
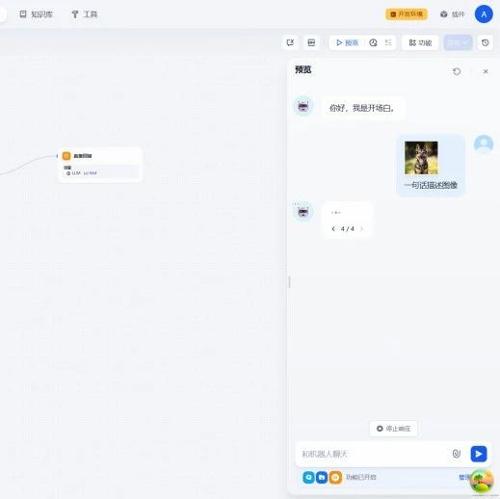
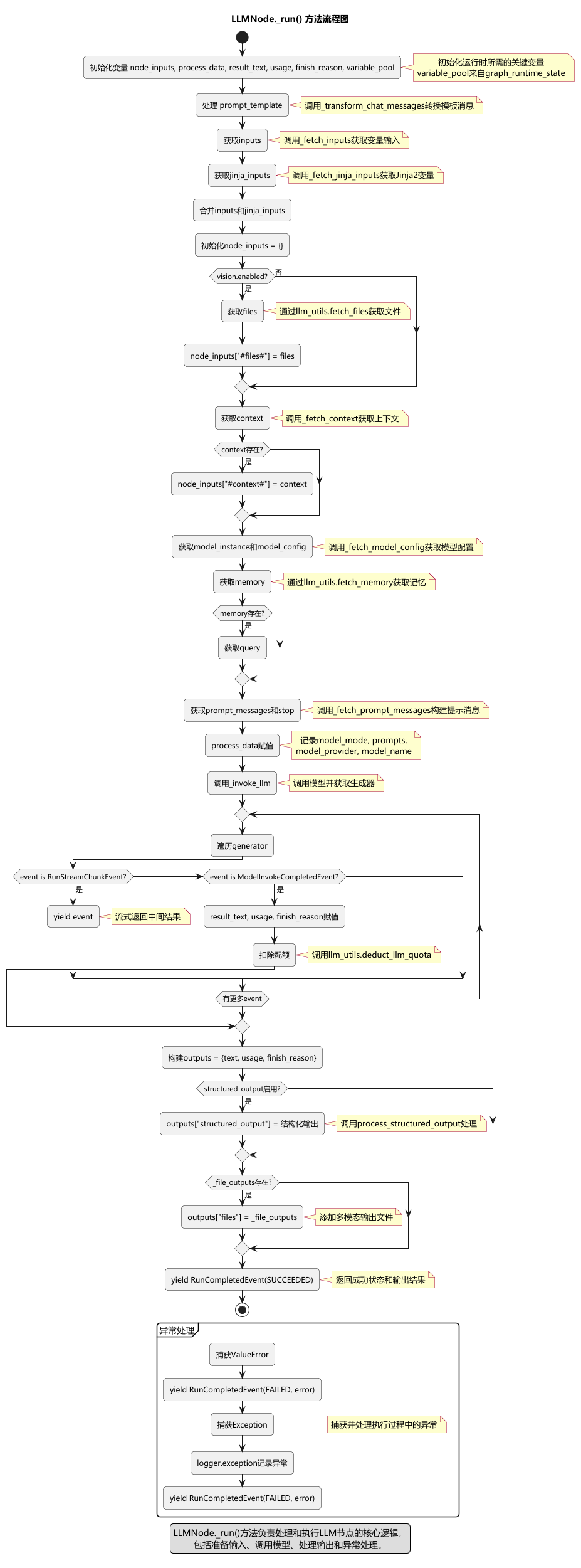
本文使用Dify v1.4.0版本,使用qwen-vl-max-latest作为多模态大模型。主要介绍负责LLMNode完整工作流程的_run核心执行方法。LLMNode._run()方法流程图,如下所示:
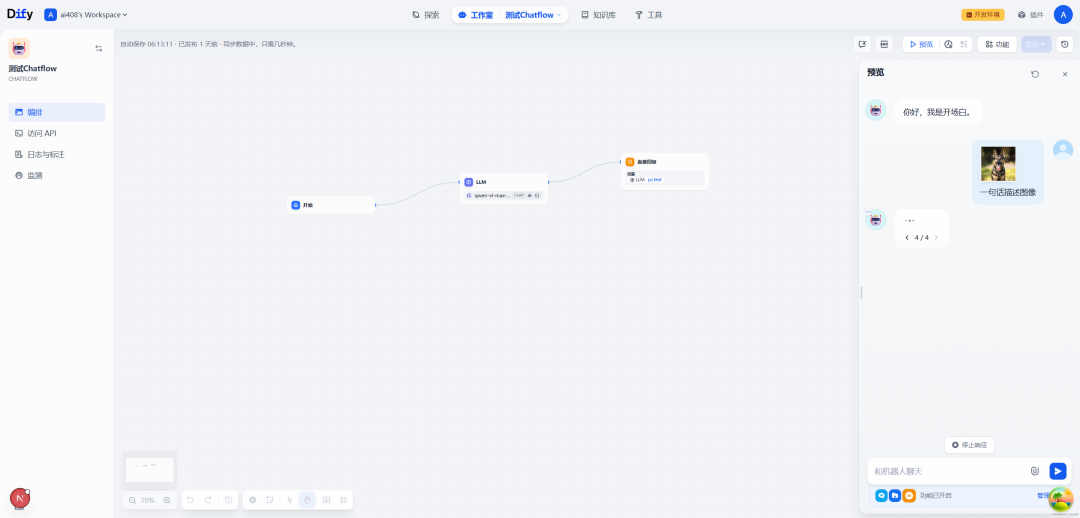
一.Chatflow流程示例
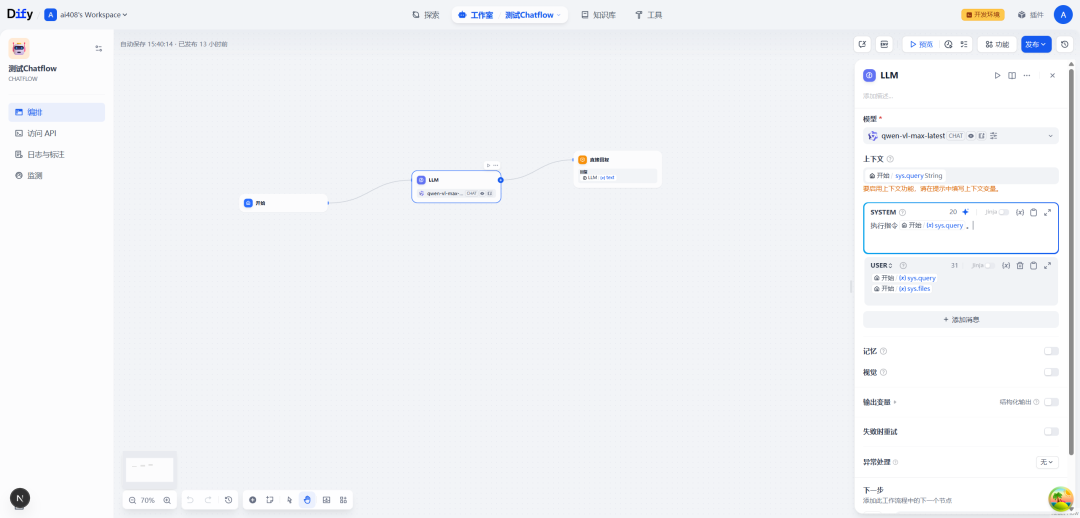
SYSTEM:
执行指令{{#sys.query#}}。
USER:
{{#sys.query#}}
{{#sys.files#}}
比如,用户在对话的时候,上传了一张图像,并且配上文字:一句话描述图像
二._run方法源码
源码位置:dify\api\core\workflow\nodes\llm\node.py
_run方法是LLMNode的核心执行方法,负责大型语言模型节点的完整工作流程。这个方法是一个生成器函数,它通过yield语句向调用者传递各种事件,包括流式输出块、资源检索事件和完成事件,实现了大语言模型节点的完整处理流程。
def_run(self) -> Generator[NodeEvent | InNodeEvent, None, None]:
defprocess_structured_output(text: str) -> Optional[dict[str, Any]]:
"""Process structured output if enabled"""
ifnot self.node_data.structured_output_enabled ornot self.node_data.structured_output:
returnNone
return self._parse_structured_output(text)
node_inputs: Optional[dict[str, Any]] = None
process_data = None
result_text = ""
usage = LLMUsage.empty_usage()
finish_reason = None
try:
# init messages template
self.node_data.prompt_template = self._transform_chat_messages(self.node_data.prompt_template)
# fetch variables and fetch values from variable pool
inputs = self._fetch_inputs(node_data=self.node_data)
# fetch jinja2 inputs
jinja_inputs = self._fetch_jinja_inputs(node_data=self.node_data)
# merge inputs
inputs.update(jinja_inputs)
node_inputs = {}
# fetch files
files = (
self._fetch_files(selector=self.node_data.vision.configs.variable_selector)
if self.node_data.vision.enabled
else []
)
if files:
node_inputs["#files#"] = [file.to_dict() for file in files]
# fetch context value
generator = self._fetch_context(node_data=self.node_data)
context = None
for event in generator:
if isinstance(event, RunRetrieverResourceEvent):
