegment -
数字数组 →
ArrayNumberSegment -
对象数组 →
ArrayObjectSegment -
文件数组 →
ArrayFileSegment -
空值数组 →
ArrayAnySegment
4.异常处理
如果遇到不支持的类型,抛出 ValueError 异常。
参考文献
[1] Dify工作流中的LLM节点:_fetch_prompt_messages方法:https://z0yrmerhgi8.feishu.cn/wiki/Hb50wLev1ioTgDkhGJ6c0cgKnMg
[2] LLMNode类:https://github.com/langgenius/dify/blob/1.4.0/api/core/workflow/nodes/llm/node.py
知识星球服务内容:Dify源码剖析及答疑,Dify对话系统源码,NLP电子书籍报告下载,公众号所有付费资料。加微信buxingtianxia21进NLP工程化资料群。
(文:NLP工程化)