

PaddleOCR自发布以来凭借学术前沿算法和产业落地实践,受到了产学研各方的喜爱,并被广泛应用于众多知名开源项目,如Umi-OCR、OmniParser、MinerU、RAGFlow等,已成为广大开发者心中的开源OCR领域的首选工具。
2025年5月20日,飞桨团队发布PaddleOCR 3.0并对外开源,全面适配飞桨框架3.0正式版,进一步提升文字识别精度,支持多文字类型识别和手写体识别,满足大模型应用对复杂文档高精度解析的旺盛需求,结合文心大模型4.5 Turbo显著提升关键信息抽取精度,并新增对昆仑芯、昇腾等国产硬件的支持。


全场景文字识别模型PP-OCRv5
|单模型支持5种文字类型和复杂手写体识别
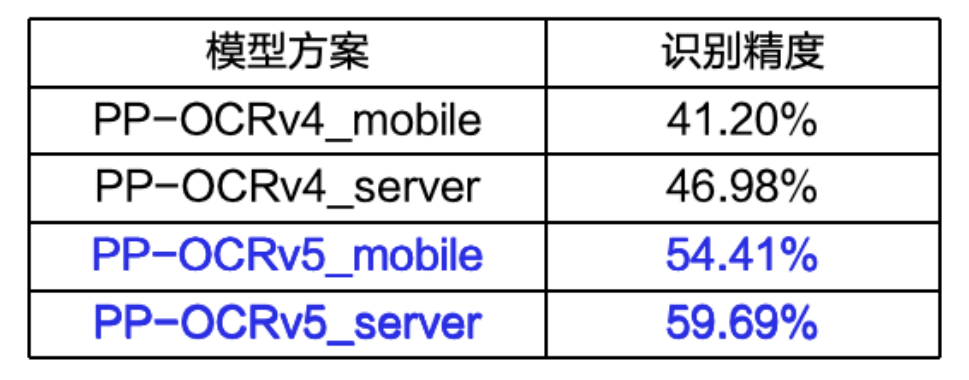
|整体识别精度相比上一代提升13个百分点
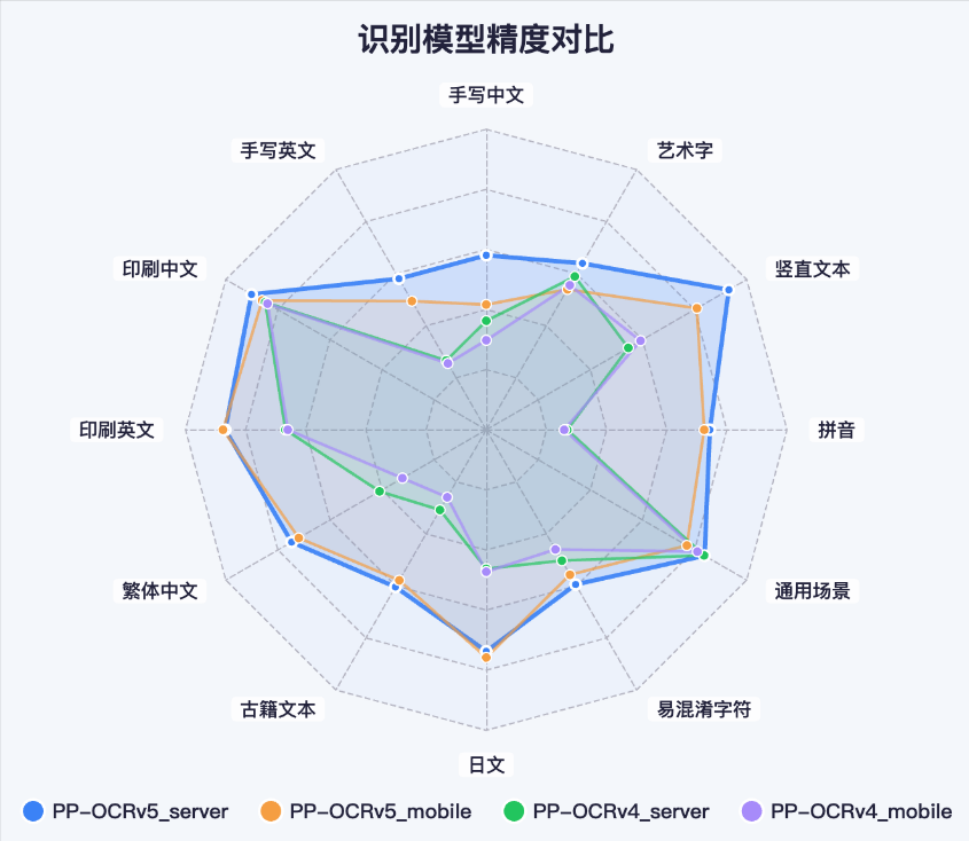
PP-OCRv5是面向大模型时代多模态需求、聚焦多语言多场景识别的轻量级端到端文字识别方案。该方案实现以单一模型高效、精准地支持简体中文、繁体中文、中文拼音、英文、日文五种文字类型,以及手写、竖版、拼音、生僻字等复杂文本场景的识别。
· 支持复杂手写体识别。手写体混合印刷体的识别是多个应用场景的刚需,例如:教育行业的试卷作业批改场景、医疗行业的病历数字化场景、法律行业的合同笔录数字化场景等。PP-OCRv5支持中英日手写体识别,对复杂连笔、非规范字迹识别精度有显著提升。
· 整体识别达到SOTA精度。在业务多场景高难度文字识别评估集上,PP-OCRv5的识别精度达到当前最优,比上一版本PP-OCRv4,识别精度提升13个百分点!
欢迎开发者到飞桨星河社区体验PP-OCRv5的能力:https://aistudio.baidu.com/community/app/91660/webUI