context = event.context
yield event
if context:
node_inputs["#context#"] = context
# fetch model config
model_instance, model_config = self._fetch_model_config(self.node_data.model)
# fetch memory
memory = self._fetch_memory(node_data_memory=self.node_data.memory, model_instance=model_instance)
query = None
if self.node_data.memory:
query = self.node_data.memory.query_prompt_template
ifnot query and (
query_variable := self.graph_runtime_state.variable_pool.get(
(SYSTEM_VARIABLE_NODE_ID, SystemVariableKey.QUERY)
)
):
query = query_variable.text
prompt_messages, stop = self._fetch_prompt_messages(
sys_query=query,
sys_files=files,
context=context,
memory=memory,
model_config=model_config,
prompt_template=self.node_data.prompt_template,
memory_config=self.node_data.memory,
vision_enabled=self.node_data.vision.enabled,
vision_detail=self.node_data.vision.configs.detail,
variable_pool=self.graph_runtime_state.variable_pool,
jinja2_variables=self.node_data.prompt_config.jinja2_variables,
)
process_data = {
"model_mode": model_config.mode,
"prompts": PromptMessageUtil.prompt_messages_to_prompt_for_saving(
model_mode=model_config.mode, prompt_messages=prompt_messages
),
"model_provider": model_config.provider,
"model_name": model_config.model,
}
# handle invoke result
generator = self._invoke_llm(
node_data_model=self.node_data.model,
model_instance=model_instance,
prompt_messages=prompt_messages,
stop=stop,
)
for event in generator:
if isinstance(event, RunStreamChunkEvent):
yield event
elif isinstance(event, ModelInvokeCompletedEvent):
result_text = event.text
usage = event.usage
finish_reason = event.finish_reason
# deduct quota
self.deduct_llm_quota(tenant_id=self.tenant_id, model_instance=model_instance, usage=usage)
break
