


WAIC 2025大会上,上海人工智能实验室发布并开源了最新的科学多模态大模型Intern-S1(代号“书生”)。

体验地址:https://chat.intern-ai.org.cn
GitHub:https://github.com/InternLM/Intern-S1
HuggingFace:https://huggingface.co/internlm/Intern-S1-FP8
ModelScope:https://modelscope.cn/models/Sh
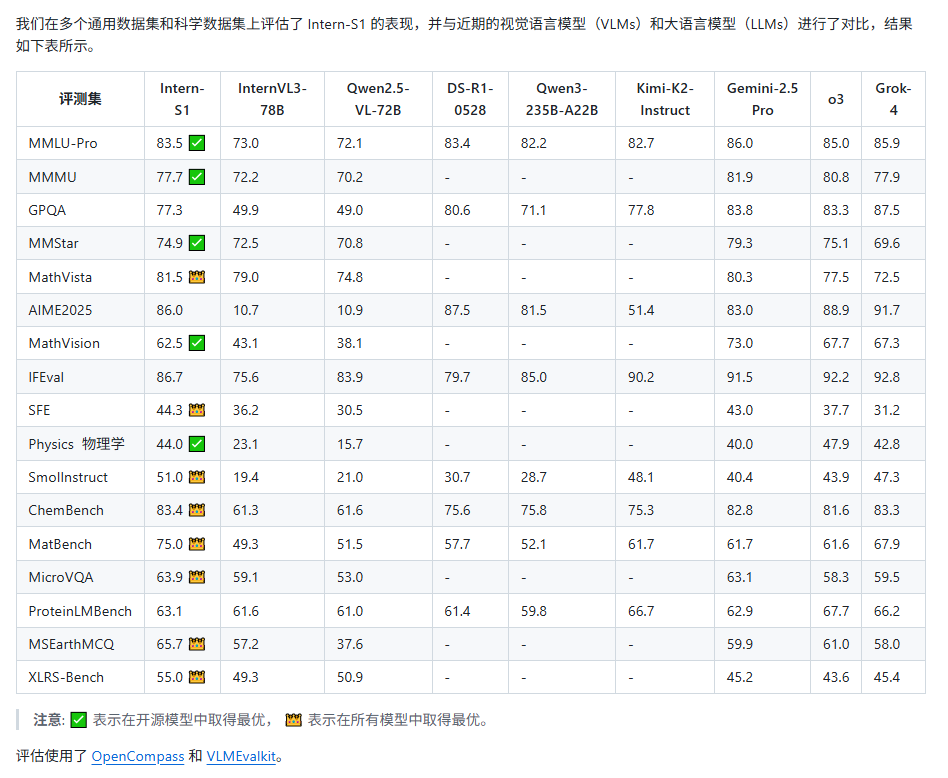
在多个测评基准上,Intern-S1的多模态理解能力位列全球开源第一,文本能力比肩国际顶尖模型。
此前,通用大模型一般不会对科学领域做专门的训练,所以即便主流的通用大模型在推理、编码、数学上不断刷新SOTA,但在面对复杂的科研场景时,也一样抓瞎。
而Intern-S1不仅能精准解读化学分子式、蛋白质结构、地震波信号等复杂科学数据,在专业科学任务上更是全面超越了Grok-4等顶尖闭源模型。
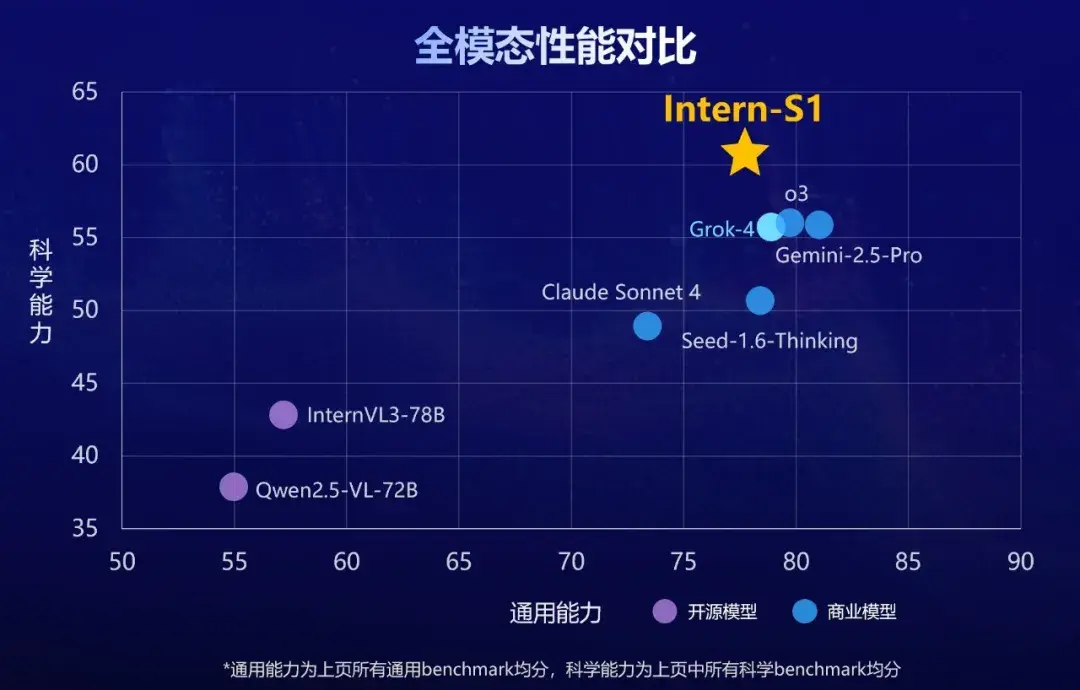
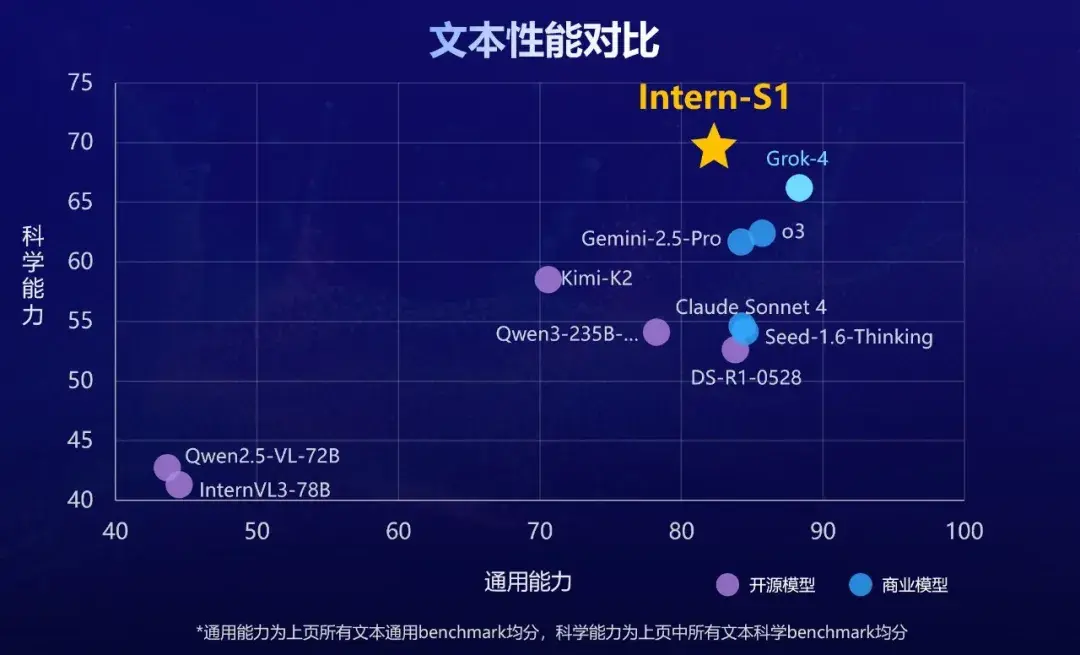