通用文档解析方案PP-StructureV3
|支持多场景、多版式PDF高精度解析
|在公开评测集中领先众多开源和闭源方案
文档解析是一种从文档图像中提取结构化信息的技术,主要用于将复杂的文档版面转换为结构化数据,这项技术在AI大模型文档处理领域有广泛的应用。通用文档解析方案PP-StructureV3在上一代的基础上,强化了版面区域检测、表格识别、公式识别的能力,增加了图表理解和多栏阅读顺序的恢复能力,并可以将结果转换 Markdown和JSON格式。
PP-StructureV3的主要优势有:
· 精度高:支持多场景、多版式PDF高精度解析,在OmniDocBench基准测试中领先众多开源和闭源方案。
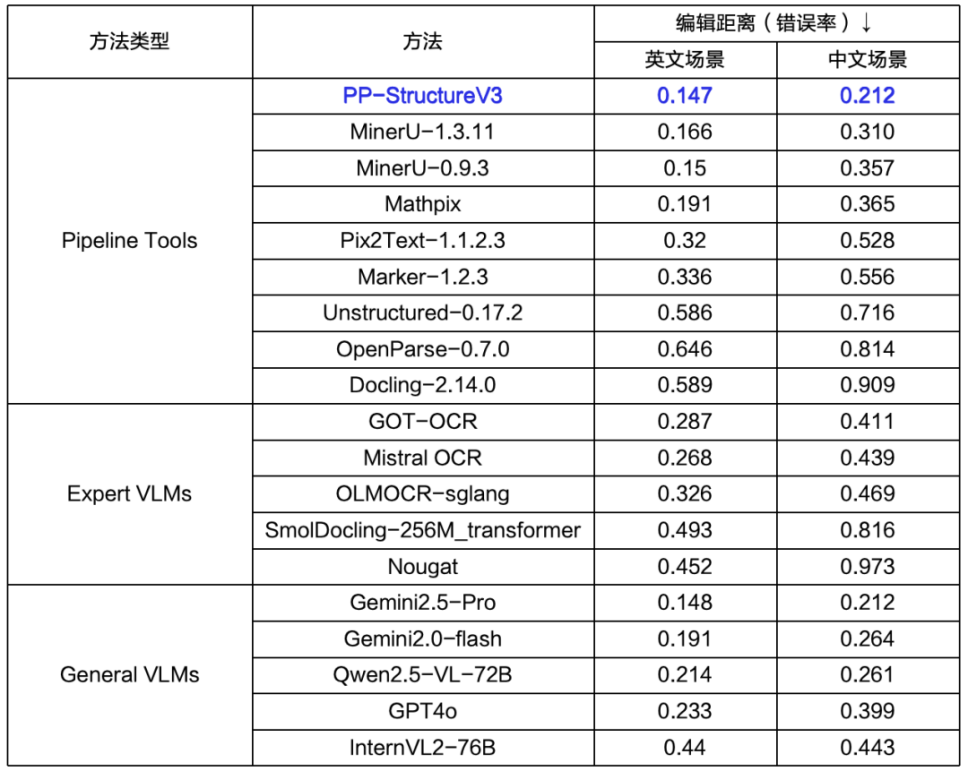
注:以上精度信息除PP-StructureV3和MinerU-1.3.11为自测精度外,均来自OmniDocBench
· 多项专精能力: 除了在OmniDocBench上的精度指标更高之外,PP-StructureV3还有多项专精能力,如:印章识别、图表转表格、嵌套公式/图片的表格识别、竖排文本解析及复杂表格结构分析等——这些能力是很多重要场景AI应用落地的刚需。
欢迎开发者到飞桨星河社区体验PP-StructureV3的能力:
https://aistudio.baidu.com/community/app/518494/webUI

