
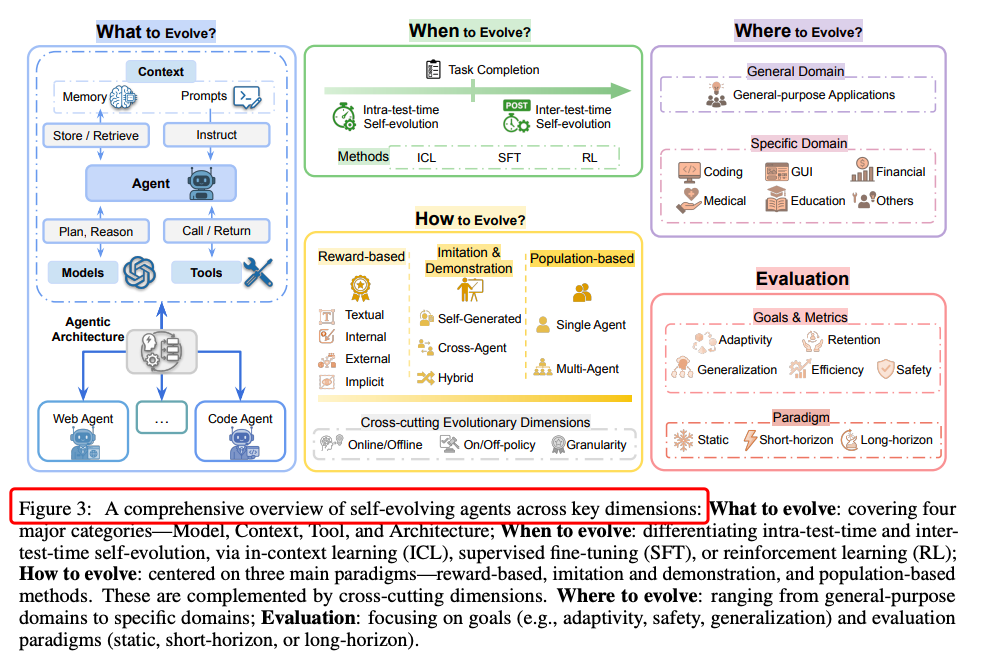
一、什么要进化?
探讨代理系统中哪些部分可以进化,包括模型、上下文(如记忆和提示)、工具和架构。
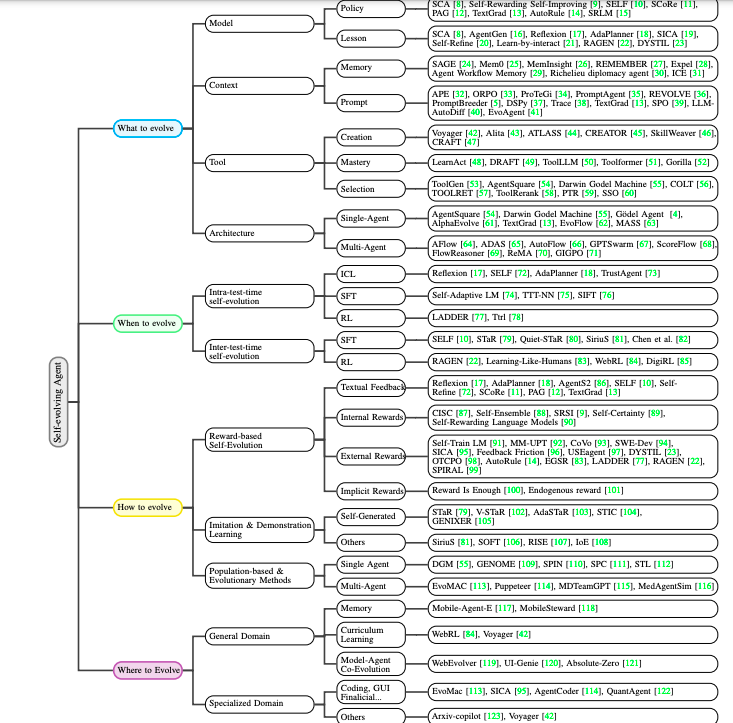
模型
-
自生成监督学习:通过角色交替生成问题和解决方案,利用成功轨迹微调模型参数。
-
交互反馈学习:将执行轨迹或自然语言批评作为奖励信号,结合监督微调和强化学习框架,实现持续策略改进。
-
文本反馈学习:将非结构化文本反馈视为可微训练信号,影响提示设计和模型参数。
上下文
-
记忆进化:积累知识、回忆事件并根据经验调整行为,如基于遗忘曲线的记忆管理、动态记忆更新和经验总结。
-
提示优化:改进代理输入给底层模型的指令,无需修改模型权重,如基于搜索的优化、迭代重写和自然语言修正。
工具
-
自主发现和创建:克服固定工具集的限制,按需创新,如探索性发现、反应式创建和结构化框架。
-
掌握工具:通过迭代改进掌握新生成的工具,确保工具的可靠性和实用性。