Intern-S1到底有多强?我们找来国内外几款主流模型,一起横评对比一下。

横评对比
1)可视化工具
我需要一个可视化工具来演示简单谐振动。您是一位前端网页开发(HTML、JavaScript、CSS)和科学可视化的专家。您的任务是生成一个完整的HTML文档,包含基于以下用户查询的必要交互或动画。 我想要一个关于一个附着在弹簧上的块体上下振荡的动画。当块体移动时,我希望实时绘制一张图,显示其位置与时间的关系。请包含滑块,以便我可以调整运动的振幅、弹簧的刚度和块体的质量,让我的学生看到每个参数如何影响最终的正弦波。
您必须严格遵循计划中指定的组件列表、组件类型和ID定义。
布局、结构和交互性必须反映计划中的交互逻辑。
您可以使用HTML、CSS(内联或嵌入)和JavaScript,并且如果任何组件需要它们,必须通过CDN包含正确的JavaScript库(如Plotly、Chart.js或MathJax)。
HTML文档必须是自包含和功能完整的,准备在网页浏览器中打开。您的输出必须仅是用html和包裹的HTML代码,不需要额外的解释或评论。首先来看文心4.5,它画错了弹簧和块体的运动形态,图表也没有实时显示(每次调整后显示一个波形就消失了),显然内部代码逻辑出了错误。
