

今天给大家推荐的是字节刚开源的多模态模型,BAGEL。
理解和生成都是多模态。
这里普及一个知识,多模态模型理解图片,也就是把图片当做提示词给了模型,生成的时候同理。
BAGEL的功能很多,不只是生成一张简单的图片,还可以修改图片。
最牛的是,BAGEL不只理解了图片,还能想象图片的动态变化。

扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)

项目简介
BAGEL 是字节开源的统一多模态模型,可在任意场景微调、蒸馏与部署。它具备聊天、生成、编辑等多种能力,采用 MoT 架构,在大规模交错多模态数据上训练。性能超越众多开源模型,在多模态理解、文本到图像生成等任务上表现出色,还能进行风格迁移、世界导航等复杂操作,为多模态领域提供了强大的开源解决方案。
DEMO
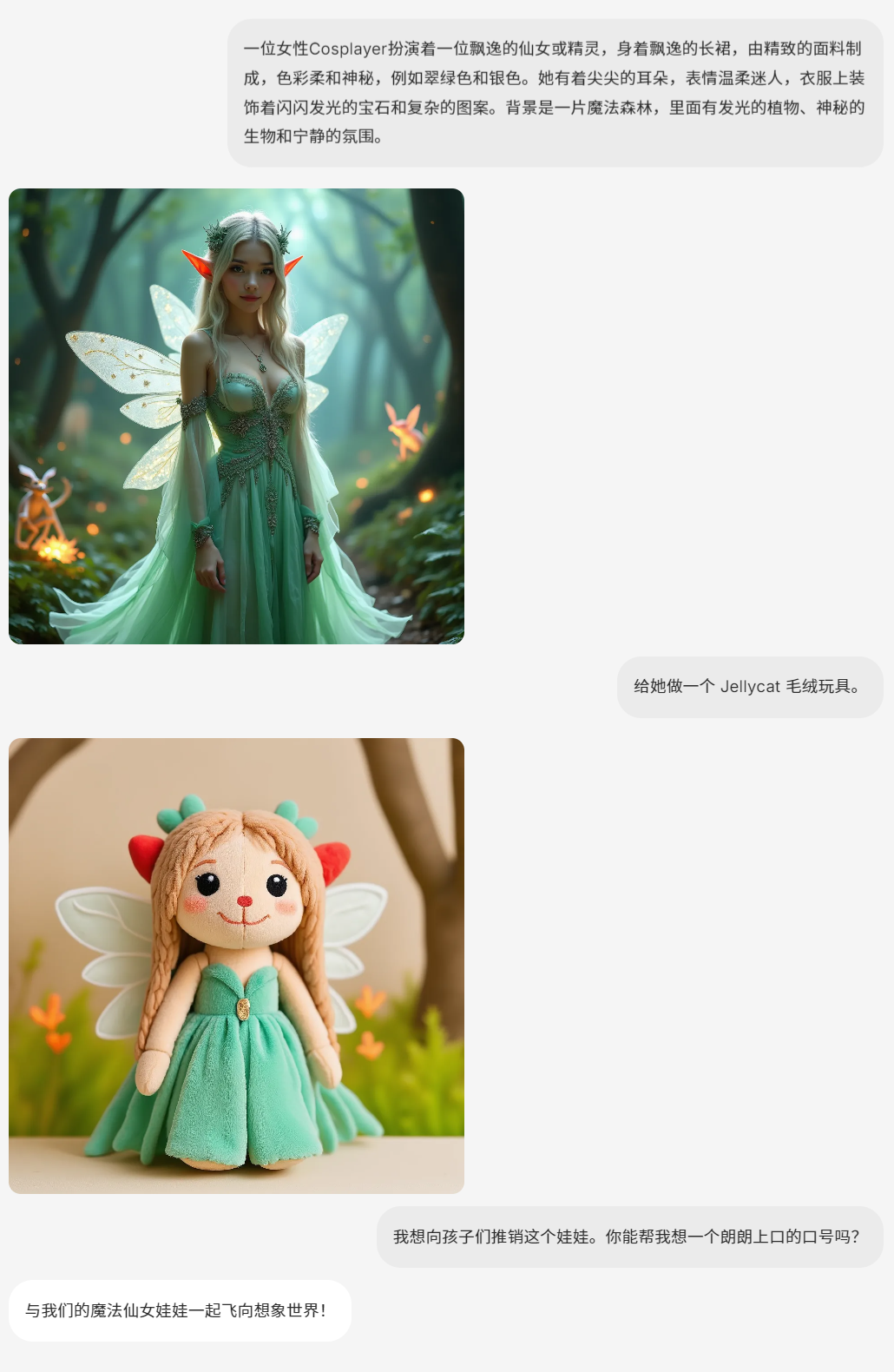
· 聊天
BAGEL 可以处理图像和文本的混合格式输入和输出。