-
管理工具:高效管理和选择工具,如工具编码和架构优化。
架构
-
单代理系统优化:优化LLM调用节点和代理的整体架构,如节点优化和架构优化。
-
多代理系统优化:优化代理之间的组织和通信结构,如工作流优化和多代理协同进化。
二、何时进化(When to Evolve):
分析进化发生的时间点,分为测试时进化(intra-test-time)和测试间进化(inter-test-time)。
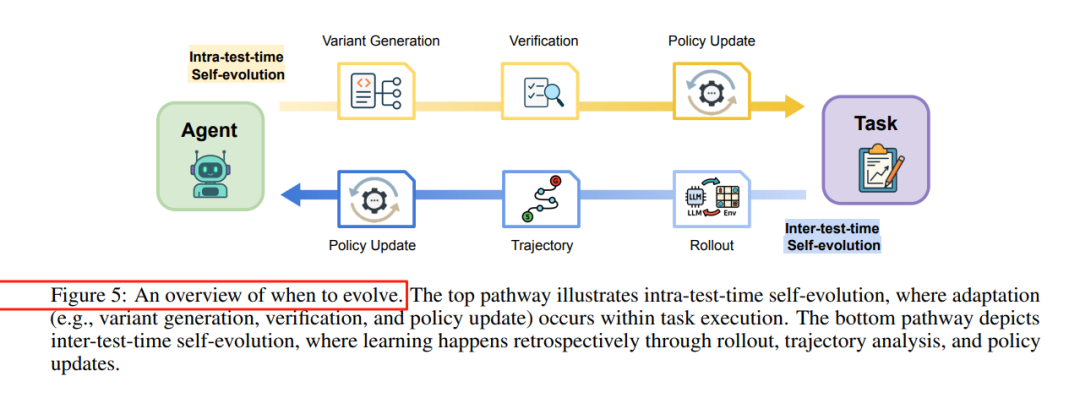
测试时进化
-
基于上下文学习(ICL):动态调整模型的上下文窗口,实现即时适应,无需修改模型参数。例如,AdaPlanner通过自我反思和计划修订,动态调整策略。
-
监督微调(SFT):代理通过生成“自我编辑”指令,直接对模型参数进行即时调整。例如,Self-Adaptive Language Modeling通过强化学习训练模型生成有效的自我编辑指令。
-