然后来看下豆包,它给出的演示页面基础功能算是完整,有弹簧和块体的动画演示、实时图表和三个调节滑块。
页面布局上,豆包的图表狭长,画面占比很少,不太适合教学展示。横坐标的数值跳动特别快,波形移动速度整体很快,也比较难看清。
然后来看下Gemini 2.5 Pro ,页面结构也很完整,图表内容清晰,但是我调整滑块时,波形消失了,缺少了实时调节。
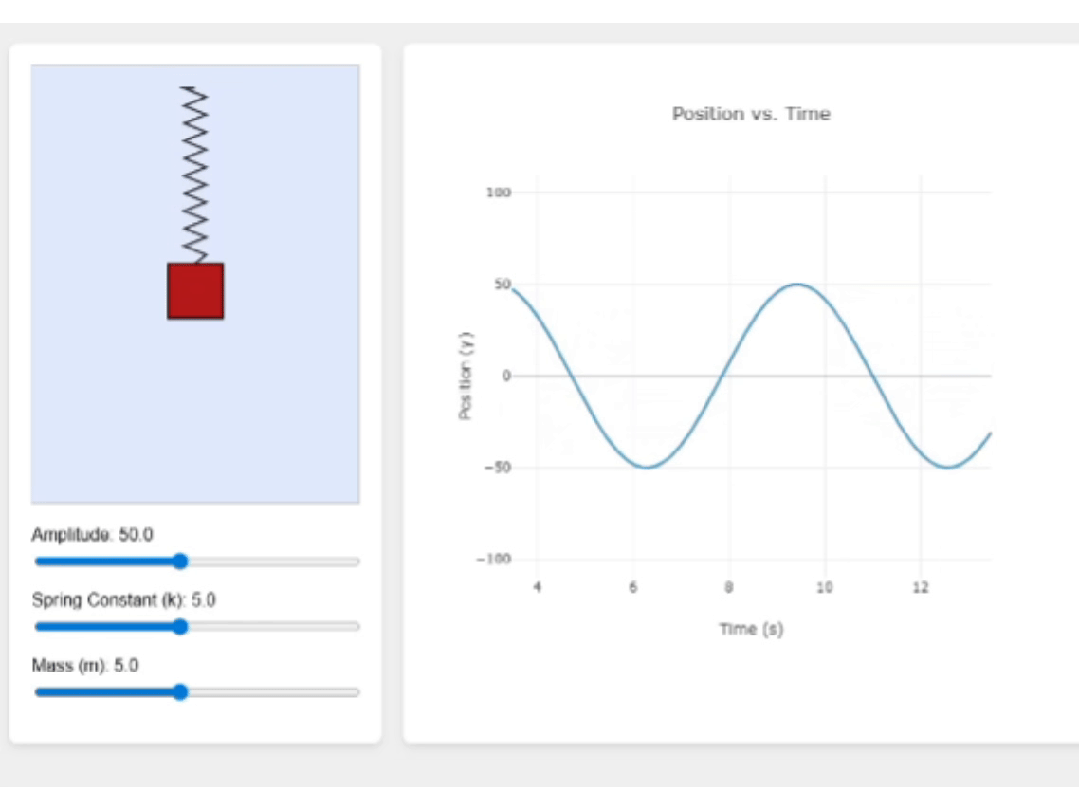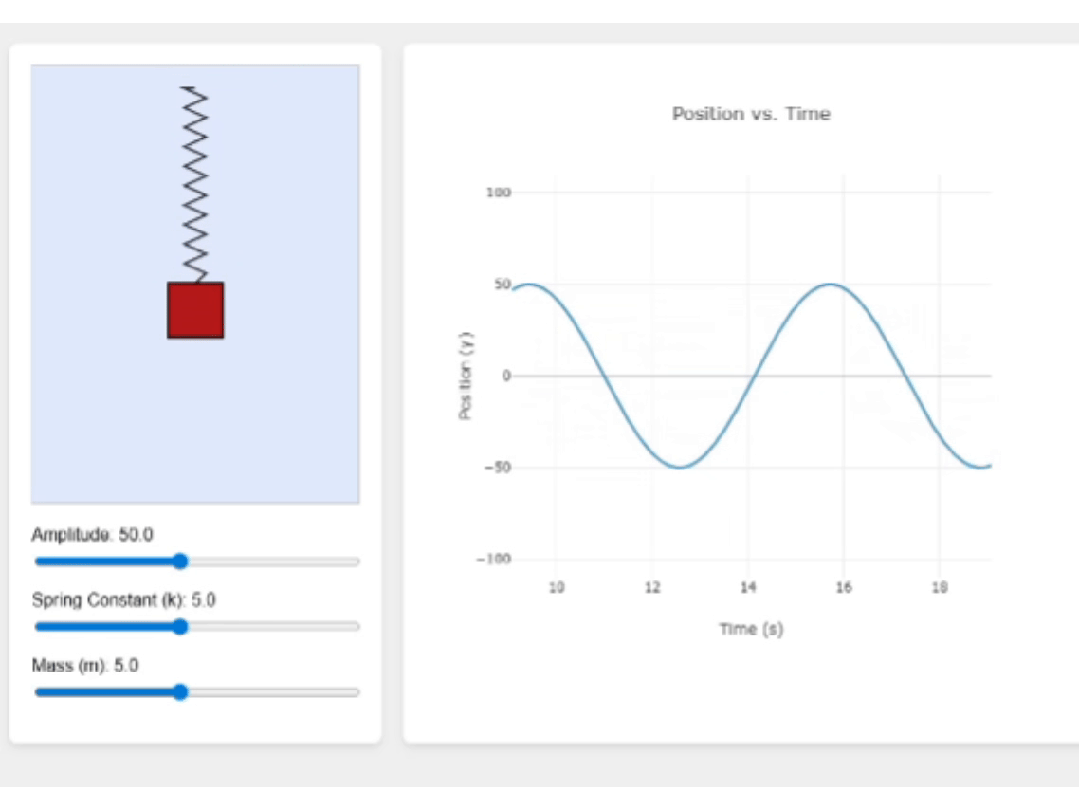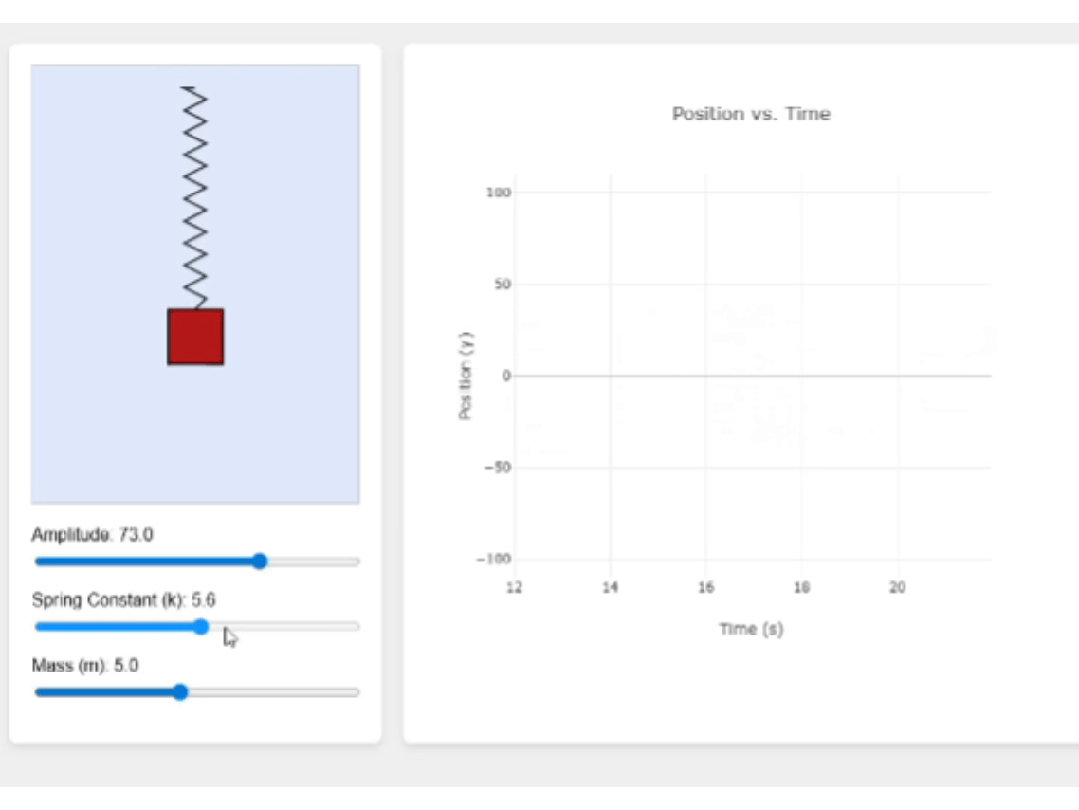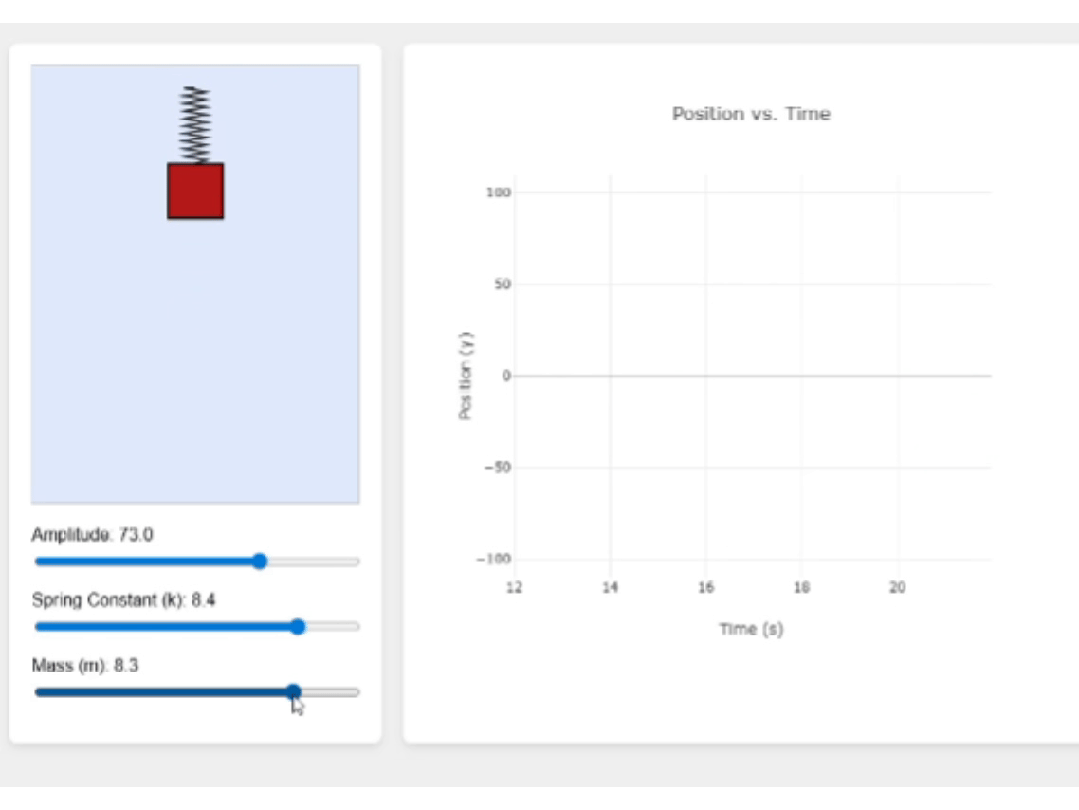
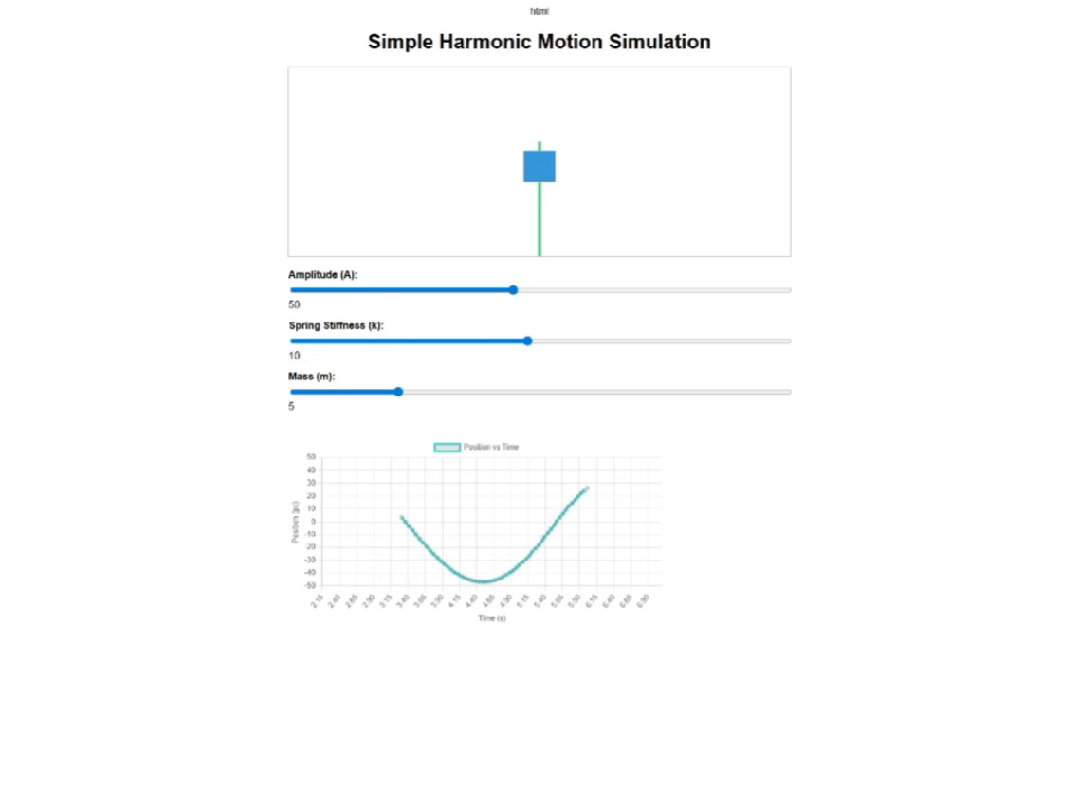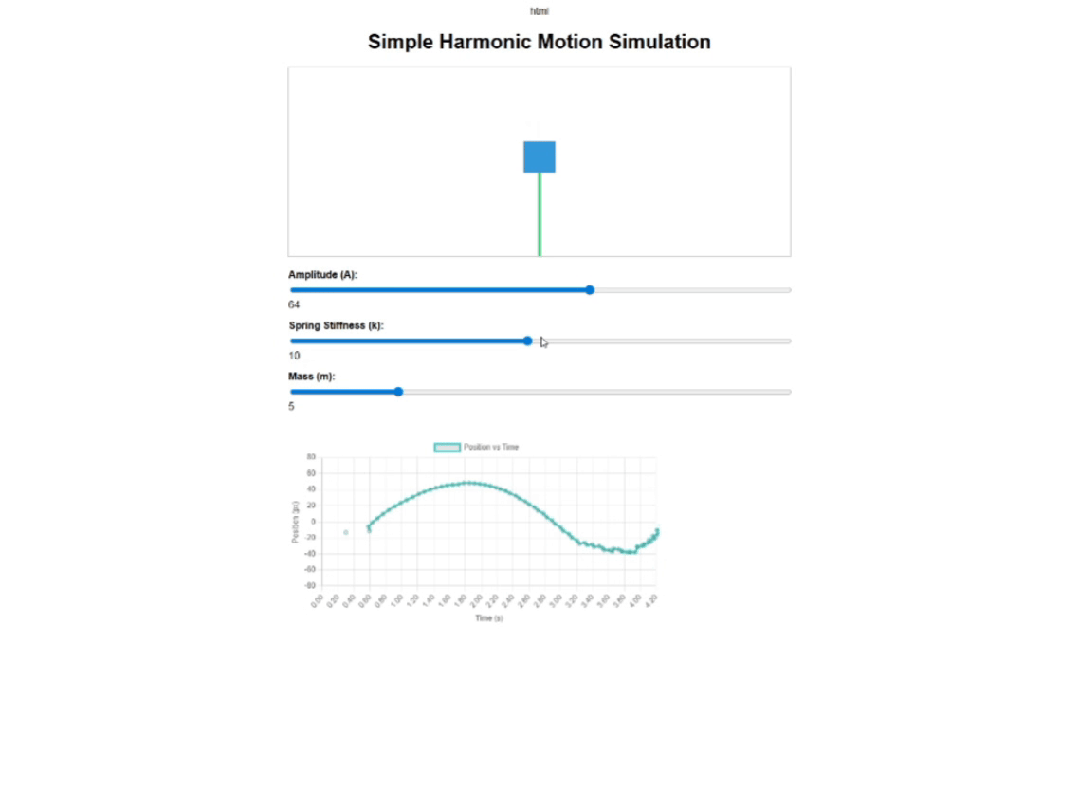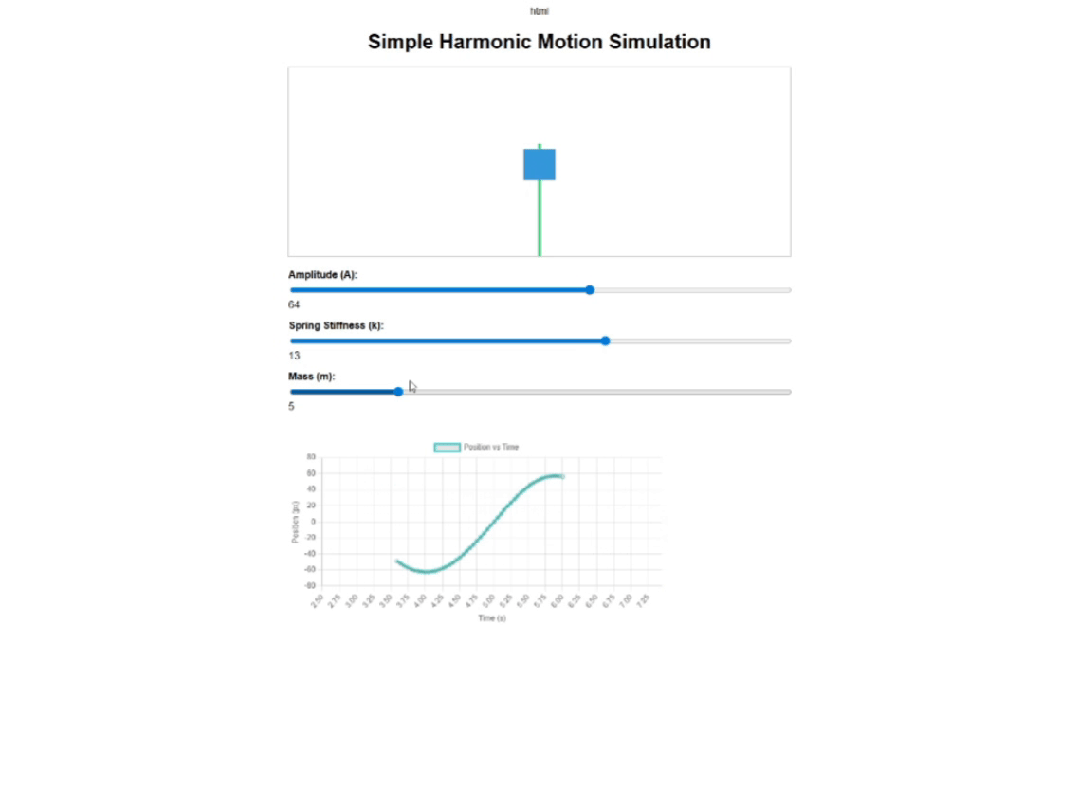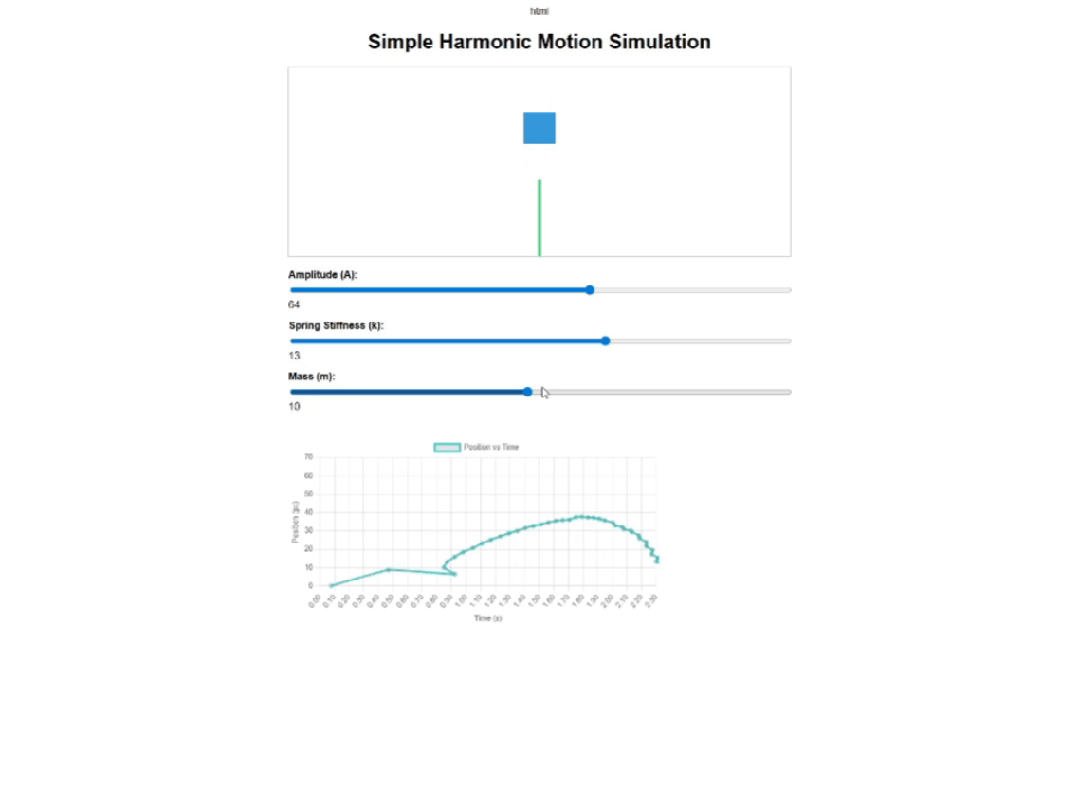
