
“ 格式化输出并仅仅对人类友好,更重要的是更利于程序处理,这为模型的应用提供了基础条件。”
在大模型应用开发过程中有很多人可能没有注意到一个点——格式化输出;或者说很多人并没有重视格式化输出这个问题,因为在现有的开发框架或者使用大模型的过程中,我们只需要告诉模型进行格式化数据,模型就可以给我们格式化数据。
也因此,很多人忽略了大模型格式化输出的问题,以及它的技术原理;那么,大模型是怎么实现格式化输出的呢?

大模型格式化输出问题
从使用者的角度来说,可能绝大部分人都不会在意模型的格式化输出问题;但作为一个开发者来说,很多人应该都知道数据格式化的重要性。
但大模型的格式化输出到底是怎么实现的呢?
格式化输出是属于大模型自身的能力范畴,还是通过外部手段约束的一种方式?
其实从模型本身来讲,语言模型只预测文本序列,自身并没有主动“格式化”数据的意识;但这并不意味着模型没有格式化数据的能力。
还用人举例来说,让你写一篇报告你肯定按照常规的写法来写,并不会上来就用某种文档格式来写;只有在有明确要求的情况下,才会按照某种格式来写报告;比如说是word文档还是PPT形式的幻灯片。
对模型来说也是如此,模型一般情况下会按照序列化的方式来输出内容;而当你在提示词中明确告诉它用json或其它格式的形式进行输出,模型才会使用格式化输出。
当然,随着大模型应用的发展,很多场景对格式化输出有了更高的要求,因此很多模型在格式化输出方面都进行了专门的强化训练;这就相当于让模型专门学习一些格式化数据,当它下次再碰到相似的场景时,就会下意识的使用格式化输出。
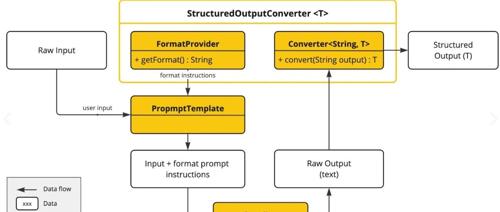
既然模型本身能够进行格式化输出,那Langchain中的BaseOutputParser解析器的作用是什么呢?
虽然说经过训练的模型或者通过提示词来约束模型输出格式化数据,但从实际情况来看模型即使输出格式化的数据,也是以字符串的方式进行数据;而不是直接输出能够被程序直接处理的格式化数据。
因此,BaseOutputParser充当了负责桥接文本与结构化数据的桥梁,确保输出可被程序直接使用。
并且,为了应用的健壮性在输出解析器中还进行了一些异常处理,当模型输出不符合要求时,解析器可以捕获其异常,然后让模型重新输出规范化数据或者直接抛出异常,告诉开发者模型输出异常问题,并优化其输出结构。
并且,为了方便使用,在Langchain的链式调用中可以直接把输出解析器作为最后一个节点;把模型输出直接转换成程序可以直接处理的格式化数据,这样开发者就不需要关心模型的输出的结构化问题,只需要关心其业务逻辑即可。
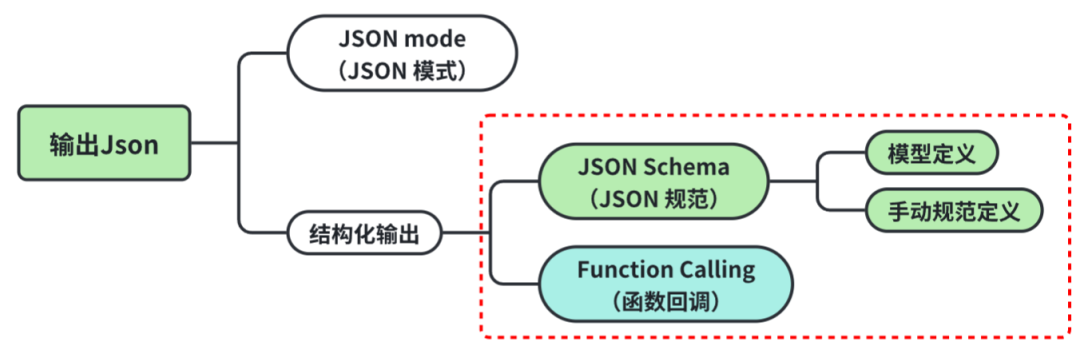
结构化输出是大模型应用的基础,没有结构化输出大模型应用就无从谈起。而且很多模型在迭代或发布的时候都会强调,优化了模型格式化输出能力。
(文:AI探索时代)