强化学习(RL):代理在遇到超出当前能力范围的问题时,通过生成相关问题变体并进行针对性的强化学习,实现即时技能获取。例如,LADDER通过测试时强化学习(TTRL)机制,针对特定问题类别进行强化学习。
测试间进化
-
基于上下文学习(ICL):将之前任务的执行结果和反馈作为上下文信息,指导未来任务的解决。例如,Wang等人通过从代理行动历史中诱导工作流,并将其纳入后续任务的上下文中,实现知识的积累和复用。
-
监督微调(SFT):通过生成合成数据和自我评估,实现迭代自我改进。例如,SELF通过自我反馈和自我修正能力,迭代生成对未标记指令的响应,并通过自我批评进行优化。
-
强化学习(RL):利用无约束的计算资源,通过与环境的广泛交互和复杂的课程设计,优化代理策略。例如,RAGEN和DYSTIL通过在线强化学习,优化多轮交互任务中的代理策略。
三、如何进化(How to Evolve):
总结引导进化适应的方法,包括基于奖励的进化、模仿和示范学习、基于种群和进化的方法。

基于奖励的进化
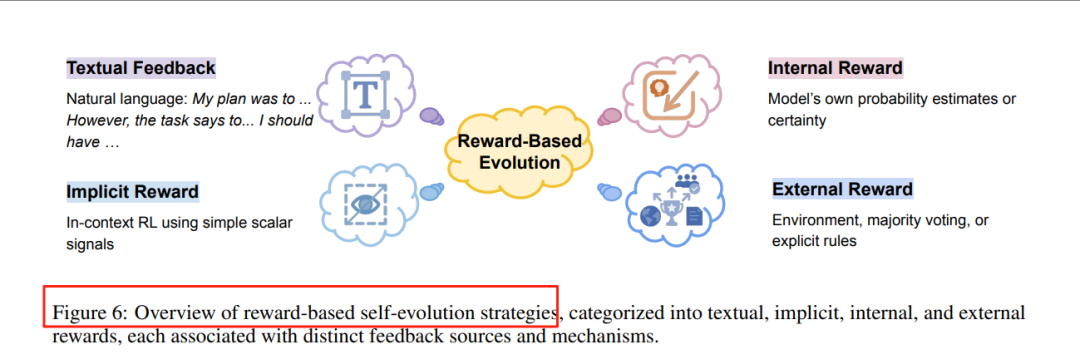
-