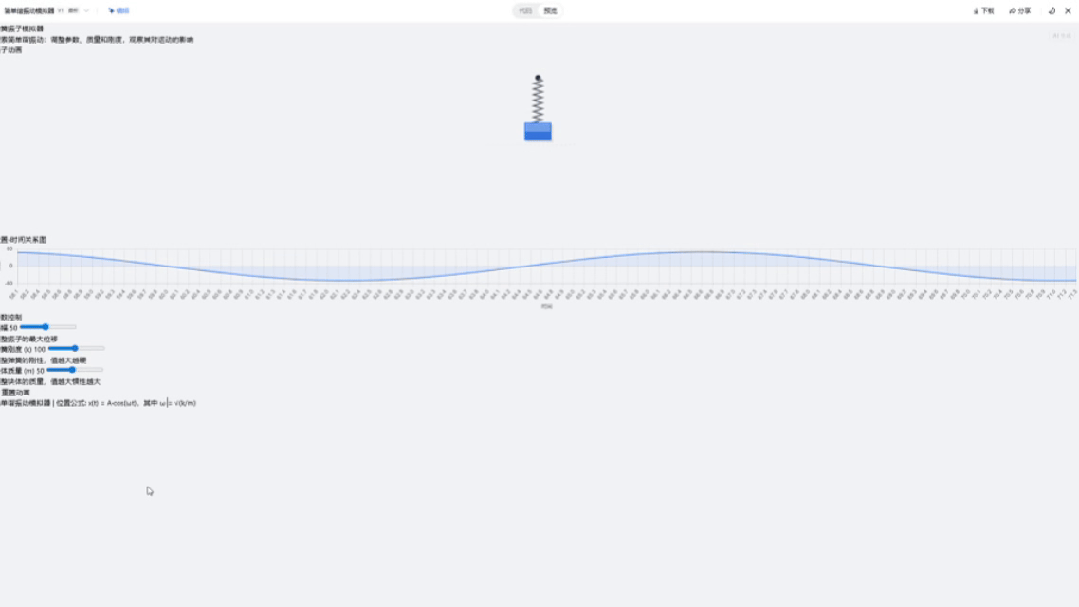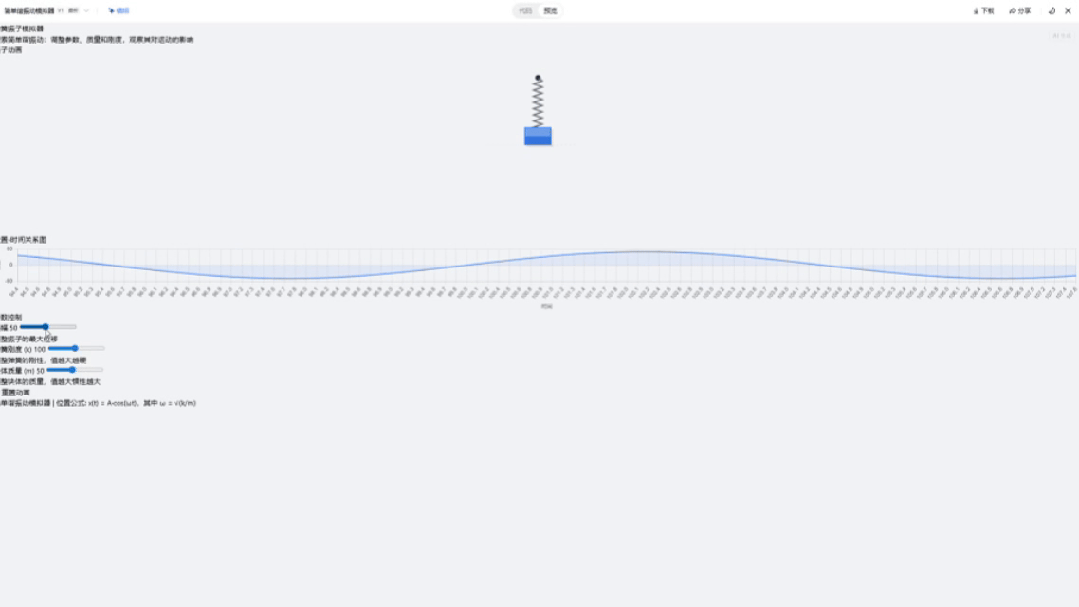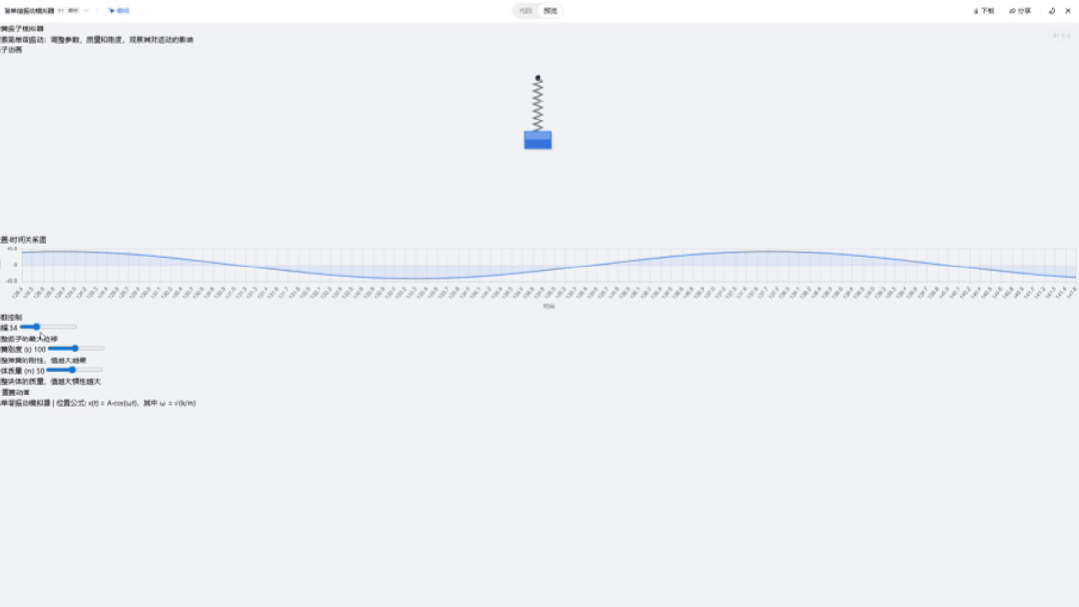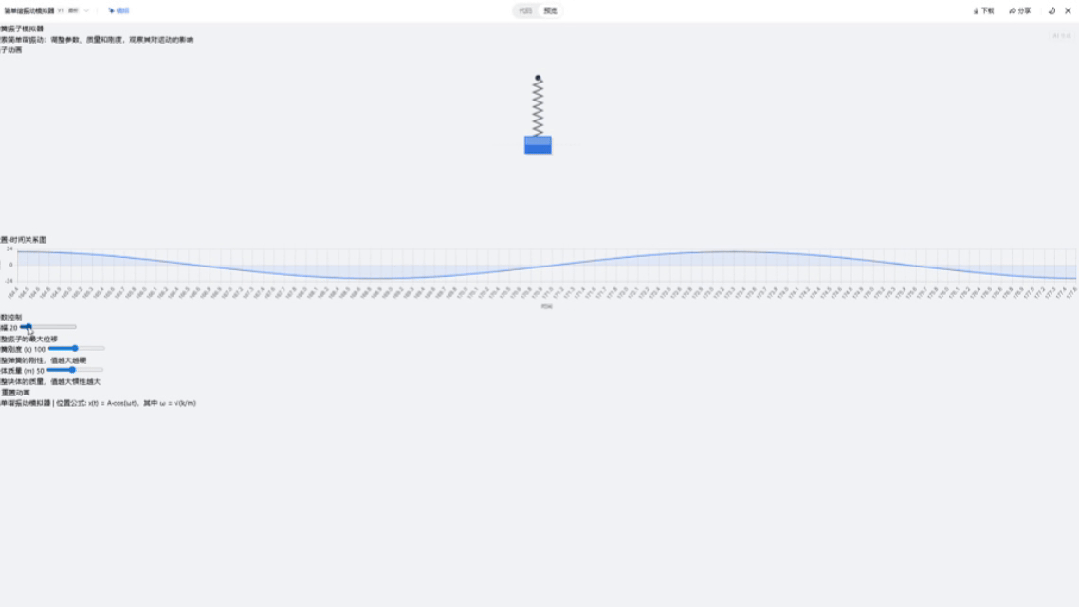
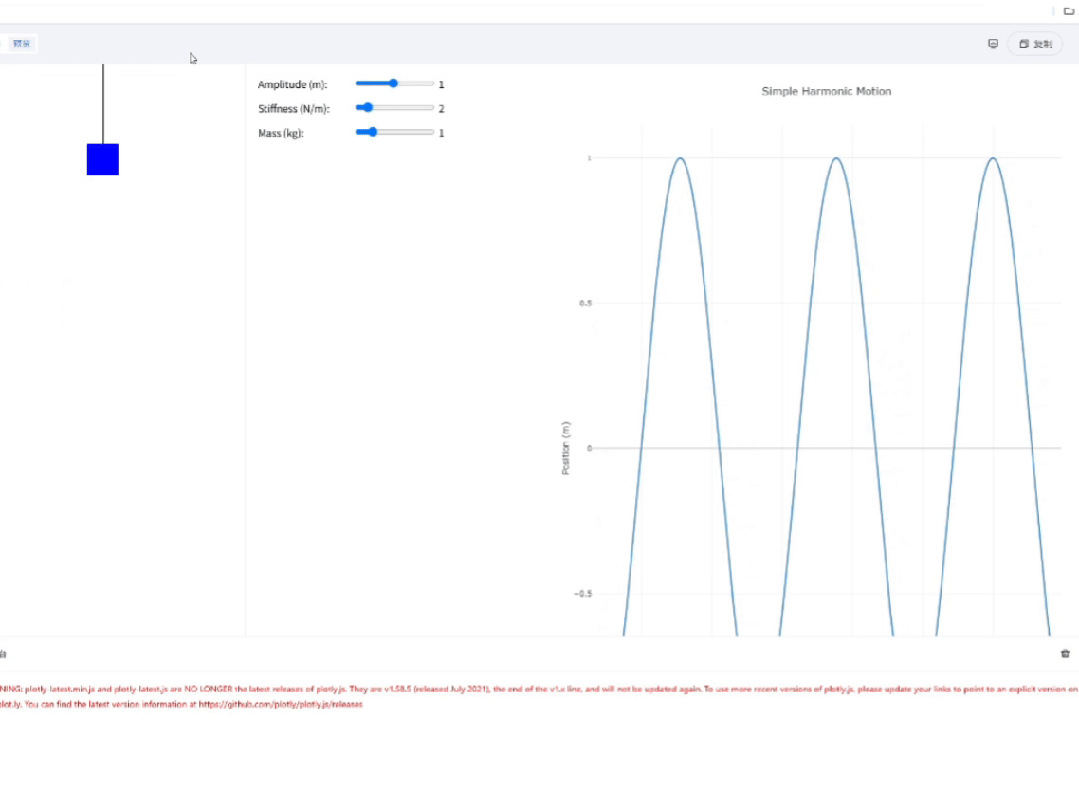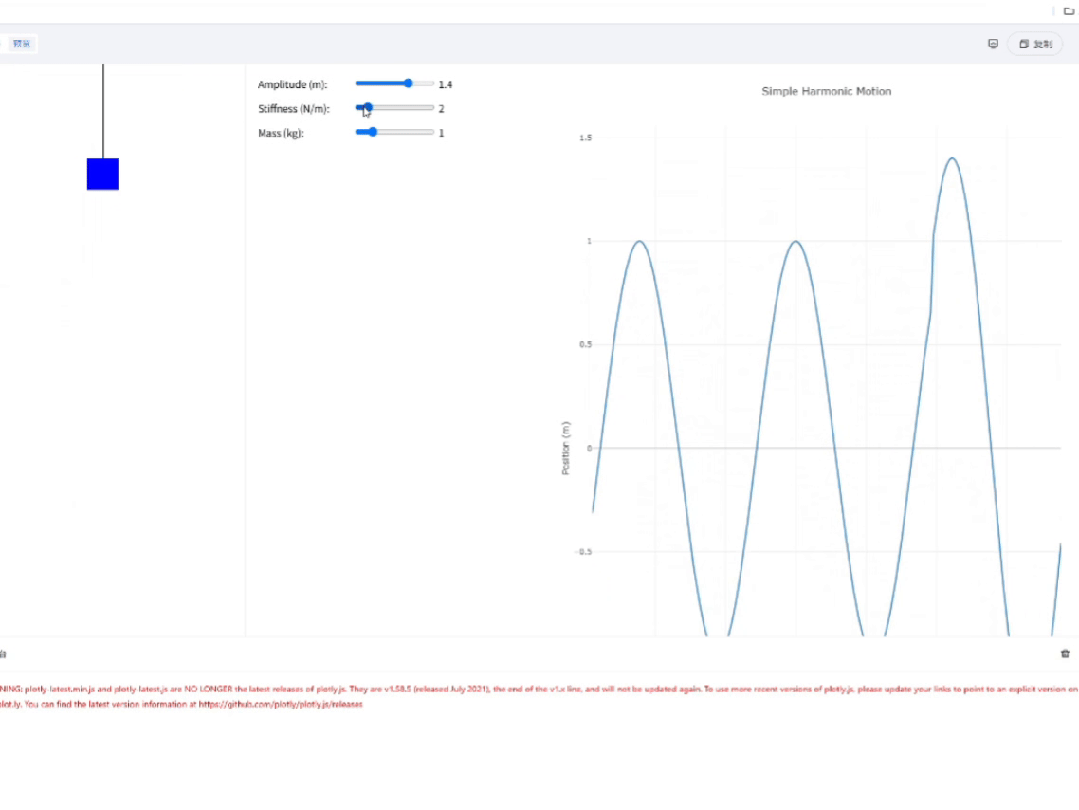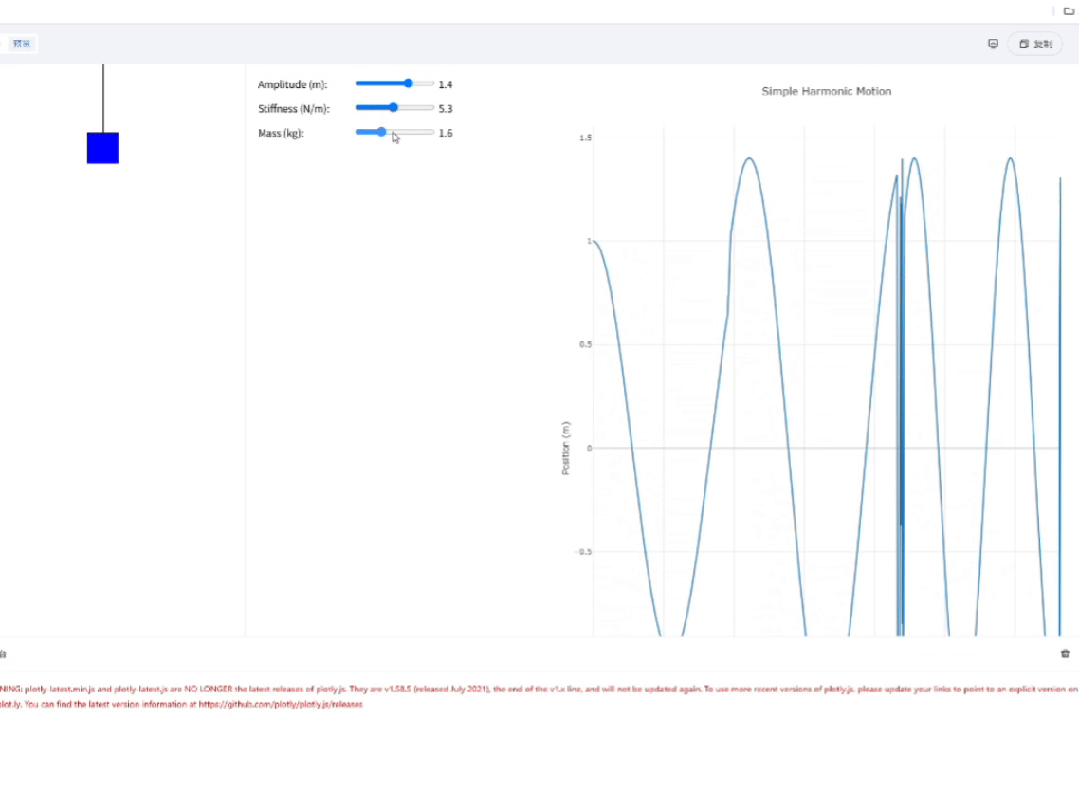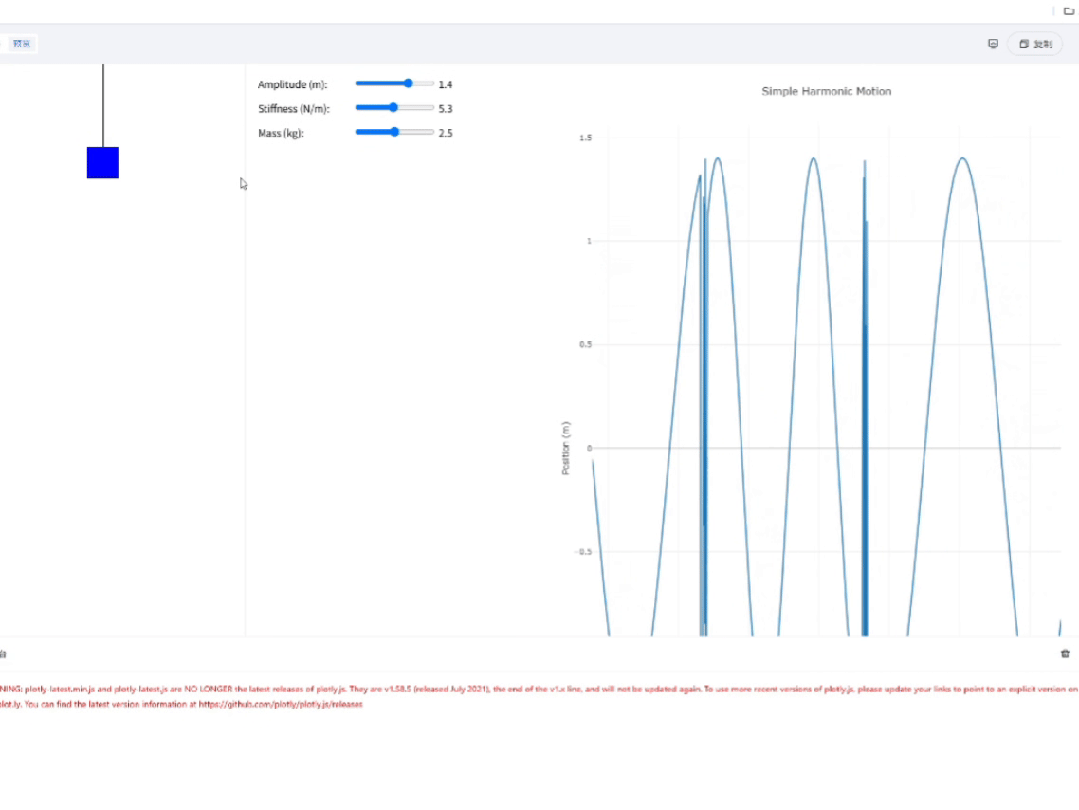
最后来看下Intern-S1,它的页面功能很完整,当我调整滑块时,波形也会随之调整,足见其前端代码的鲁棒性。
页面的视觉效果也很不错,很适合教学演示。
2)化学分子式解读
最近刷到一个很有意思的表白贺卡,我也挺想知道这个化学式到底有什么含义。于是我找几个AI分别分析了一下。
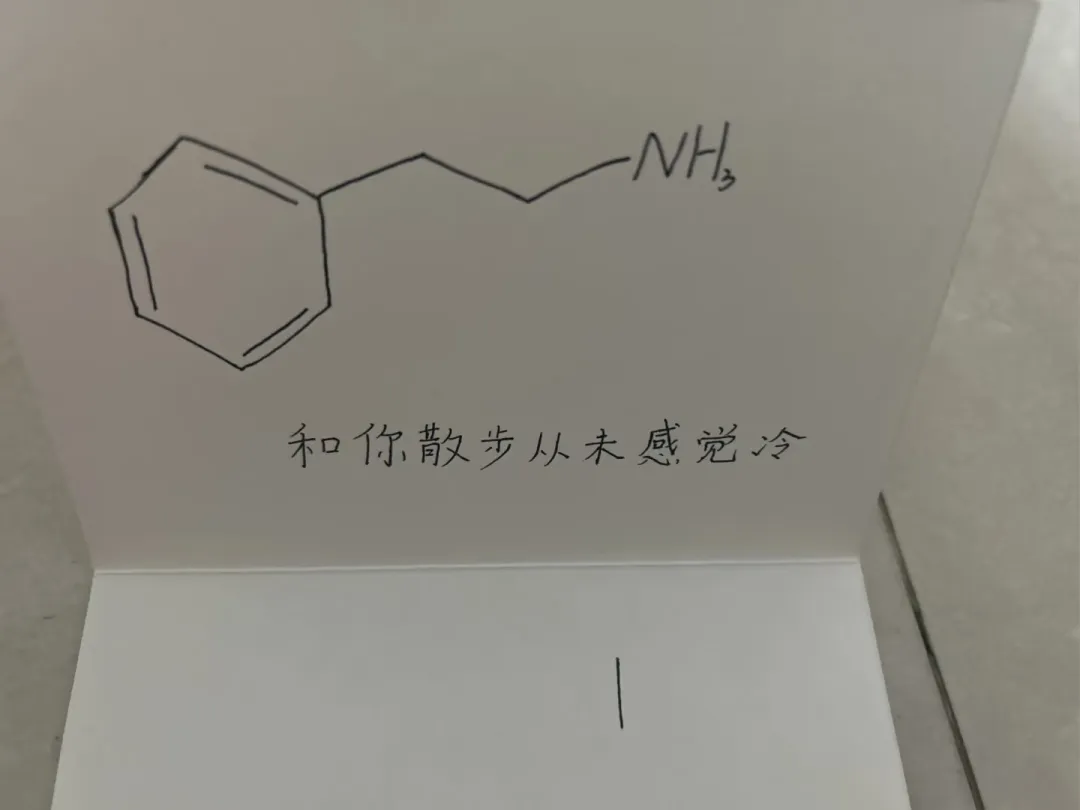
这里主要考验大模型的图像识别能力。另外图中的化学式多了一个“氢”,我们来看看大模型能不能准确识别出来。
文心4.5 Turbo识别出图片中的内容是一个化学结构式和一句浪漫的文字,给出了正确的化合物名称,还结合图中的文字部分进行了简单的介绍,还不错。