outputs = {"text": result_text, "usage": jsonable_encoder(usage), "finish_reason": finish_reason}
structured_output = process_structured_output(result_text)
if structured_output:
outputs["structured_output"] = structured_output
if self._file_outputs isnotNone:
outputs["files"] = self._file_outputs
yield RunCompletedEvent(
run_result=NodeRunResult(
status=WorkflowNodeExecutionStatus.SUCCEEDED,
inputs=node_inputs,
process_data=process_data,
outputs=outputs,
metadata={
NodeRunMetadataKey.TOTAL_TOKENS: usage.total_tokens,
NodeRunMetadataKey.TOTAL_PRICE: usage.total_price,
NodeRunMetadataKey.CURRENCY: usage.currency,
},
llm_usage=usage,
)
)
except LLMNodeError as e:
yield RunCompletedEvent(
run_result=NodeRunResult(
status=WorkflowNodeExecutionStatus.FAILED,
error=str(e),
inputs=node_inputs,
process_data=process_data,
error_type=type(e).__name__,
)
)
except Exception as e:
logger.exception("error while executing llm node")
yield RunCompletedEvent(
run_result=NodeRunResult(
status=WorkflowNodeExecutionStatus.FAILED,
error=str(e),
inputs=node_inputs,
process_data=process_data,
)
)
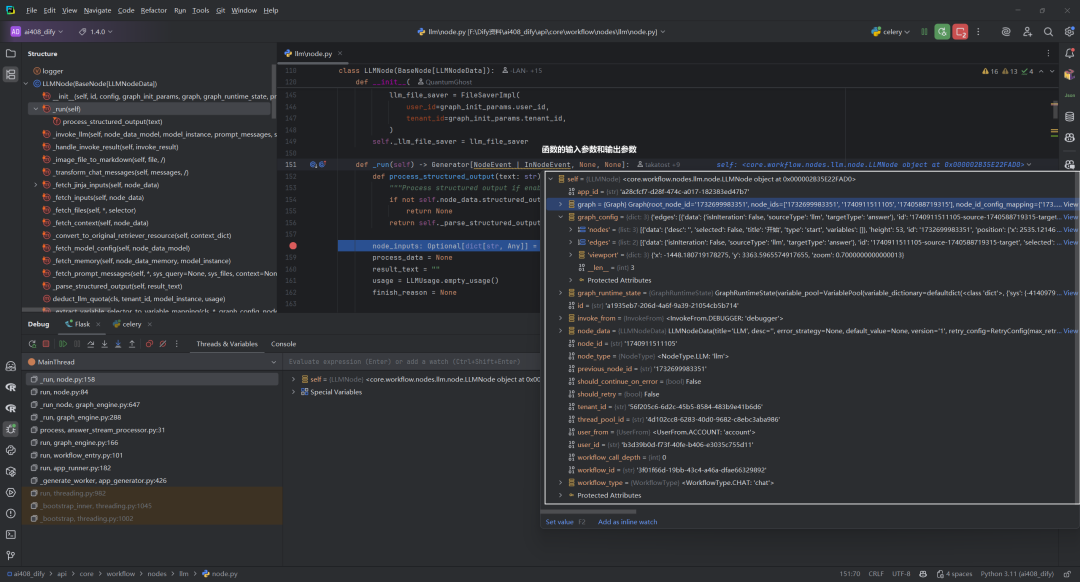
三.初始化阶段
1.process_structured_output函数
定义内部函数process_structured_output用于处理结构化输出。
defprocess_structured_output(text: str) -> Optional[dict[str, Any]]:
"""Process structured output if enabled"""
ifnot self.node_data.structured_output_enabled ornot self.node_data.structured_output:
returnNone
return self._parse_structured_output(text)
2.初始化变量
初始化变量(node_inputs、process_data、result_text等)。
node_inputs: Optional[dict[str, Any]] = None
process_data = None
result_text = ""
usage = LLMUsage.empty_usage()
finish_reason = None
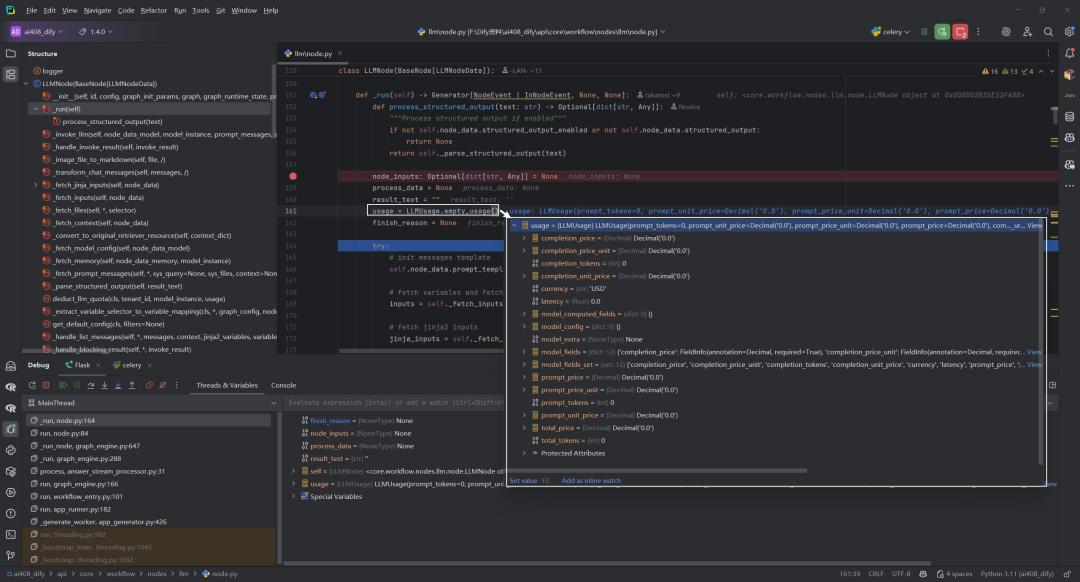
四.输入准备阶段
1.转换聊天消息模板:self._transform_chat_messages