文本反馈:利用自然语言反馈指导代理的改进。例如,Reflexion通过自然语言反思改进代理的行为。
-
内部奖励:利用模型自身的置信度或概率估计作为奖励信号。例如,Self-Rewarding Self-Improving通过内部奖励机制实现自我改进。
-
外部奖励:利用外部环境提供的奖励信号。例如,SWE-Dev通过环境反馈优化代理的行为。
-
隐式奖励:利用模型的内在奖励机制,如“Reward Is Enough”通过简单的标量信号实现奖励学习。
模仿与示范学习
-
自生成示范学习:代理通过生成自己的训练数据来改进行为。例如,STaR通过生成和验证问题解决方案来提升推理能力。
-
跨代理示范学习:代理通过学习其他代理的示范来改进行为。例如,SiriuS通过多阶段改进和反馈整合来提升性能。
-
混合示范学习:结合自生成和跨代理示范学习。例如,SOFT通过内部反馈进行优化,提升代理的性能。
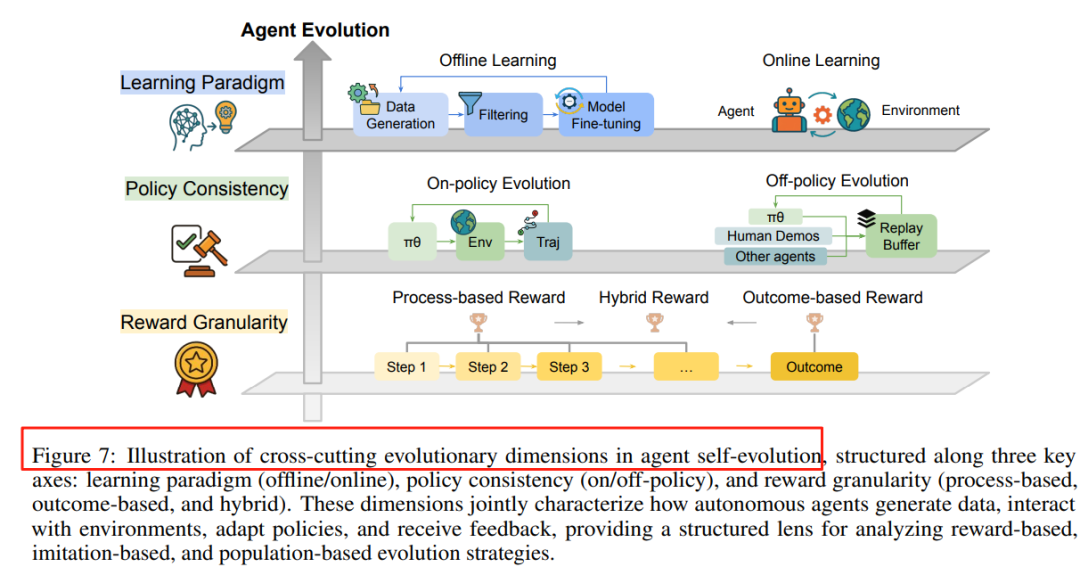
基于种群和进化的方法
-