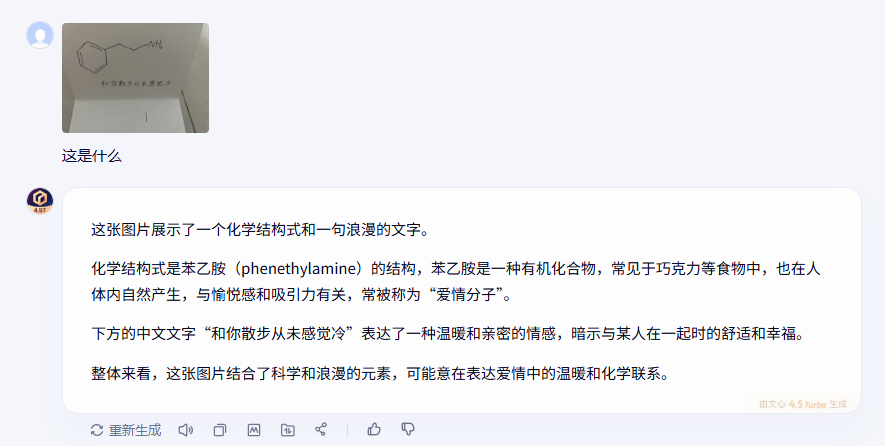
豆包也准确识别出了苯乙胺和文字内容,但是没有将它们“关联”起来。

Gemini 2.5 Pro的回答很不错,它准确的指出了图中氨基的写法是错误的,不过也不影响它识别出这是苯乙胺。
给的解释也很清晰——苯乙胺常被称作“爱情分子”,因为当人坠入爱河时,大脑会分泌更多的苯乙胺,带来愉悦和兴奋的感觉。

Intern-S1的思考过程非常严谨,首先它确认了这是苯乙胺,并结合文字内容做出分析出:可能是在暗示和对方在一起时,有温暖或愉悦感。

再来看Intern-S1的回答,简直是教科书级别,它先给我们科普了苯乙胺的化学结构式、结构。
还顺带介绍了苯乙胺的科学背景:苯乙胺是什么、有什么作用、化学分类等等。它还分析出,这张卡片类似“化学情书”。

不止这些,Intern-S1还做了更多拓展的介绍,比如,关于这张卡片可能的应用场景。
由于原图中的笔误,它还联想到了苯乙胺是否容易与苯丙胺混淆,介绍了两者的区别,顺便再次科普苯乙胺的实际作用。
真的太全面了!

3)科学解读
请从科学角度解释睡美人悖论。先给大家说一下什么是睡美人悖论:假设城堡中有一个睡美人,在周日的时候,她会睡着。
