
具有超能力的开源Markdown,用AI生成曲线图、PPT等多种样式再也不是问题。

Markdown使用广泛但样式有限,需依赖开源工具改进。Quarkdown作为基于Markdown的轻量级标记语言,支持函数调用、变量等强大功能,提高文档创作效率和多样性。
Markdown使用广泛但样式有限,需依赖开源工具改进。Quarkdown作为基于Markdown的轻量级标记语言,支持函数调用、变量等强大功能,提高文档创作效率和多样性。
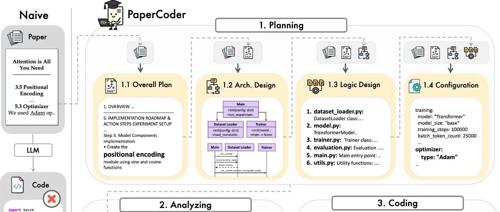
Paper2Code 是一个开源的多智能体 LLM 框架,能将机器学习论文自动转化为功能代码仓库。它通过规划、分析和生成三阶段流程来实现。

MCP由Anthropic公司推出,作为标准化连接框架,允许大语言模型访问和操作本地及远程数据。通过MCP,AI应用可以与浏览器、地图导航等工具集成,实现从‘出主意’到‘帮干事’的飞跃。

字节跳动开源多模态模型BAGEL,支持图像生成、修改及动态变化理解。具备聊天、生成图片、编辑图片、风格转换和导航等能力。

PaddleOCR 3.0发布全面适配飞桨框架,提升文字识别精度并新增国产硬件支持。PP-StructureV3在文档解析方面表现突出,精度和专精能力领先众多方案。PaddleOCR系列解决方案为AI大模型文档处理提供了强有力的支持。
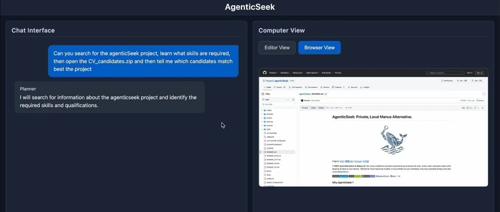
AgenticSeek 是一个完全本地化的 AI 助手项目,替代 Manus AI。它具有智能网页浏览、自主编码等功能,并能自动分配最佳代理完成任务。
今天推荐的AI-Media2Doc开源项目能将音视频转换为多种文档形式,支持AI问答和思维导图导出等功能。MIT协议下可自由商用。

苹果开发的高效视觉语言模型FastVLM采用新型混合视觉编码器FastViTHD,实现高分辨率图像处理速度提升3.2倍的同时保持精度。

深度研究报告基于搜索整理信息,改变用户习惯。AI搜索提高效率和准确性,未来可能使人变得更懒或不爱动脑。字节发布的DeerFlow结合大语言模型和多种工具实现高效研究自动化。

字节开源的Seed1.5-VL是视觉-语言多模态大模型,支持多种复杂任务如盲人判断红绿灯和智能导盲。其包含5.32亿参数视觉编码器和200亿激活参数混合专家大语言模型,已在多个公开基准中表现出色。