智能文档理解方案PP-ChatOCRv4
|原生支持文心大模型4.5 Turbo
|关键信息抽取精度相比上一代提升15个百分点
PP-ChatOCR系列是飞桨特色智能文档理解类解决方案,融合大模型和小模型的优势能力,达到通用场景下的文档图像关键信息抽取效果,支持身份证、银行卡、企业合同等多种场景的关键信息提取。PP-ChatOCRv4在上一代基础上,结合文心大模型4.5 Turbo强大的理解优势,并支持离线使用多模态文档理解模型PP-DocBee2,实现了更高效的文本图像信息抽取,一站式解决版面分析、生僻字、多页pdf、表格、印章识别等常见的复杂文档信息抽取难点问题。
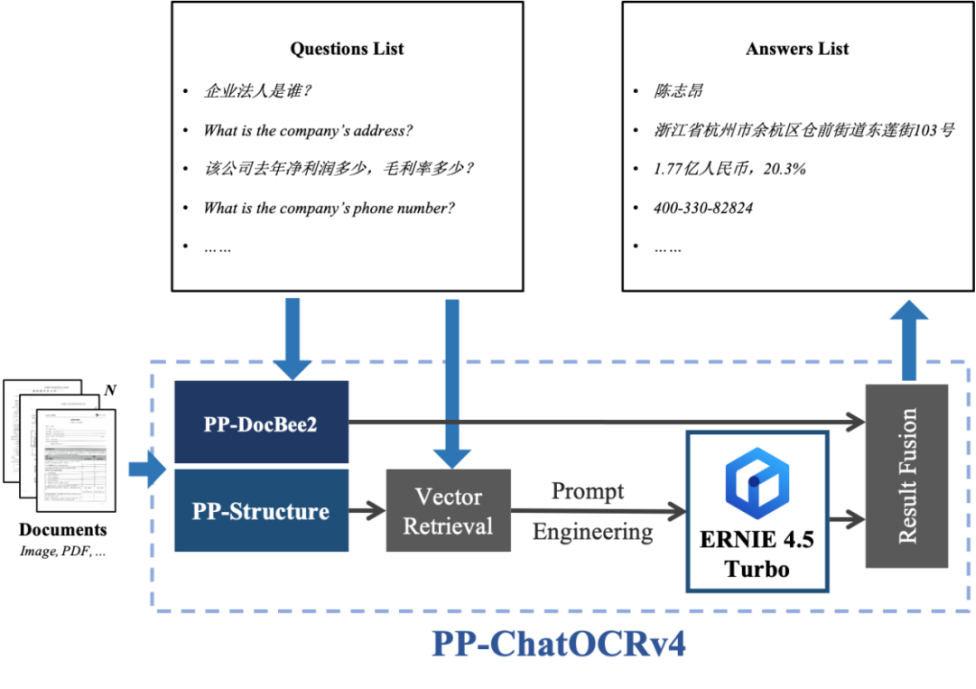
PP-ChatOCRv4的主要优势有:
· 关键信息抽取精度相比上一代提升15个百分点,效果业界领先。在内部业务中文场景评估集(覆盖印刷文字、表格、印章、图表等)中的准确率如下表所示:
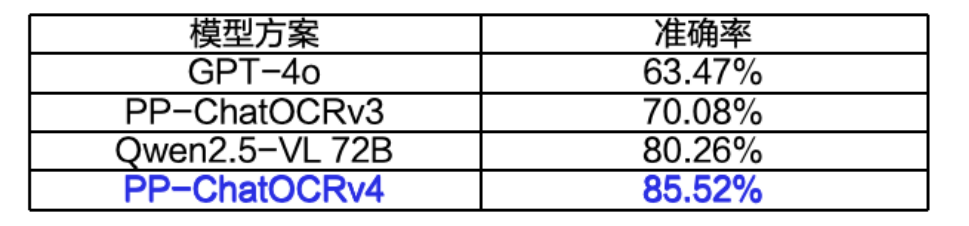
· 原生支持文心大模型4.5 Turbo,还兼容PaddleNLP、Ollama等工具部署离线大模型。
· 集成PP-DocBee2,支持印刷文字、手写体文字、印章信息、表格、图表等常见的复杂文档信息抽取和理解的能力。
欢迎开发者到飞桨星河社区体验PP-ChatOCRv4的能力:
https://aistudio.baidu.com/community/app/518493/webUI