抛一枚硬币,如果正面朝上,那么她会在周一被叫醒,接受提问。如果背面朝上,周一她也会醒来,接受提问,然后重新入睡,周二她会被再次唤醒,接受采访。
在她每次入睡后,她都会忘记自己曾经被唤醒,并且在她醒来的时候,她不知道是周一还是周二。
每次对她的提问都是:硬币正面朝上的概率是多少?
这个看似简单的问题有两个主要且相互冲突的答案:1/2 和 1/3。
我们一起看看大模型们是怎么解读的:
文心 4.5 Turbo 准确地描述了睡美人悖论,也对两种观点做出了清晰的解释:

豆包的回答也很不错,将实验的核心设定、两种观点的科学依据、争议点都表达得很清楚,并且给出最终总结:睡美人悖论目前没有“唯一正确答案”。

Gemini 2.5 Pro先描述了实验的规则,然后重点且详细地描述了两种主要观点和其科学依据,非常清晰且具体,还展示了“更强大的论证”。
最后也给了我们一个结论:从科学视角来看,1/3这个答案更具指导意义。
虽然看起来……有理有据,但不好意思,结论是错误的。

Intern-S1完整描述了问题设定、两种主要观点和争议根源与结论。它对核心观点的解析更为细致,分为核心逻辑、数学支持、哲学依据三个方面。
比较突出的是,它给了一个相关扩展与应用的板块,全是知识点。


揭秘Intern-S1