该函数用于处理聊天消息模板,当消息使用Jinja2模板编辑模式时,将其jinja2_text内容复制到text字段,确保无论是补全模型模板还是聊天消息列表都能正确使用Jinja2模板内容。
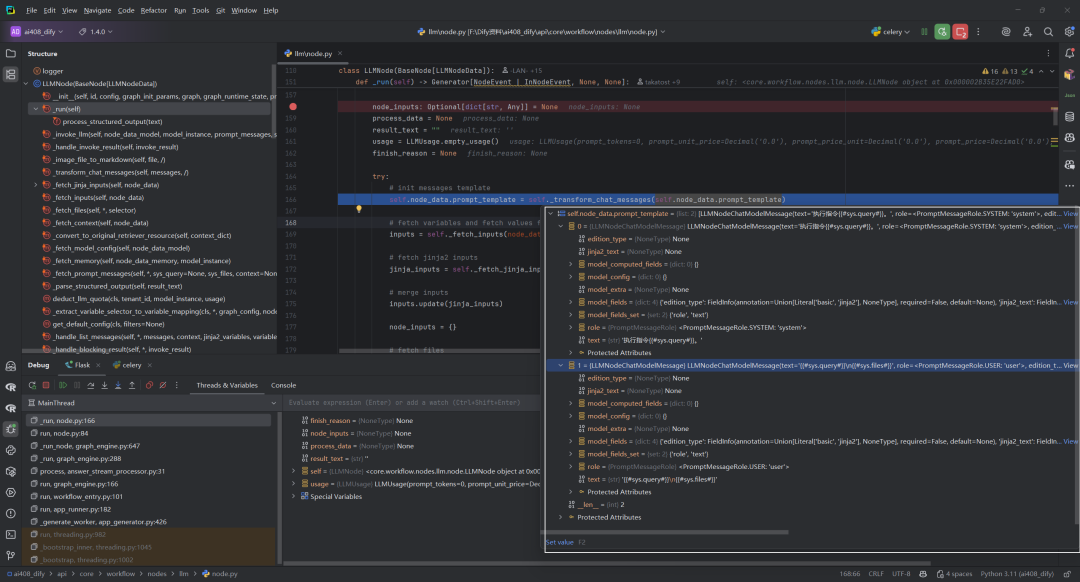
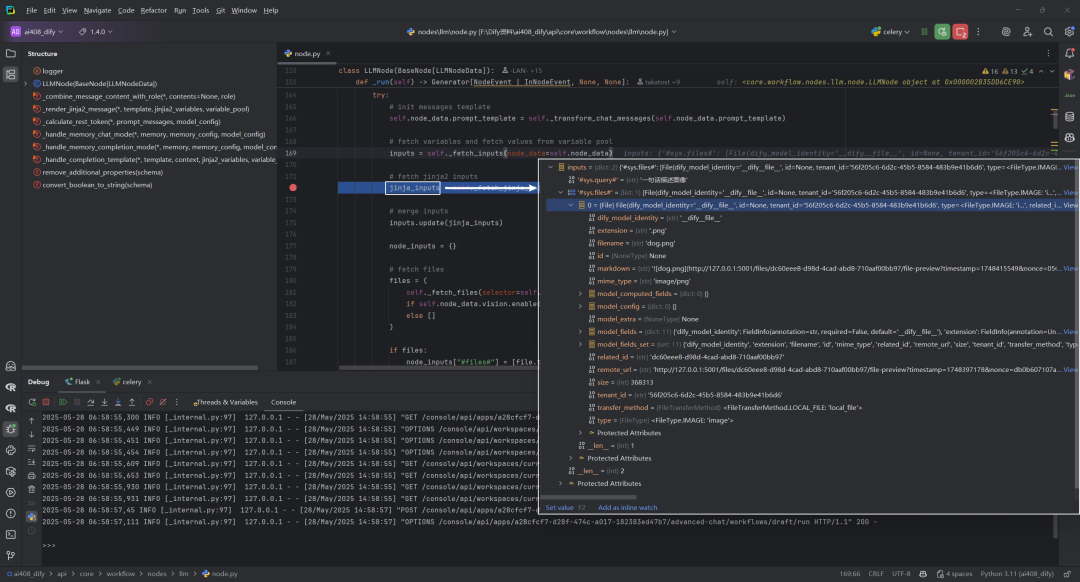
2.获取变量输入:self._fetch_inputs
_fetch_inputs 方法负责从变量池中提取 LLM 节点所需的输入变量。它解析 prompt 模板中的变量引用,从运行时变量池中获取对应值,并构建一个包含所有必要变量的字典返回给调用者。
-
分析不同类型的
prompt模板(列表形式或完成模型形式) -
提取模板中的变量选择器
-
从变量池中查找对应变量值
-
同时处理内存相关的查询模板变量
-
将所有变量整合到一个输入字典中
(1)输入内容
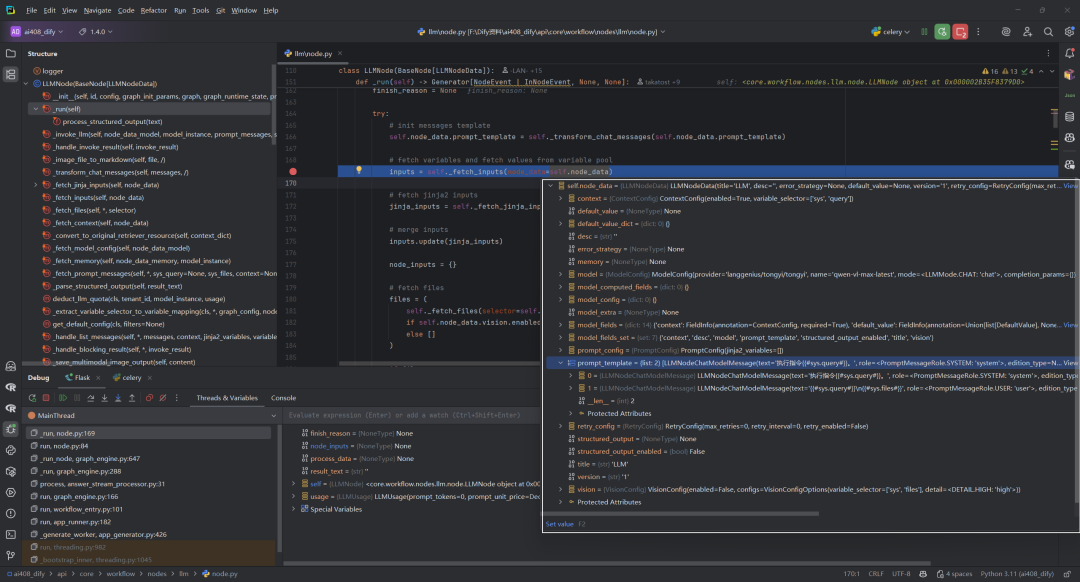
(2)输出内容
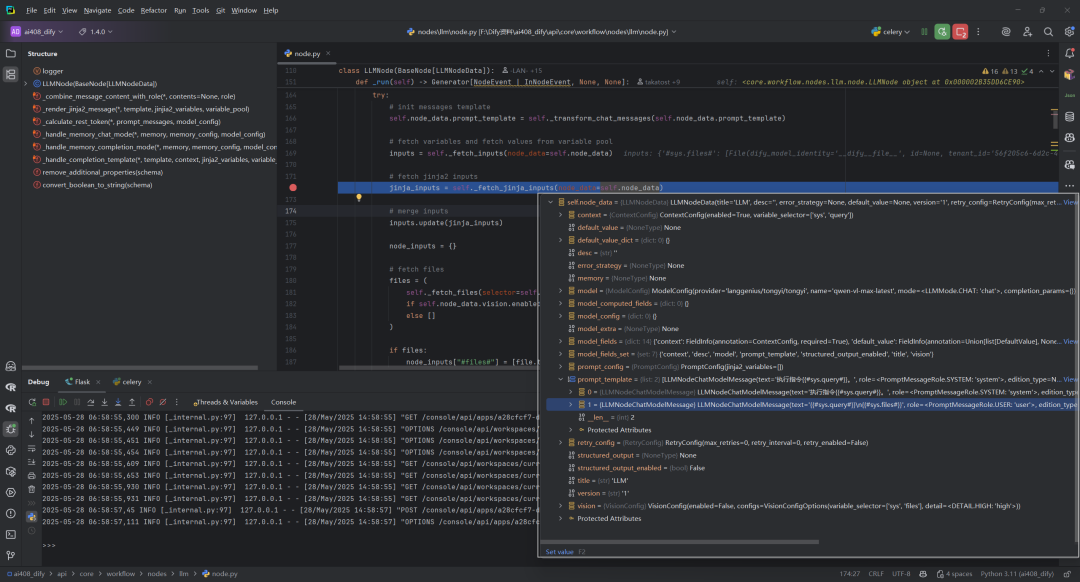
3.获取变量输入:self._fetch_jinja_inputs
该函数 _fetch_jinja_inputs 负责从LLM节点数据中提取和处理Jinja2模板变量,将各种类型的变量对象(如数组、对象、字符串等)转换为字符串格式,供Jinja2模板渲染使用,同时处理特殊结构如上下文数据,最终返回变量名到值的映射字典。
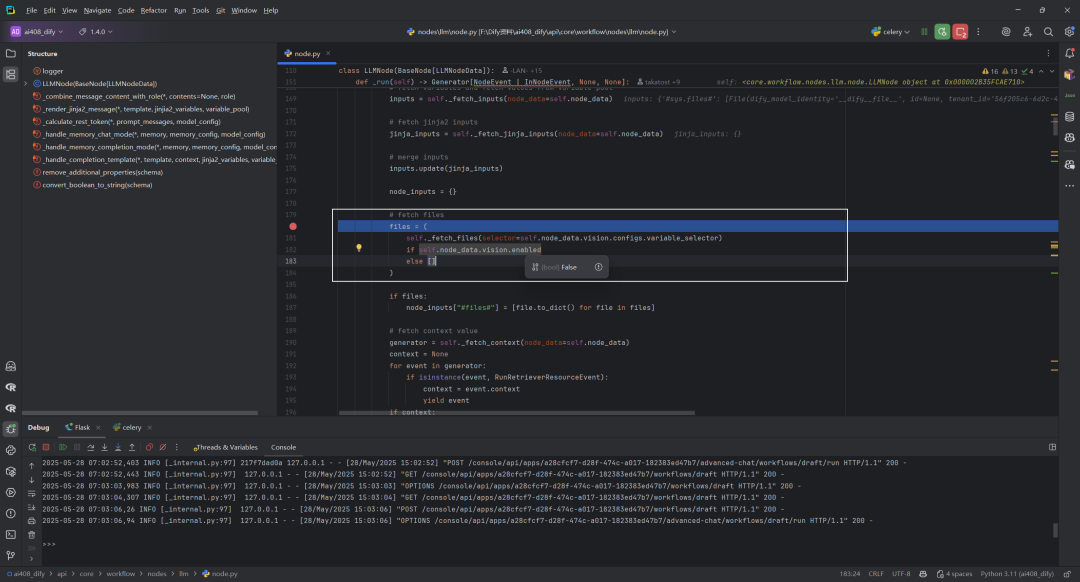
4.如果启用视觉功能,获取文件:self._fetch_files
函数_fetch_files根据提供的选择器从工作流变量池中检索文件资源,并根据变量类型返回相应格式的文件序列。它处理各种变量类型:FileSegment返回单文件列表,ArrayFileSegment直接返回文件数组,空值或ArrayAnySegment返回空列表,不支持的类型则抛出异常。
5.获取上下文:self._fetch_context
_fetch_context 函数从变量池中获取上下文数据,根据不同数据类型(字符串或数组)处理并转换成标准格式,最终生成包含检索资源和格式化上下文内容的事件。
遍历生成器产生的每个事件,检查事件是否为RunRetrieverResourceEvent类型。如果是,那么从事件中提取上下文内容,将事件传递给工作流引擎继续处理,添加上下文到节点输入。如果成功获取到上下文,将其添加到节点输入字典中,键名为"#context#"。
# fetch context value
generator = self._fetch_context(node_data=self.node_data)
context = None
for event in generator:
if isinstance(event, RunRetrieverResourceEvent):
context = event.context
yield event
if context:
node_inputs["#context#"] = context
(1)输入内容
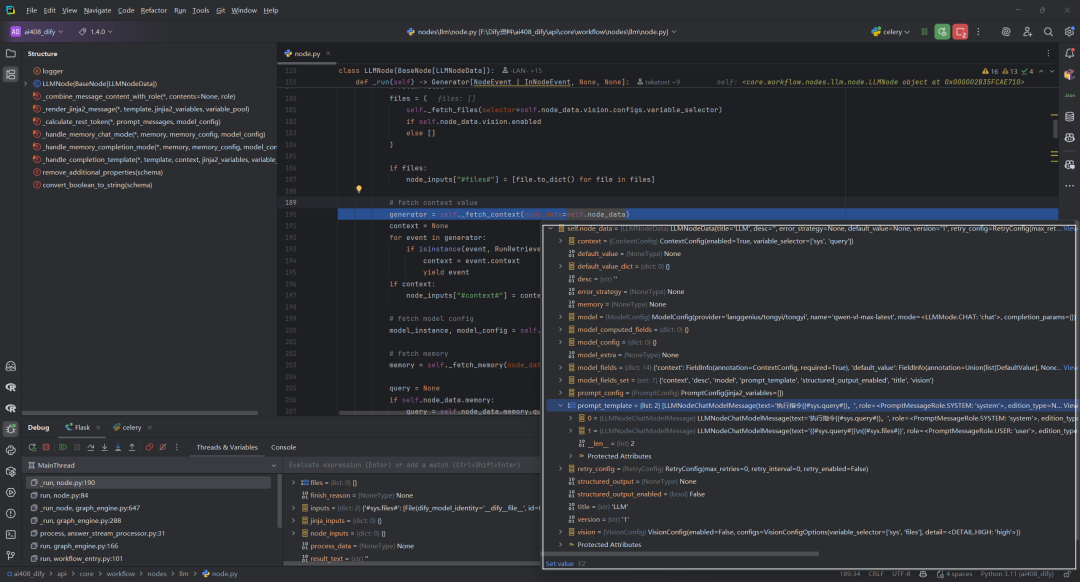
(2)输出内容
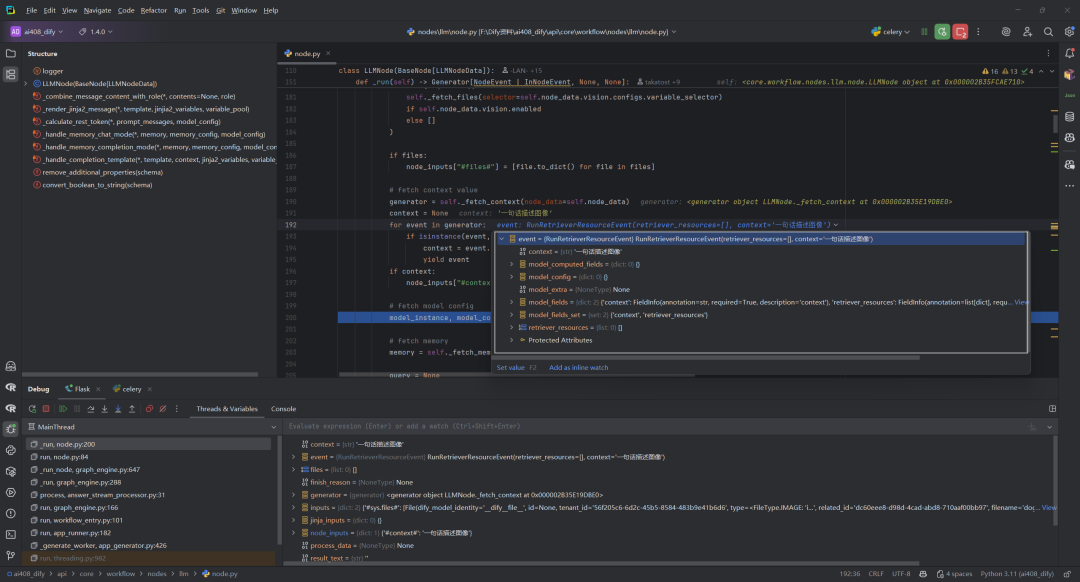
6.获取模型配置:self._fetch_model_config
_fetch_model_config 函数负责根据提供的模型配置信息获取模型实例和完整的模型配置实体。它执行以下关键操作:获取模型实例、验证模型状态(检查是否存在、凭证是否初始化、权限是否有效、配额是否超限)、处理模型参数(如停止词)、检查模型模式、处理结构化输出支持(如果启用),最终返回配置完成的模型实例和带凭证的完整模型配置实体,供后续 LLM 调用使用。
(1)输入内容
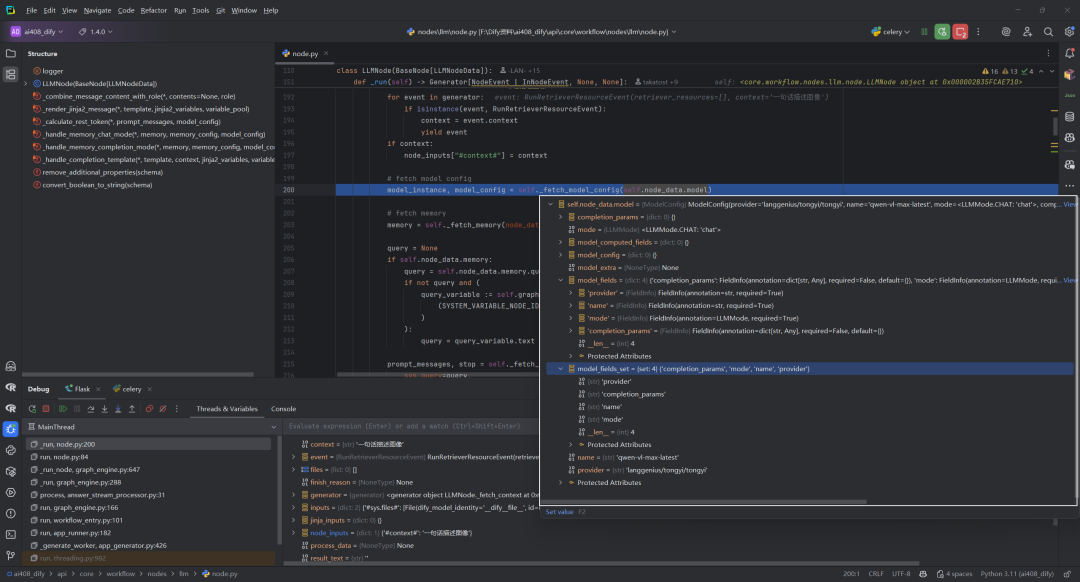
(2)输出内容
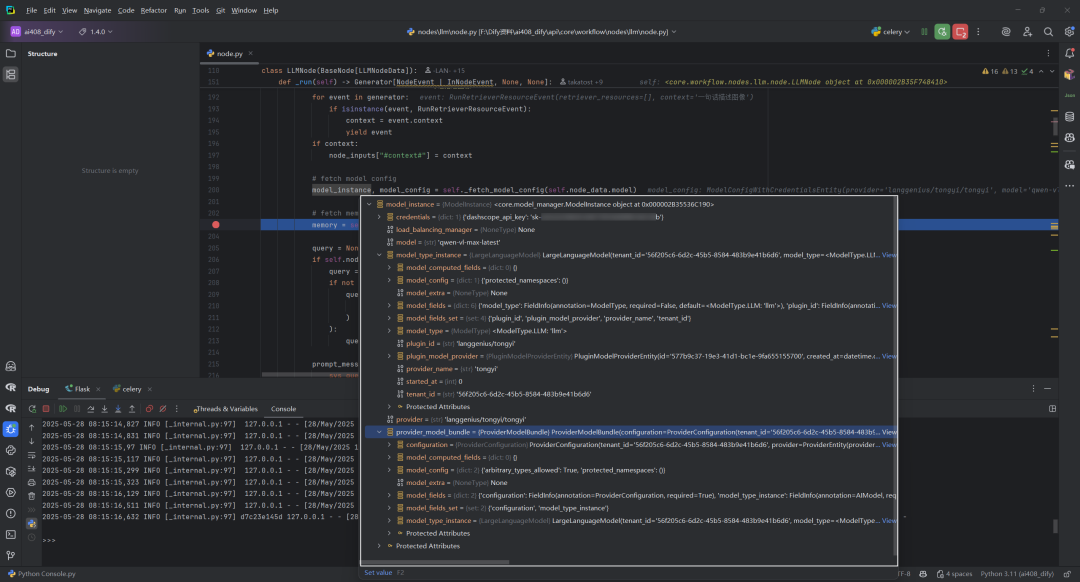