实际测试
文档解析一直是大家比较关心的问题,尤其是大模型时代,做多模态文档解析的训练或者做大模型应用,都离不开文档解析的能力,所以当看到PP-StructureV3的文档解析指标这么强劲时候,不由得进行了一番测试,测试后还是觉得效果非常炸裂,虽然还是有瑕疵,但是比市面上开源的其他方案好太多,下边是一些测试case的结果:
说明书:
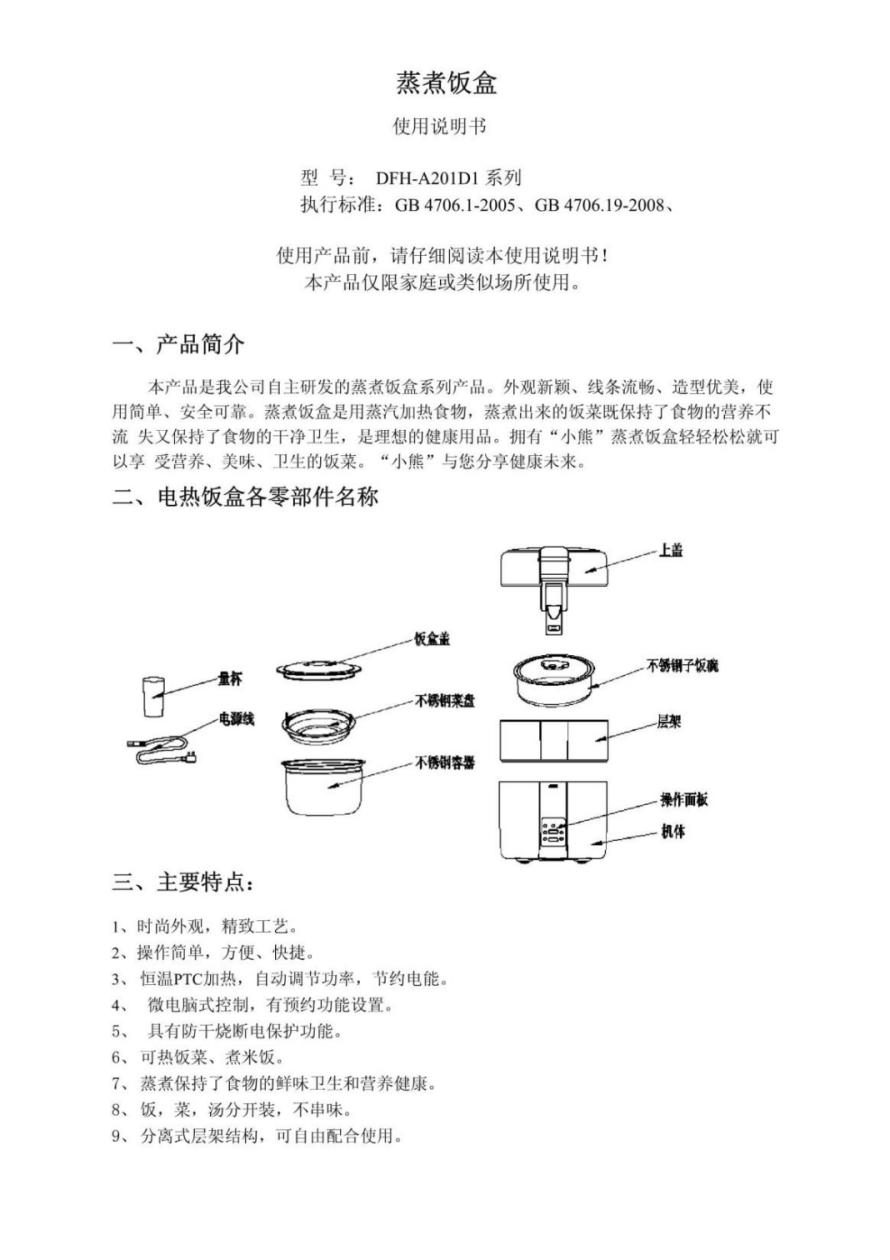
原图
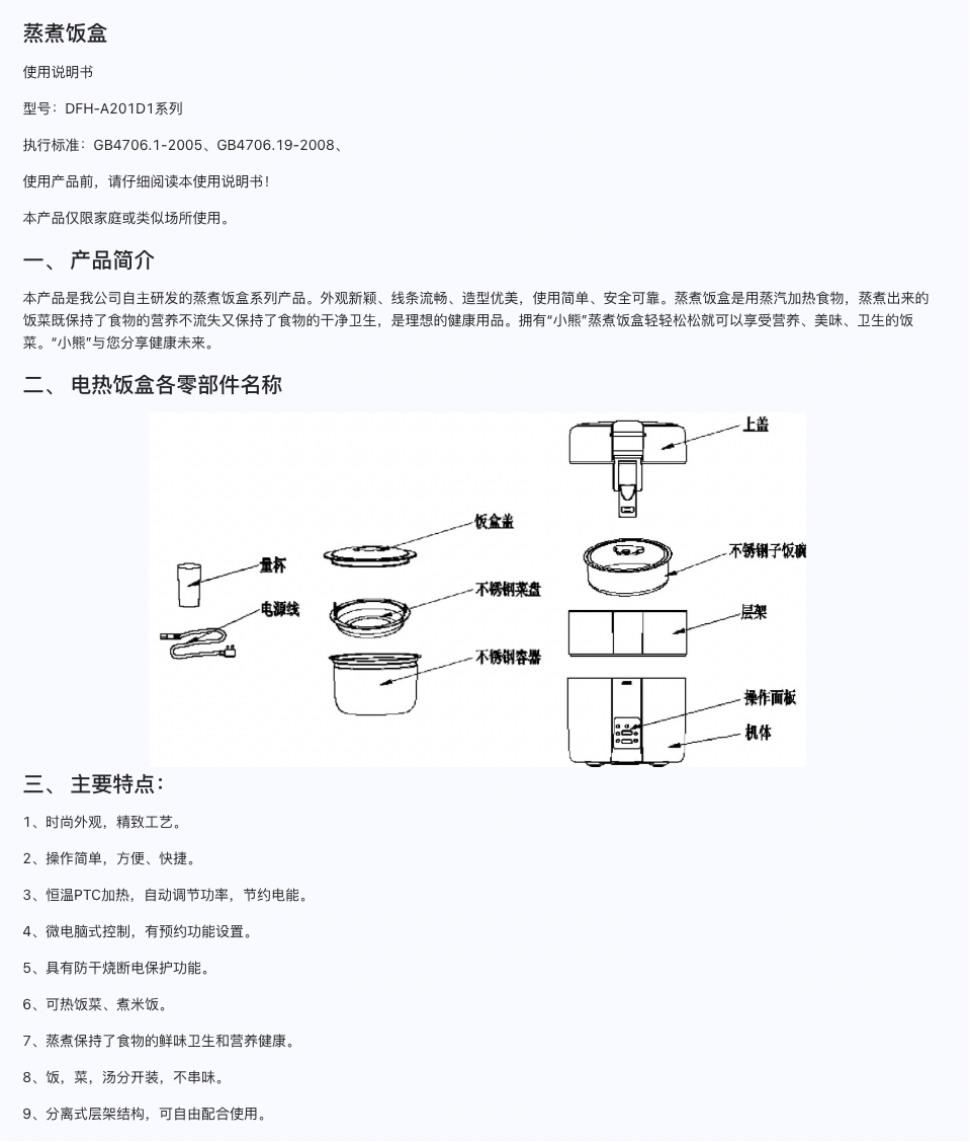
解析结果
英文杂志:

原图

解析结果

原图

解析结果
中学教案PPT:

原图

识别结果
补充下,这个确实非常强悍,目前开源的看上去似乎都搞不定,又试了几张,化学方程式似乎非常强悍,比如下边的几张:

原图

解析结果
表格中的图像竟然也可以得到并渲染出来,这个好像其他开源方案也无法做到:
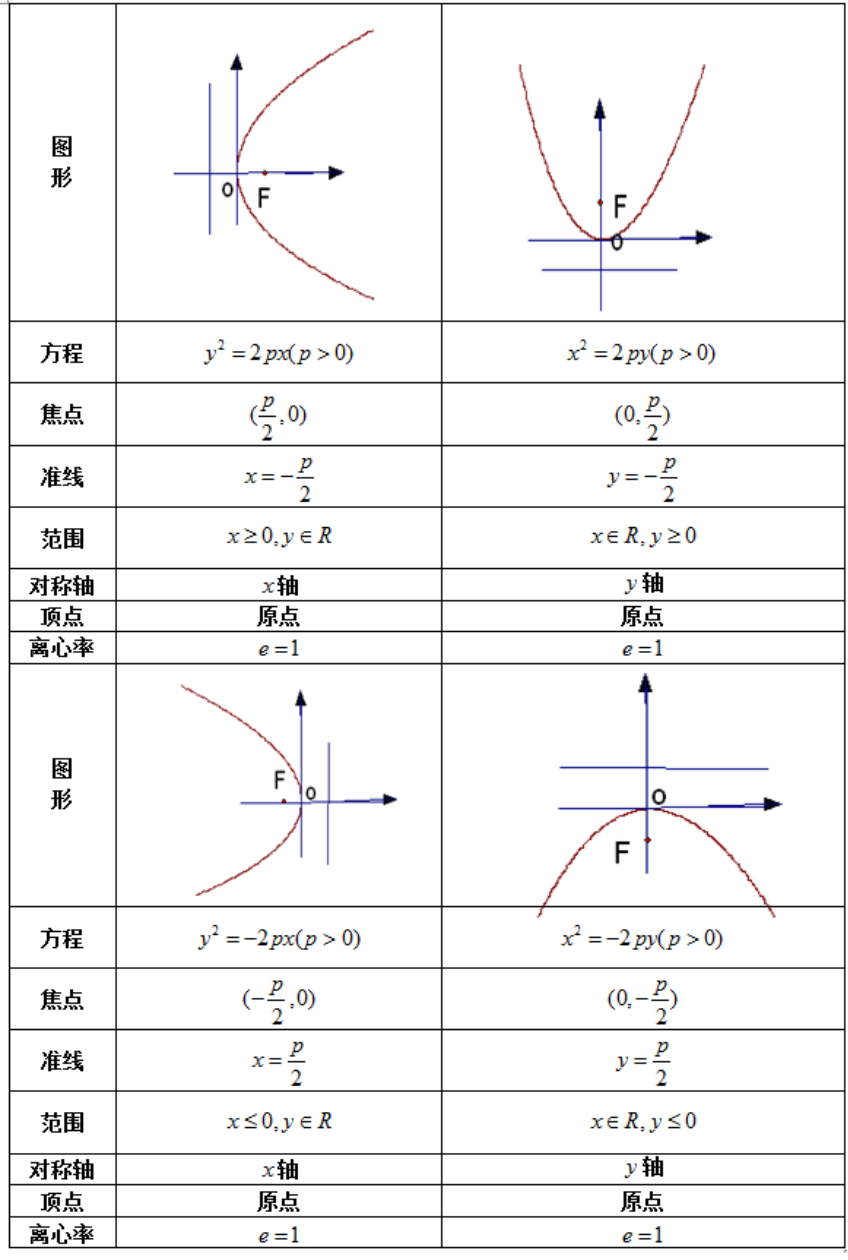
原图