从几轮实测下来看,在科研场景里,Intern-S1(也就是书生模型)还是非常不错的,表现完全媲美国际顶尖模型,甚至在部分问题上比通用模型还要答得好

体验地址:https://chat.intern-ai.org.cn
Intern-S1以MoE架构为基础,拥有2350亿参数的语言模型部分(Qwen3)和60亿参数的视觉编码器(IntrenViT),总规模2410亿。
5T的训练数据集超过一半是专业领域知识,上下文长度给到128K tokens,不仅能一口气读完好几篇顶会论文,还能前后串联分析。
一个科研图表,Intern-S1能先读出数据趋势,再结合文字解释背后的逻辑。不仅知道图里显示什么,还能解读出这代表了什么物理过程,甚至能帮你推导下一步怎么做实验。
Intern-S1首创了跨模态科学解析引擎,针对不同模态的数据自适应地进行分词编码。对化学分子式、蛋白质序列等特殊序号提供了更高效的编码表示,比之前的压缩率提升了70%以上,也让Intern-S1拥有了看懂专业、复杂数据的能力。
为了兼顾通用性与专业性,在不同的科学任务领域,Intern-S1提出”通专融合同的训练范式:
-
利用海量的通用科研数据拓展模型知识广度;
-
训练众多领域专家模型生成高可读性、思维路径清晰的专业数据,并由定制的领域智能体验证其质量。
