

今天凌晨,阿里巴巴达摩院开源了最新文生图模型Qwen-Image。
Qwen-Image是一个200亿参数的MMDiT模型,可生成写实、动漫、赛博朋克、科幻、极简、复古、超现实、水墨等几十种类型的图片,支持图片的风格迁移、增删改、细节增强、文字编辑,人物姿态调整等常规操作。
Qwen-Image也可以生成OpenAI的GPT-4o爆火全网的吉卜力风格图片。根据「AIGC开放社区」实际测试二者差距很小,尤其是在超复杂中文提示词理解、文字嵌入方面Qwen-Image更好。
根据阿里公布的测试数据显示,Qwen-Image在GenEval、DPG、OneIG-Bench以及GEdit、ImgEdit和GSO测试中,图片生成、编辑能力非常出色,大幅度超越了文生图开源大黑马FLUX.1 [Dev],成为中文最好的文生图模型。
免费在线体验地址:https://chat.qwen.ai/c/guest
开源地址:https://huggingface.co/Qwen/Qwen-Image
https://modelscope.cn/models/Qwen/Qwen-Image
https://github.com/QwenLM/Qwen-Image
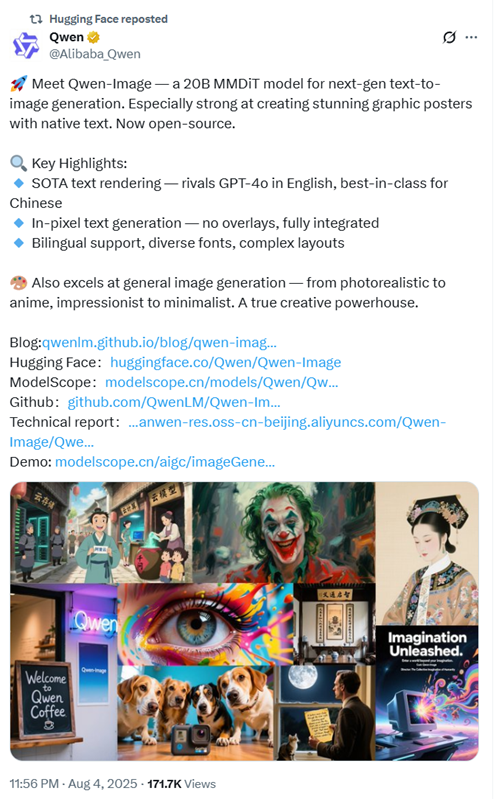
目前,阿里免费提供Qwen-Image,甚至不用注册账号访客模式也能使用。打开上面地址,然后选择下方的“图像生成”就可以开始了。
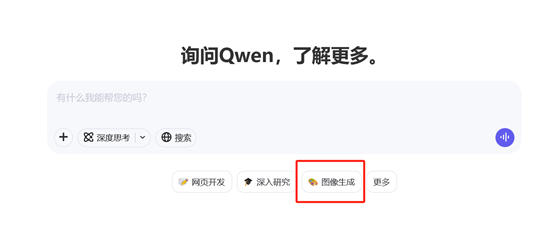
在生成图像前我们可以选择图像的比例,1:1、3:4、16:9等不同类型,可以适配手机、平板不同类型的设备和媒体平台。做封面、插图都非常好用
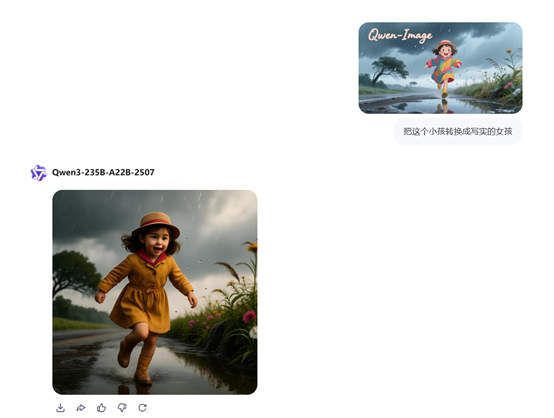
先试一个简单的提示:在风雨中奔跑的小女孩,面带笑容,上面写着Qwen-Image。吉卜力风格。