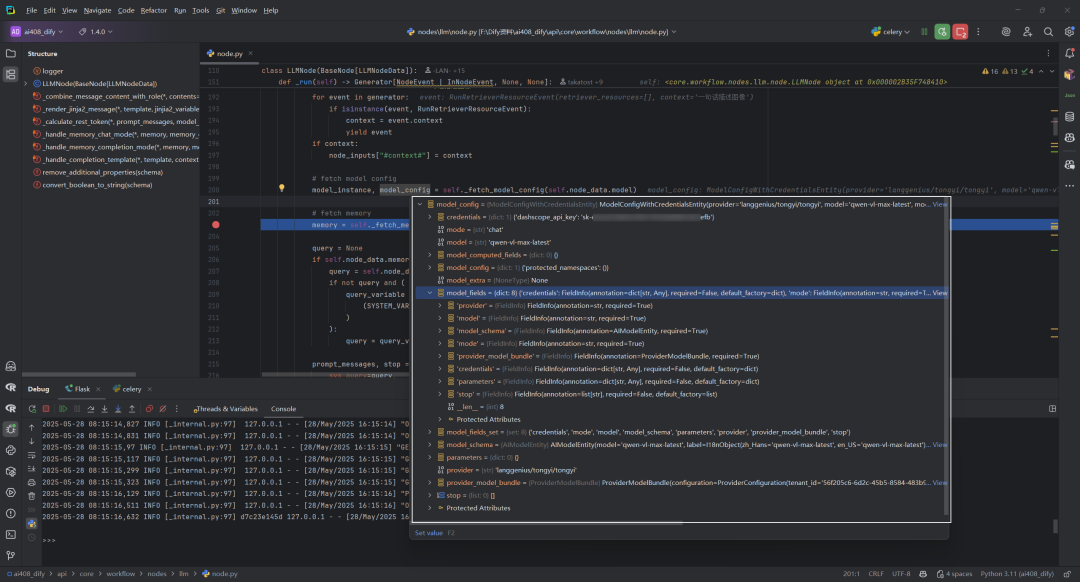
7.获取记忆上下文:self._fetch_memory
该函数负责获取对话记忆(conversation memory),工作流程:
-
首先检查是否配置了记忆功能
-
从变量池中获取会话ID
-
根据会话ID从数据库查询对应的对话记录
-
如果找到对话记录,创建一个
TokenBufferMemory实例 -
这个记忆实例会根据模型的上下文窗口大小和配置的参数来管理对话历史
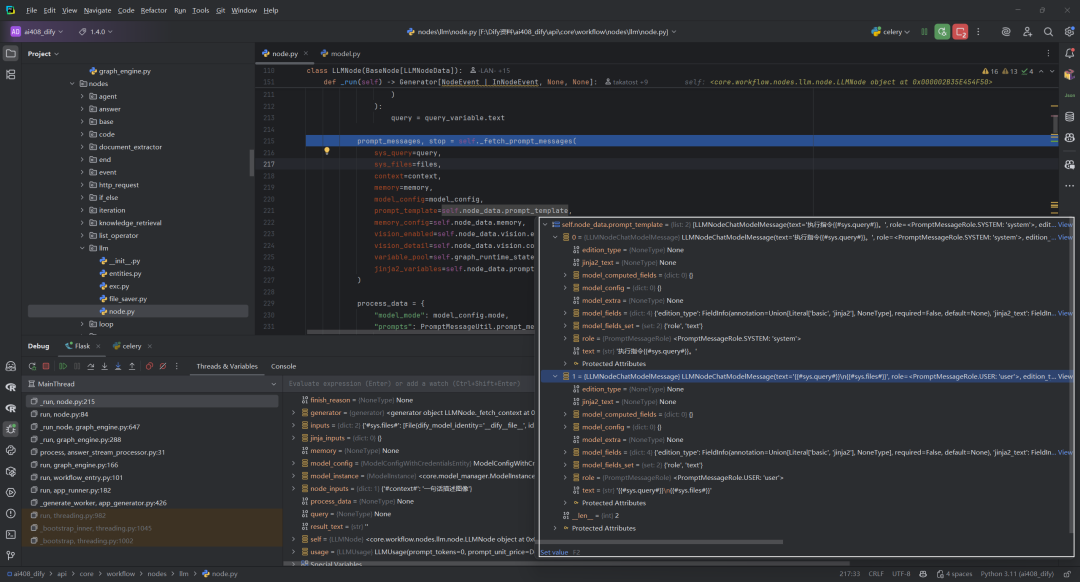
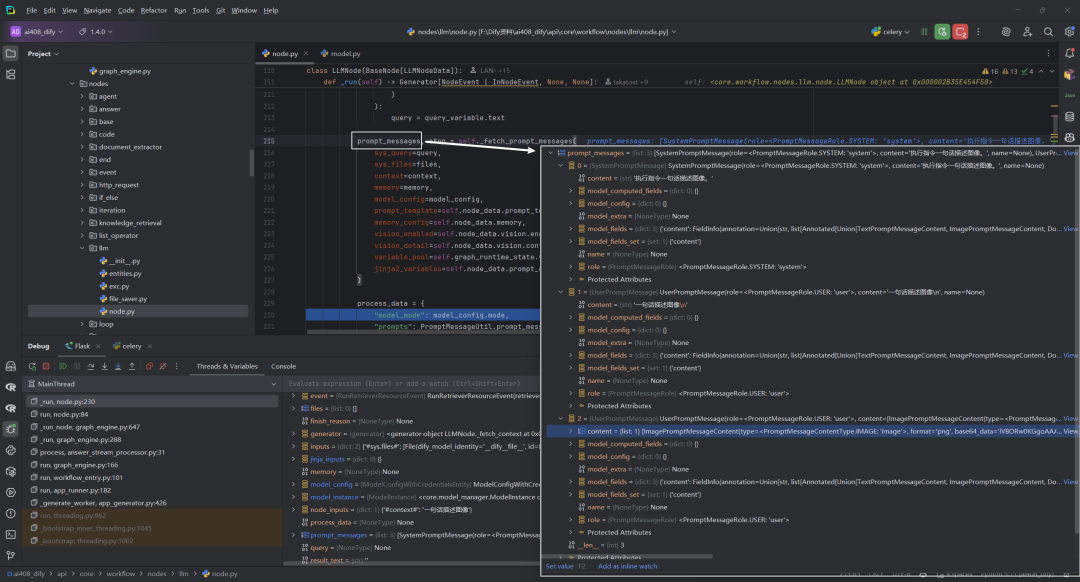
8.获取查询和构建提示消息:self._fetch_prompt_messages
_fetch_prompt_messages方法是工作流节点处理的关键环节,它将各种输入(用户查询、上下文、历史记忆、文件等)整合成结构化的提示,确保发送给LLM的消息能够产生预期的回复。对于支持多模态的模型,它还处理了图像等非文本内容的整合。
(1)参数详解
-
sys_query=query– 系统查询,来自记忆配置或系统变量中的当前用户查询 -
sys_files=files– 从变量池中提取的文件列表,用于多模态模型处理图像等内容 -
context=context– 上下文信息,通常是从知识库检索的相关内容 -
memory=memory– 对话记忆实例,管理对话历史 -
model_config=model_config– 模型配置信息,包含模型名称、提供者等 -
prompt_template=self.node_data.prompt_template– 提示模板,定义消息结构 -
memory_config=self.node_data.memory– 记忆配置,控制对话历史的使用方式 -
vision_enabled=self.node_data.vision.enabled– 是否启用视觉功能 -
vision_detail=self.node_data.vision.configs.detail– 图像处理的细节级别 -
variable_pool=self.graph_runtime_state.variable_pool– 变量池,用于模板变量替换 -
jinja2_variables=self.node_data.prompt_config.jinja2_variables– Jinja2模板变量
(2)返回值
该方法返回两个重要的结果:
-
prompt_messages– 构建好的提示消息序列,将发送给LLM模型 -
stop– 停止词列表,用于控制模型生成的终止条件
五.模型调用阶段
1.准备处理数据
process_data = {
"model_mode": model_config.mode,
"prompts": PromptMessageUtil.prompt_messages_to_prompt_for_saving(
model_mode=model_config.mode, prompt_messages=prompt_messages
),
"model_provider": model_config.provider,
"model_name": model_config.model,
}
具体的process_data数据,如下所示:
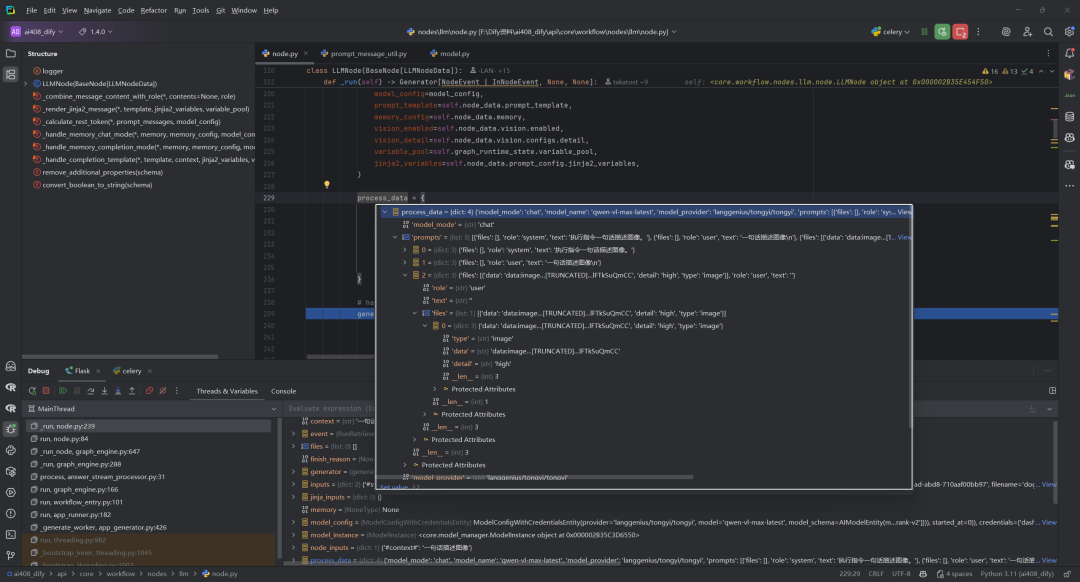
prompt_messages_to_prompt_for_saving函数将复杂的提示消息对象序列(prompt_messages)转换为标准化的字典列表格式,以便于存储,同时根据模型模式(聊天或非聊天)处理不同类型的内容(文本、图像、音频)和角色(用户、助手、系统、工具),并对大型二进制数据进行截断处理。
2.self._invoke_llm
这段代码是LLM节点执行过程中的核心部分,负责调用大语言模型并处理结果,这是工作流节点与LLM模型交互的关键环节,负责转发请求并处理响应。