解析结果
带背景颜色的表格:
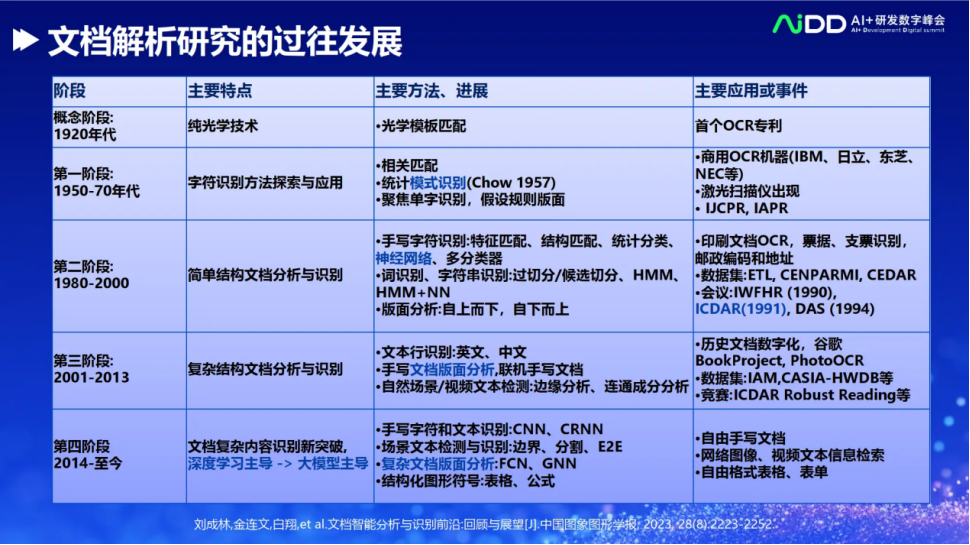
原图
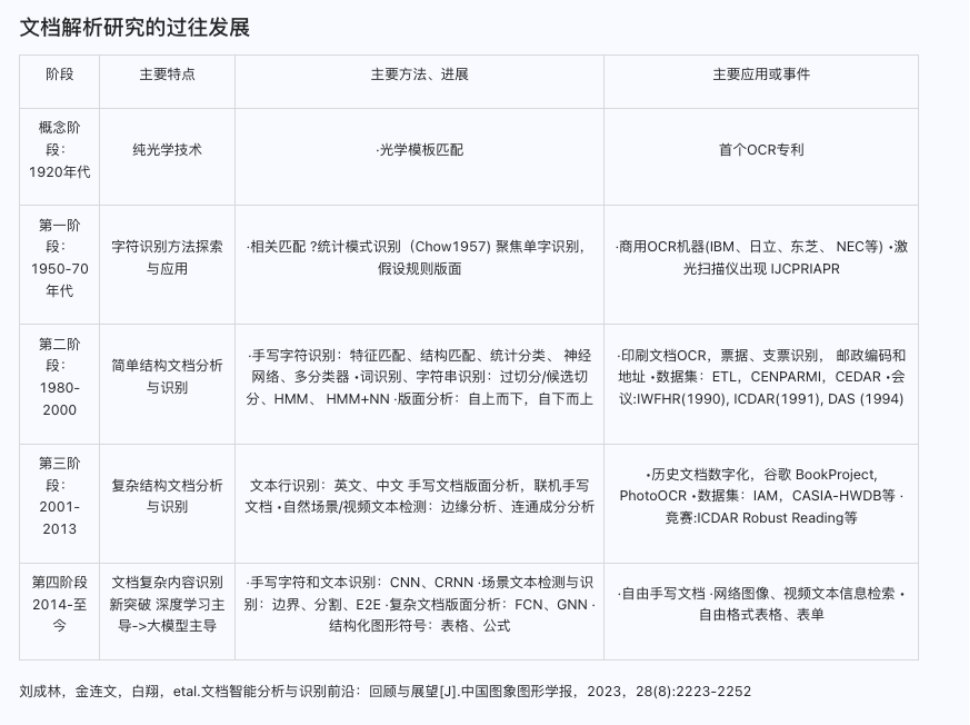
解析结果
复杂公式:

原图

解析结果
仔细对比,极个别的地方略有瑕疵,但是整体还是非常强悍!
竖版日文:

原图

解析结果
这个也有点东西,直接恢复了竖版的文本阅读顺序
中学教辅:

原图

解析结果
我发现PP-StructureV3很人性化的一点是,结果中的图片大小,基本可以和原图中的图片大小对齐,细节满分
另外PP-StructureV3增加了图表转表的能力,实测下来也比较强悍:

原图
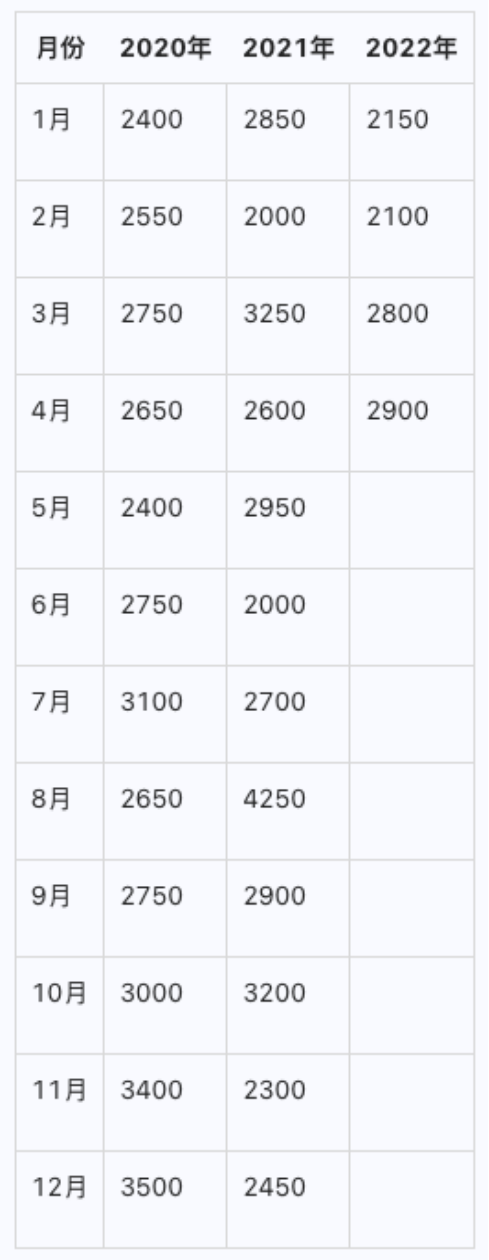
解析结果
这张图中,2022年之后没有解析结果,竟然也可以区分出来
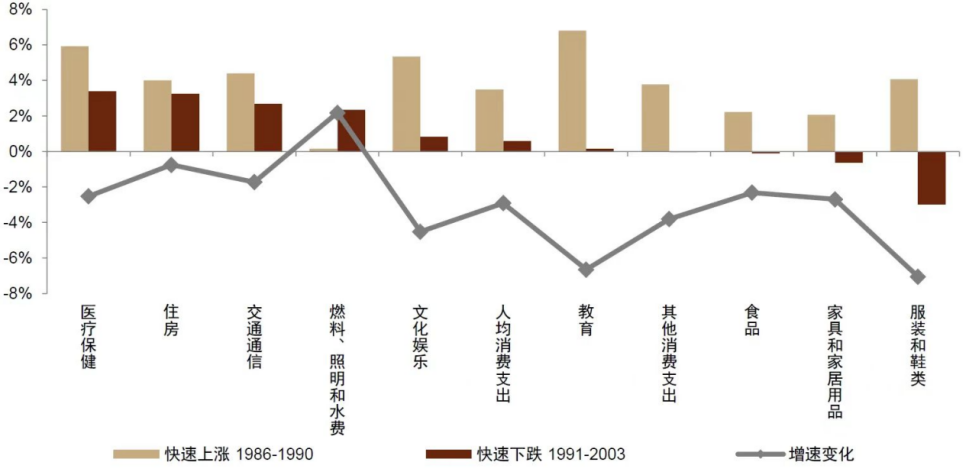
原图