通过这一闭环机制反哺预训练,Intern-S1同时具备了强大的通用推理能力和多项顶尖的专业能力,实现了一个模型解决多种专业任务的突破。
Intern-S1在模型后期训练中引入了大规模多任务强化学习框架Inte。算法上则主打“混合奖励”——能验证的任务就用规则和验证器给奖励。这套体系让它的训练能耗只有Grok 4的1%,性能却毫不逊色。

写在最后
Intern-S1会不会成为科研多模态的标准答案?现在下结论还早,但它让我们看到了另一条路径——不是一味做大模型拼参数,而是从实际需求出发,去啃那些真正难但有价值的应用场景。
Intern-S1这个路子和前几年大家追求通用能力的方向不太一样。
GPT、Gemini、Claude它们当然强,对话、代码生成都很成熟。但你要让它们认真分析一张科研图谱,或者辅助设计一场实验,结果经常是不稳定、没逻辑,复杂的公式对它们来说就是乱码。
Intern-S1反其道而行,从科研这个难啃的点切入,把多模态能真正用在文献解析、实验辅助这些”高压区“,也打开了一条通往“专业型AI”的可能性通道。
你觉得下一个AI风口,会不会就是这种垂直突破?欢迎评论区分享你的观点。
如果觉得内容不错,记得给我们个一键三连,感谢
(文:沃垠AI)