# handle invoke result
generator = self._invoke_llm(
node_data_model=self.node_data.model,
model_instance=model_instance,
prompt_messages=prompt_messages,
stop=stop,
)
这个函数负责实际调用大语言模型,并将调用结果转换为节点事件流。具体步骤:
(1)它接收4个关键参数:
-
node_data_model: 模型配置信息(包含提供商、模型名称、参数设置等) -
model_instance: 已初始化的模型实例对象 -
prompt_messages: 处理好的提示消息序列(包含系统消息、用户消息等) -
stop: 可选的停止词列表,用于控制模型生成结果
(2)在_invoke_llm方法内部
-
首先关闭数据库会话(
db.session.close())以避免资源冲突 -
然后调用模型实例的
invoke_llm方法发送请求到实际的LLM服务 -
设置
stream=True启用流式响应 -
最后将调用结果传递给
_handle_invoke_result方法进行处理
(3)返回值是一个生成器,它会产生NodeEvent类型的事件,用于:
-
处理模型的流式输出(
RunStreamChunkEvent) -
记录模型调用完成事件(
ModelInvokeCompletedEvent) -
包含生成文本、使用情况统计和完成原因等信息
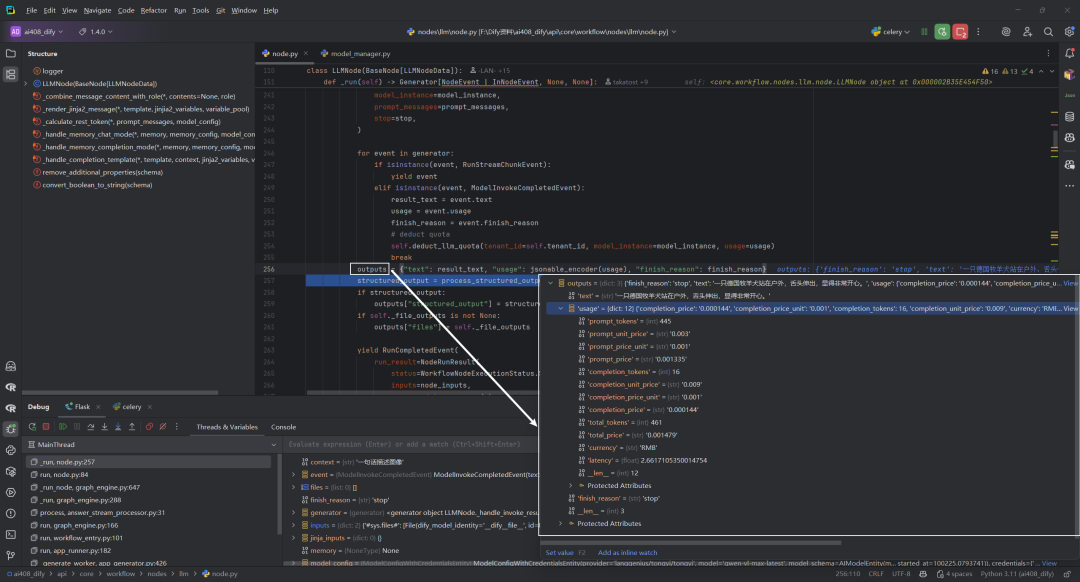
3.处理流式输出和完成事件
这段代码是处理LLM(大型语言模型)调用过程中生成的事件流的关键部分。
for event in generator:
if isinstance(event, RunStreamChunkEvent):
yield event
elif isinstance(event, ModelInvokeCompletedEvent):
result_text = event.text
usage = event.usage
finish_reason = event.finish_reason
# deduct quota
self.deduct_llm_quota(tenant_id=self.tenant_id, model_instance=model_instance, usage=usage)
break
这个循环处理从_invoke_llm方法返回的事件生成器中的每个事件:
(1)对于RunStreamChunkEvent类型事件
-
这表示LLM正在流式(streaming)返回生成的文本片段
-
通过
yield event将这些事件直接传递给上游调用者 -
这允许应用程序实时显示LLM正在生成的内容,无需等待完整响应
(2)对于ModelInvokeCompletedEvent类型事件
-
这表示LLM已完成整个生成过程
-
从事件中提取三个关键信息:
-
result_text:完整的生成文本 -
usage:资源使用情况(如token数量) -
finish_reason:模型停止生成的原因 -
调用
deduct_llm_quota方法根据使用情况扣除租户的配额 -
使用
break退出循环,因为已收到完整结果
这种实现支持两种模式:流式输出和阻塞式输出,使系统能高效处理LLM响应,同时确保正确计费和资源管理。
4.deduct_llm_quota
源码位置:源码位置:dify\api\core\workflow\nodes\llm\node.py
deduct_llm_quota 是一个类方法,用于在使用LLM服务后扣减系统配额。这个方法实现了灵活的配额管理机制,根据不同计量单位(tokens或credits)计算并更新配额使用情况。
函数参数包括tenant_id租户ID、model_instance模型实例、usageLLM使用情况统计。
@classmethod
defdeduct_llm_quota(cls, tenant_id: str, model_instance: ModelInstance, usage: LLMUsage) -> None:
provider_model_bundle = model_instance.provider_model_bundle
provider_configuration = provider_model_bundle.configuration
if provider_configuration.using_provider_type != ProviderType.SYSTEM:
return
system_configuration = provider_configuration.system_configuration
quota_unit = None
for quota_configuration in system_configuration.quota_configurations:
if quota_configuration.quota_type == system_configuration.current_quota_type:
quota_unit = quota_configuration.quota_unit
if quota_configuration.quota_limit == -1:
return
break
used_quota = None
if quota_unit:
if quota_unit == QuotaUnit.TOKENS:
used_quota = usage.total_tokens
elif quota_unit == QuotaUnit.CREDITS:
used_quota = dify_config.get_model_credits(model_instance.model)
else:
used_quota = 1
if used_quota isnotNoneand system_configuration.current_quota_type isnotNone:
db.session.query(Provider).filter(
Provider.tenant_id == tenant_id,
# TODO: Use provider name with prefix after the data migration.
Provider.provider_name == ModelProviderID(model_instance.provider).provider_name,
Provider.provider_type == ProviderType.SYSTEM.value,
Provider.quota_type == system_configuration.current_quota_type.value,
Provider.quota_limit > Provider.quota_used,
).update(
{
"quota_used": Provider.quota_used + used_quota,
"last_used": datetime.now(tz=UTC).replace(tzinfo=None),
}
)
db.session.commit()
(1)获取模型配置信息
provider_model_bundle = model_instance.provider_model_bundle
provider_configuration = provider_model_bundle.configuration
(2)验证提供商类型
如果不是系统提供商(SYSTEM),直接返回,不扣减配额。
(3)配额单位确定
-
遍历系统配置中的配额配置项
-
找到与当前配额类型匹配的配置
-
获取对应的配额单位(
quota_unit) -
如果配额限制为-1(无限制),直接返回
(4)计算使用量
根据配额单位类型计算使用量:
-
QuotaUnit.TOKENS: 使用tokens总数 -
QuotaUnit.CREDITS: 获取模型积分 -
其它情况: 默认为1