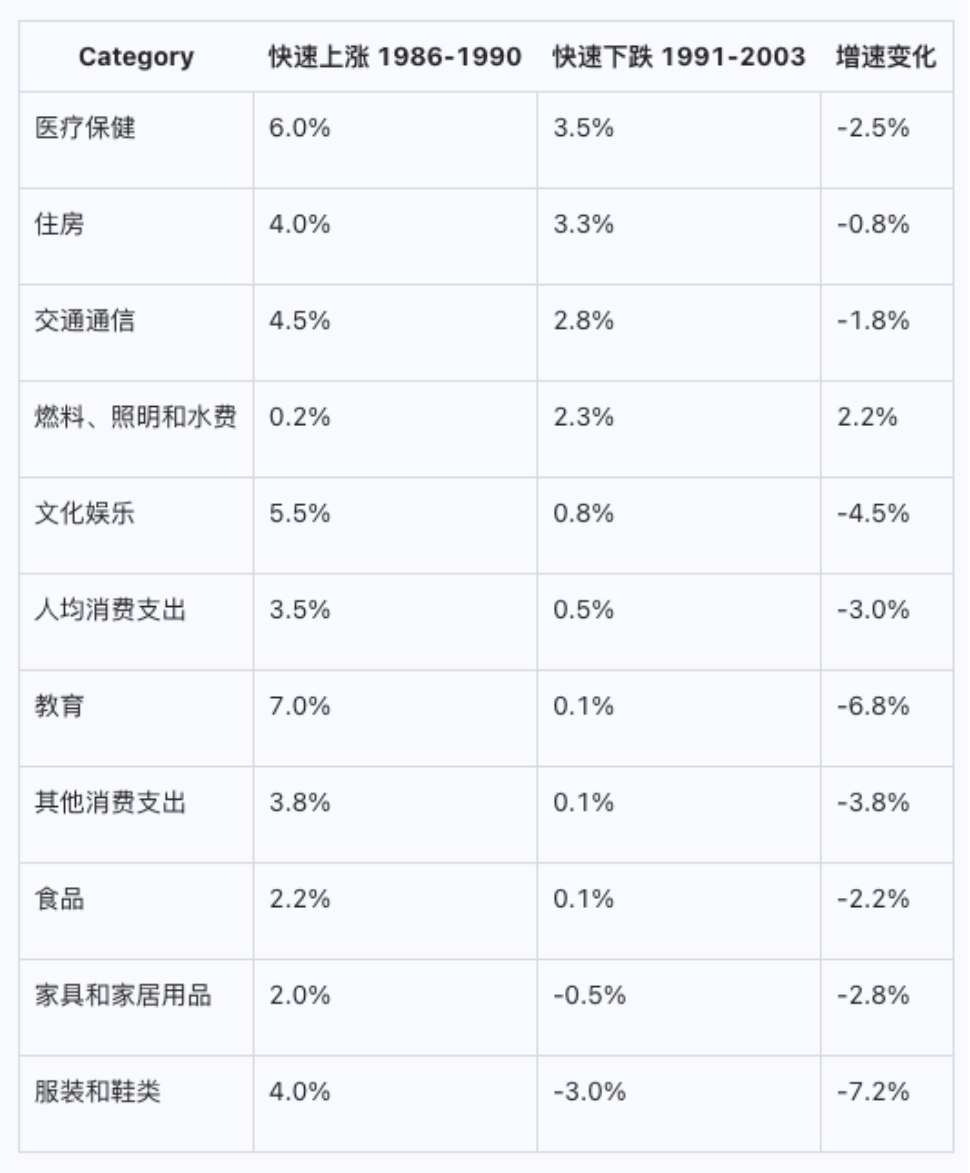
解析结果
看上去基本都是对的,这个能力感觉可以解决很多实际场景中,RAG的精准度~
整体测试下来的感觉是,虽然这次PaddleOCR3.0大家的关注度似乎都在PP-OCRv5上,但是PP-StructureV3更像是一颗隐形炸弹,能力还是远超目前其他开源方案的,估计会成为PaddleOCR用户的新宠。也希望PaddleOCR未来开源更多劲爆的能力,利好中小企业!
开源地址:
https://github.com/PaddlePaddle/PaddleOCR
技术交流:扫描下方二维码,加入PaddleOCR开源技术交流群,探索更多技术课程。

(文:开源AI项目落地)