· 生成图片
生成高保真、逼真的图像、视频帧或交错的图文内容。


· 编辑图片
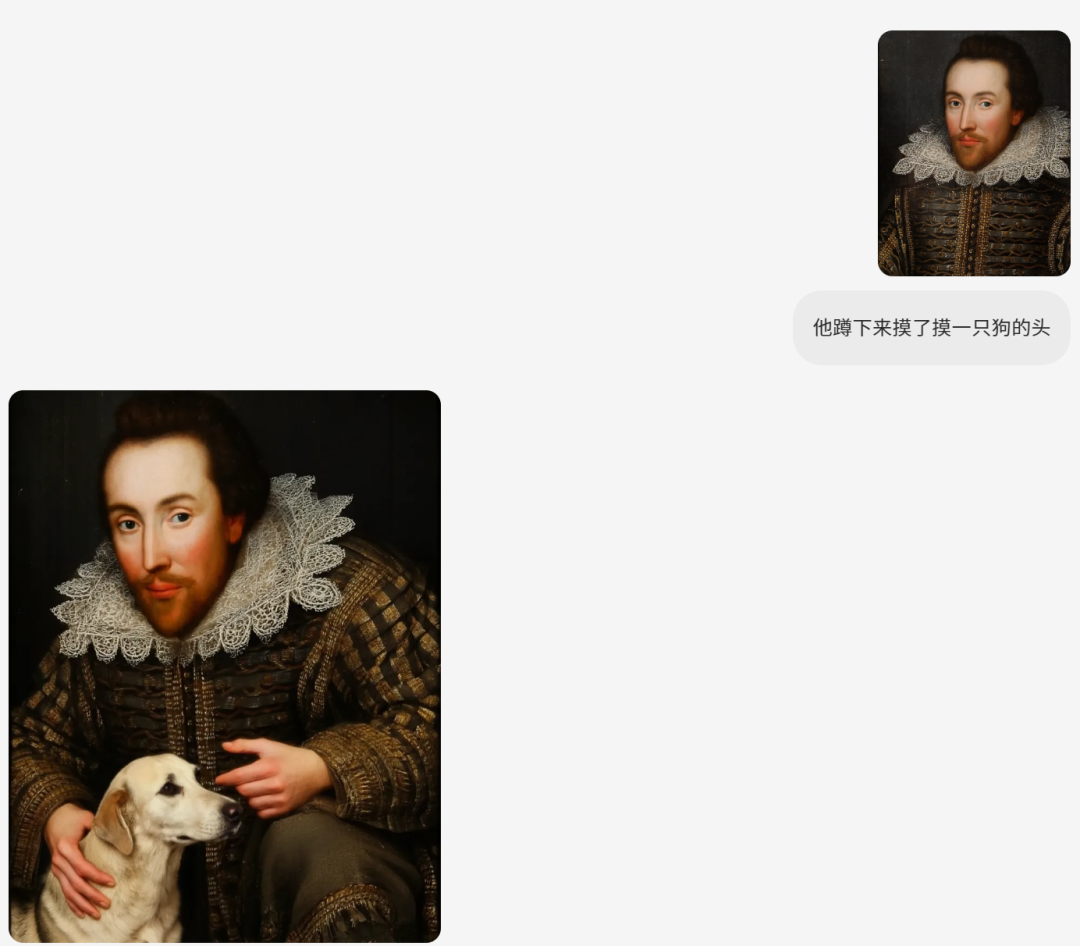
· 风格转换
将图像从一种风格转换为另一种风格,甚至可以将其转换为完全不同的风格。
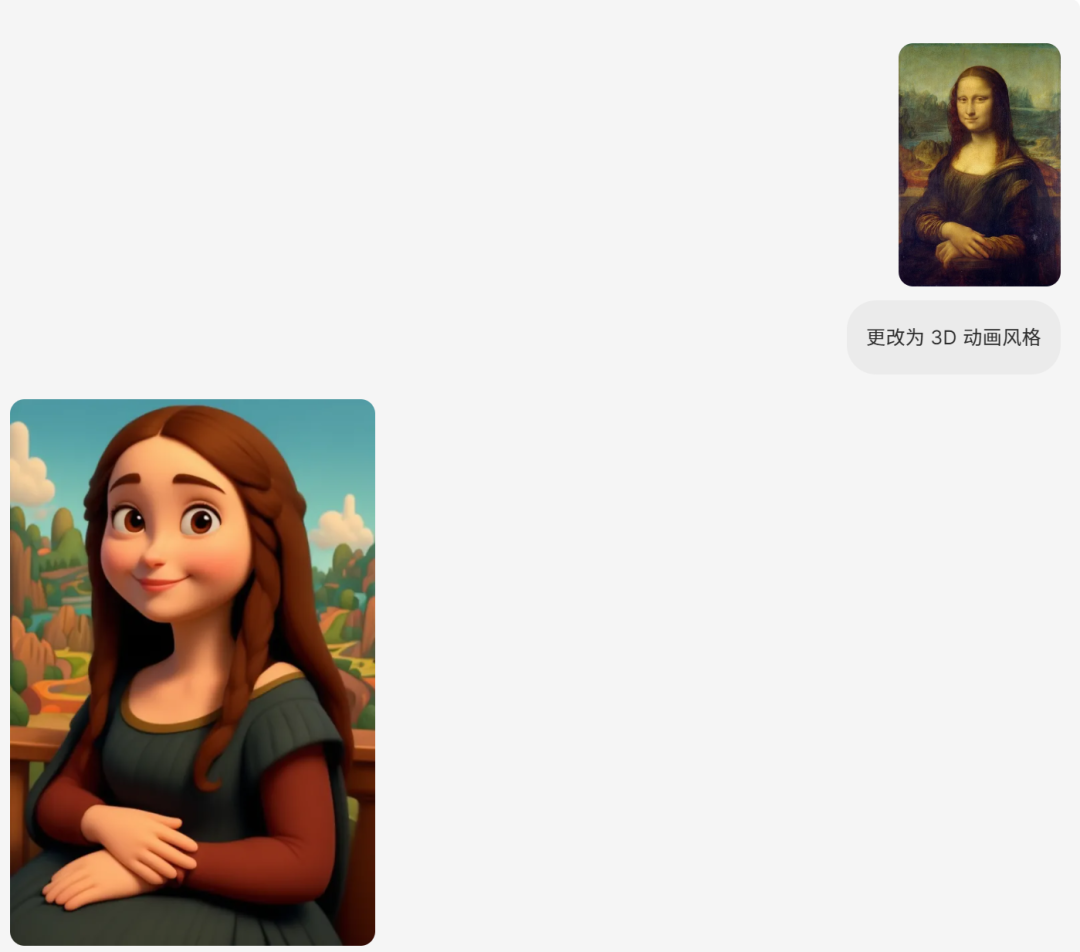
· 导航
BAGEL 可以有效地从现实世界中提取导航知识,使其能够导航各种环境,包括科幻世界、艺术绘画以及具有不同旋转或视角的环境。

· 思维

技术特点
-
独特架构设计:采用混合变换器专家(MoT)架构,通过两个独立编码器,分别捕捉图像像素级和语义级特征,打破传统 “编码器 – 解码器” 瓶颈,实现理解与生成模块语义无损交互,让理解专家与生成专家共享自注意力层,促进复杂推理能力涌现。
-
海量交错数据训练:在来自语言、图像、视频和网络数据的数万亿交错多模态标记上预训练,数据含 500M 图像 – 文本对、45M 交错视频序列等。数据多样且采用动态配比,生成数据采样比例高,加速 MSE 损失收敛,赋予模型强大泛化力与世界知识。
-
创新双编码器协同:ViT+VAE 双编码器设计协同运作,ViT 编码器基于 SigLIP2 初始化,支持高分辨率输入,聚焦高层次语义理解;VAE 编码器源于 FLUX 预训练模型,提取精细像素特征助力高质量生成,实验表明能提升智能编辑得分 。
项目链接
https://github.com/ByteDance-Seed/Bagel
关注「开源AI项目落地」公众号
(文:开源AI项目落地)