试个复杂点的,古代的长安城街道,街道两旁是古色古香的建筑,有酒楼、茶馆、商铺等,街上的行人穿着各式各样的古装,有的骑马,有的步行,还有小贩在叫卖商品,充满了浓厚的历史氛围。一座显眼的酒楼牌匾上写着“阿里巴巴达摩院”。


一位穿着“QWEN”标志的T恤的中国美女正拿着黑色的马克笔面向镜头微笑。她身后的玻璃板上手写体写着 “一、Qwen-Image的技术路线: 探索视觉生成基础模型的极限,开创理解与生成一体化的未来。
二、Qwen-Image的模型特色:1、复杂文字渲染。支持中英渲染、自动布局;2、精准图像编辑。支持文字编辑、物体增减、风格变换。三、Qwen-Image的未来愿景:赋能专业内容创作、助力生成式AI发展。”


再试一个英文的提示,An ancient battlefield, with dark clouds in the sky, thunder rumbling and lightning flashing. Soldiers in armor are fighting bravely on the battlefield. In the distance, huge monsters are roaring, as if it is a contest between humans and mythical creatures, filled with a tense and exciting at mosphere
中文意思,古代的战场,天空中乌云密布,电闪雷鸣,战场上有穿着盔甲的士兵在奋勇厮杀,远处有巨大的怪兽在咆哮,仿佛是一场人与神话生物的较量,充满了紧张与刺激的氛围。


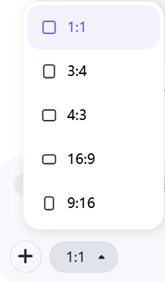
一片无垠的沙漠在夜晚静静铺展,天空中银河清晰可见,星星密布如银沙,前景是一座起伏的沙丘,风吹过留下细腻的波纹,宁静、庄严而神秘。

我们在体验一下Qwen-Image强大的图像编辑能力,就把上面刚生成的沙漠图片,转换成吉卜力风格吧。
直接把图片上传到对话框,然后输入,帮我把这张图片转换成白天吉卜力风格。