单代理进化:通过种群机制进化单个代理。例如,Darwin Gödel Machine通过开放性进化实现自我改进。
-
多代理进化:通过种群机制进化多个代理。例如,EvoMAC通过多代理协同进化提升性能。
-
混合进化方法:结合单代理和多代理进化。例如,AutoFlow通过自适应搜索优化代理工作流。

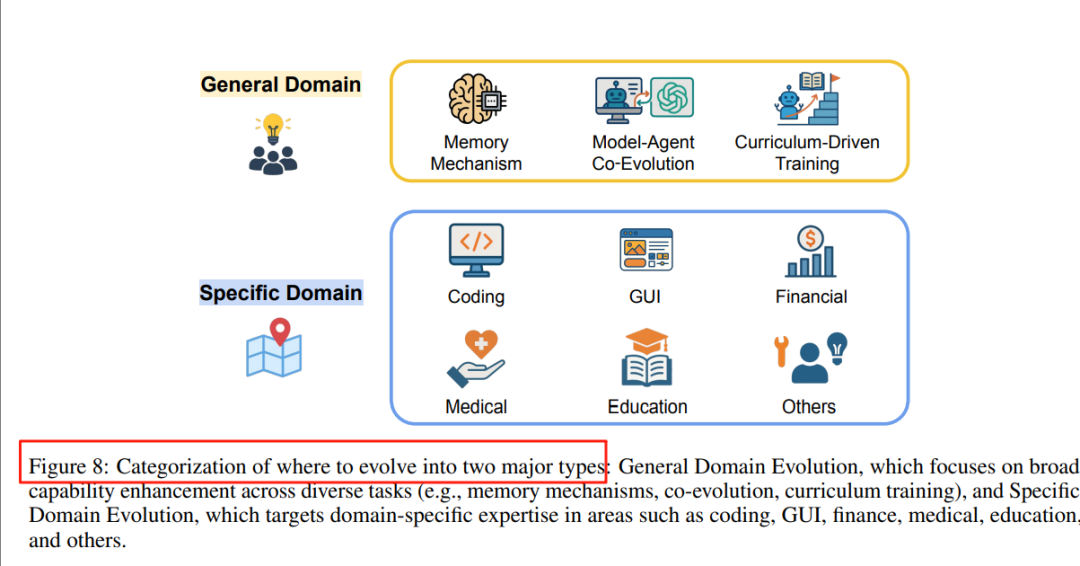
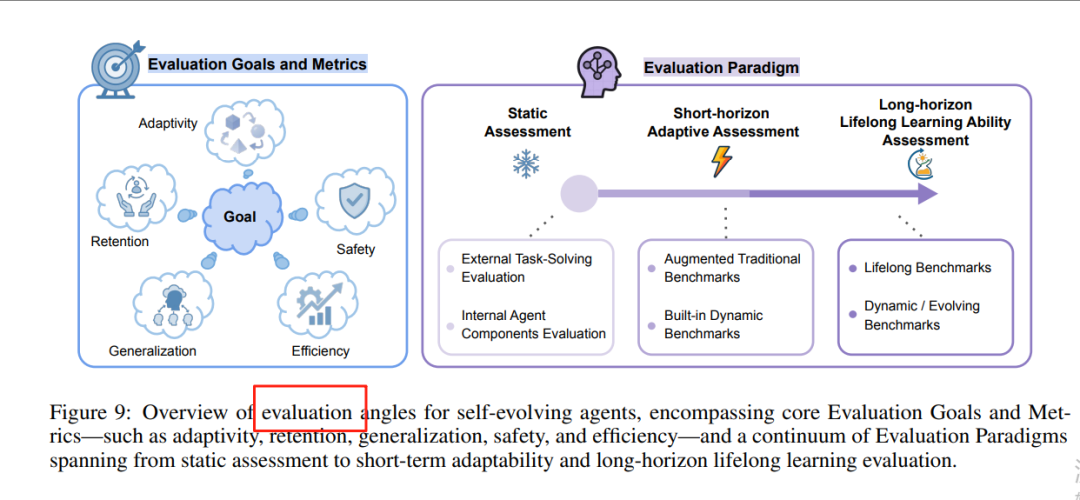
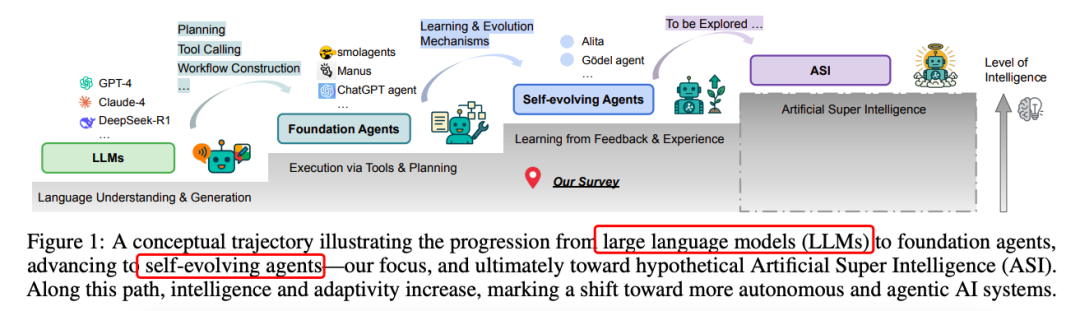
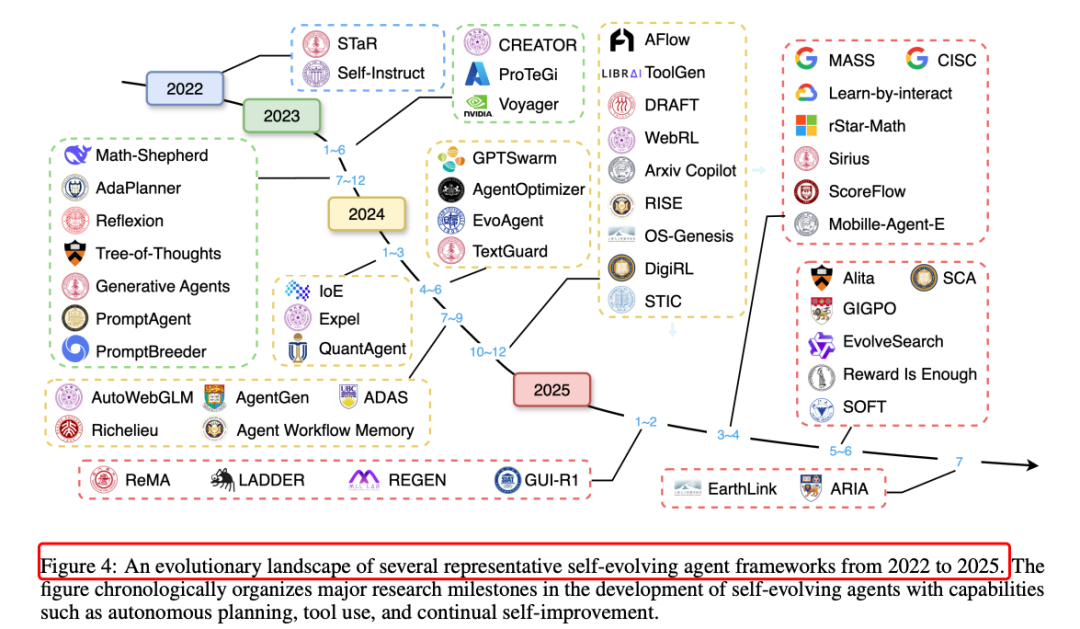
https://arxiv.org/pdf/2507.21046Github Repo: https://github.com/CharlesQ9/Self-Evolving-AgentsA Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
(文:PaperAgent)