(5)更新数据库记录
条件查询Provider表中符合条件的记录:
-
匹配租户
ID -
匹配提供商名称
-
提供商类型为
SYSTEM -
配额类型匹配
-
剩余配额充足(
quota_limit>quota_used) -
更新记录:增加已使用配额;更新最后使用时间
-
提交事务
六.输出处理阶段
这段代码是LLMNode类的_run方法中处理LLM执行结果并生成成功完成事件的关键部分。这部分代码确保了LLM节点执行的所有结果(文本、结构化数据、文件)都被正确封装并传递给工作流引擎的下一步处理。
structured_output = process_structured_output(result_text)
if structured_output:
outputs["structured_output"] = structured_output
if self._file_outputs isnotNone:
outputs["files"] = self._file_outputs
yield RunCompletedEvent(
run_result=NodeRunResult(
status=WorkflowNodeExecutionStatus.SUCCEEDED,
inputs=node_inputs,
process_data=process_data,
outputs=outputs,
metadata={
NodeRunMetadataKey.TOTAL_TOKENS: usage.total_tokens,
NodeRunMetadataKey.TOTAL_PRICE: usage.total_price,
NodeRunMetadataKey.CURRENCY: usage.currency,
},
llm_usage=usage,
)
)
1.结构化输出处理
这段代码调用process_structured_output函数尝试将LLM返回的文本解析为结构化JSON数据。如果成功解析(即模型输出了有效的JSON结构),则将解析结果添加到outputs字典中。
structured_output = process_structured_output(result_text)
if structured_output:
outputs["structured_output"] = structured_output
2.文件输出处理
如果LLM生成了多模态内容(如图像),这些内容已被保存为文件,这段代码将这些文件添加到输出中。
if self._file_outputs isnotNone:
outputs["files"] = self._file_outputs
3.生成完成事件
创建并yield一个RunCompletedEvent事件,表示节点执行成功完成。
yield RunCompletedEvent(
run_result=NodeRunResult(...)
)
这个事件包含了一个NodeRunResult对象,其中包括:
-
status:标记为成功状态 -
inputs:节点的输入数据 -
process_data:处理数据(如使用的模型、提示等) -
outputs:所有输出数据(文本、结构化输出、文件等) -
metadata:包含令牌使用量、价格和货币单位等元数据 -
llm_usage:详细的LLM使用统计信息
参考文献
[0] Dify工作流中的LLM节点:_run方法:https://z0yrmerhgi8.feishu.cn/wiki/BiZgwhS3ciFYPakARITcogVtn1g
[1] https://github.com/langgenius/dify/releases/tag/1.4.0
[2] https://ai.google.dev/
[3] https://aistudio.google.com/
知识星球服务内容:Dify源码剖析及答疑,Dify对话系统源码,NLP电子书籍报告下载,公众号所有付费资料。加微信buxingtianxia21进NLP工程化资料群。
(文:NLP工程化)