再把第一个生成的吉卜力风格小女孩转换成写实女孩。

对于阿里新开源的Qwen-Image,网友表示,非常好,和GPT-4o一样棒。

图片看起来好极了,一定要试试。

Qwen 团队在所有模型上都势如破竹!干得好,Qwen3 系列对于本地开源模型来说是相当大的升级。而现在,甚至连图像生成也是如此。
这真是一个超棒的模型,从未想过 Qwen能推出200亿参数的多模态扩散文本到图像生成模型,但它确实来了!
它在各项基准测试中性能超越了所有其他模型,并采用 Apache 许可证发布这非常值得称赞。祝贺 Qwen 团队。
Qwen-Image模型一共由多模态大语言模型、变分自编码器和多模态扩散Transformer(MMDiT)三大块组成。
其中,多模态大语言模型扮演着条件编码器的角色,负责从文本输入中提取关键特征。Qwen-Image选用Qwen2.5-VL 作为这一模块的实现。Qwen2.5-VL不仅在语言和视觉空间的对齐上表现出色,能够使语言和图像信息在同一个维度上相互呼应,而且在语言建模能力上也毫不逊色,与纯粹的语言模型相比,几乎没有任何性能损失。
Qwen-Image支持多模态输入,能够同时处理文本和图像,解锁了更广泛的功能,例如,图像编辑等高级应用。当用户输入文本描述时,Qwen2.5-VL会提取其中的关键特征,将其转化为高维空间中的向量表示,为后续的图像生成提供精准的语义指导。
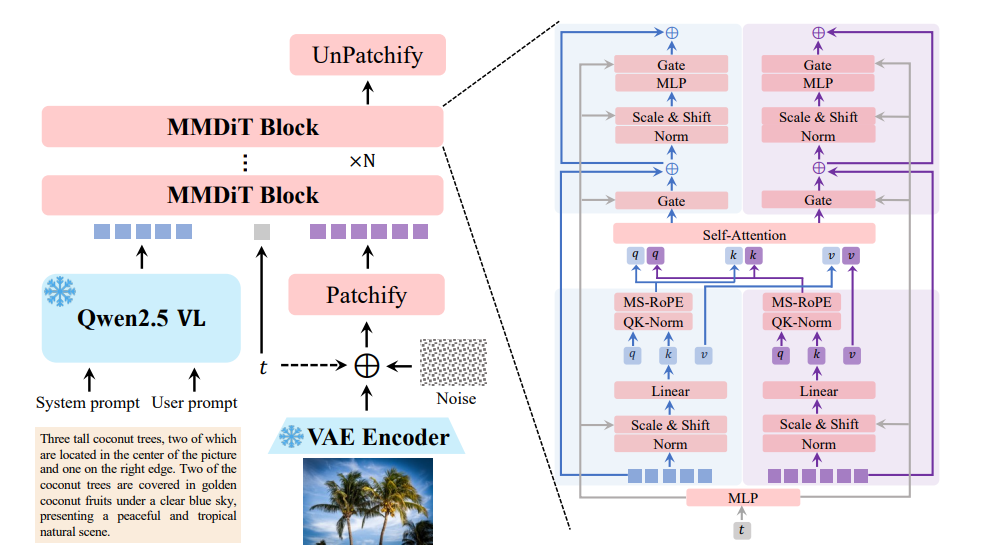
变分自编码器则承担着图像token化的功能,负责将输入图像压缩为紧凑的潜在表示,并在推理阶段将潜在表示解码回图像。Qwen-Image的VAE设计采用了单编码器、双解码器架构,这一设计源于对通用视觉表示的追求,既需兼容图像与视频,又要避免联合模型常见的性能妥协。
Qwen-Image基于Wan-2.1-VAE的架构,冻结其编码器以保持基础能力,仅针对图像解码器进行微调,使其更专注于图像领域的重建任务。为提升小文本和精细细节的重建保真度,解码器的训练数据包含大量文本丰富的图像,涵盖真实文档与合成段落,涉及多种语言。
在训练策略上,通过平衡重建损失与感知损失减少网格伪影,并动态调整两者比例,同时发现当重建质量提升后,对抗损失效果减弱,因此仅保留前两种损失,最终实现了在保证效率的同时,增强细节渲染能力的目标。
MMDiT作为Qwen-Image的核心架构主要负责在文本引导下对噪声与图像潜在表示之间的复杂联合分布进行建模。还引入了创新的 Multimodal Scalable RoPE(MSRoPE)嵌入方法,有效解决了文本与图像在联合编码时的位置混淆问题。
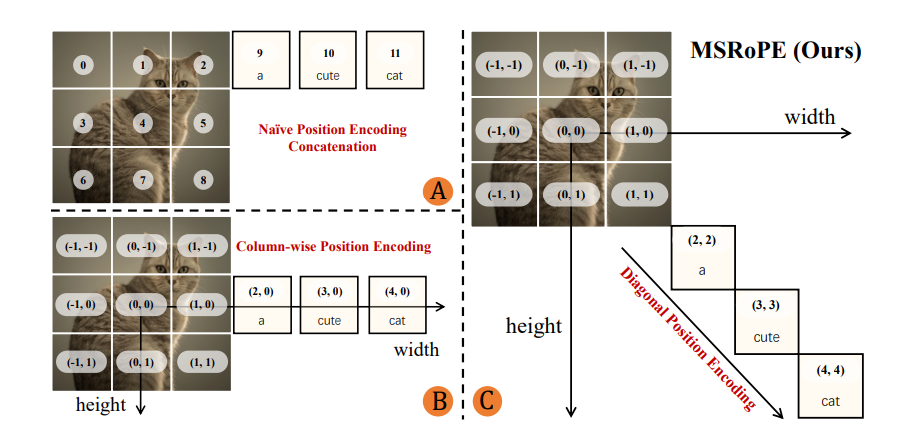
传统方法中,文本 token 常直接拼接在图像位置嵌入之后,或被视为特定形状的 2D token,易导致部分位置编码同构,影响模型区分能力。
而MSRoPE将文本输入视为二维张量,在两个维度上应用相同的位置 ID,概念上沿图像对角线进行拼接,既保留了图像分辨率缩放的优势,又在文本侧保持了与 1D-RoPE 的功能等效,无需为文本确定最优位置编码,显著提升了图文对齐的准确性。
(文:AIGC开放社区)