

这一周是国产开源LLM集中大爆发的一周:GLM-4.5、Qwen3的5连发、Step3等等,接连发布,PaperAgent专题梳理盘点:

一、GLM-4.5
GLM-4.5发布,这是新一代开源SOTA模型,专为智能体应用打造,采用混合专家架构,总参数量3550亿,激活参数320亿,具备思考和非思考两种模式,综合能力在推理、代码、Agentic智能体领域达到开源最佳水平,
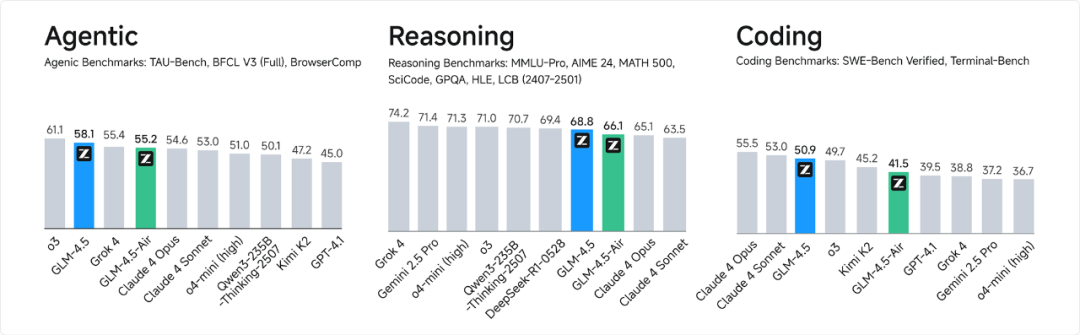
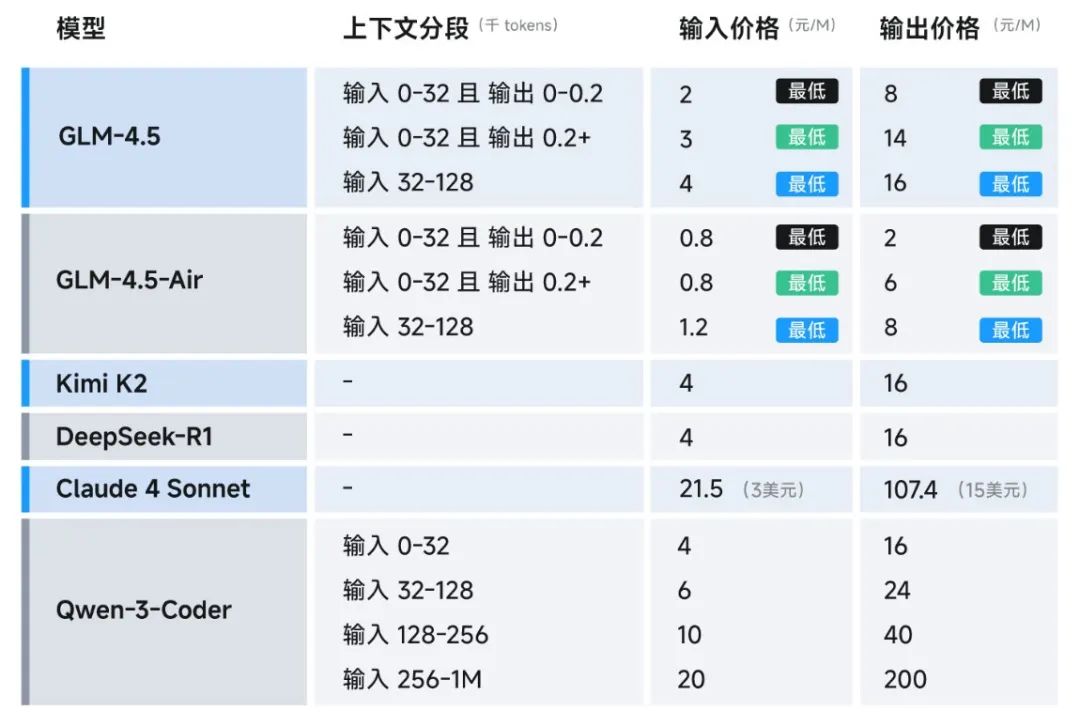
API调用价格低至输入0.8元/百万tokens、输出2元/百万tokens,高速版生成速度可达100tokens/秒,已在Hugging Face和ModelScope开源,支持全栈开发和工具调用,兼容主流代码智能体框架。
https://hf-mirror.com/zai-org二、Qwen3的5连发
-
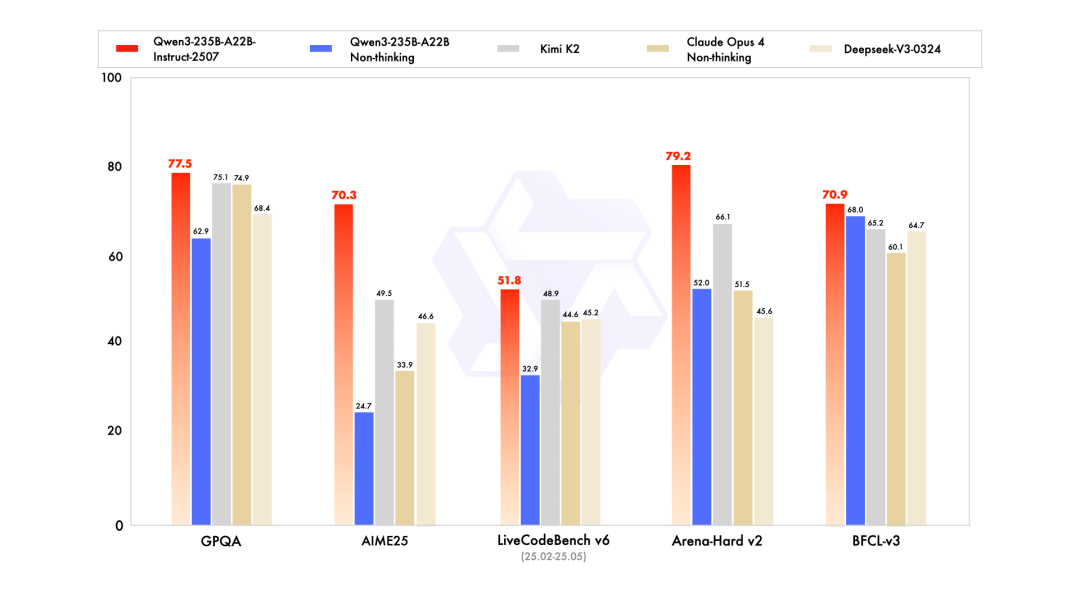
7.22 Qwen3模型升级为Qwen3-235B-A22B-Instruct-2507版本,显著提升了通用能力、多语言知识覆盖、用户偏好契合能力及长文本理解能力,并在魔搭社区和HuggingFace开源更新。
-
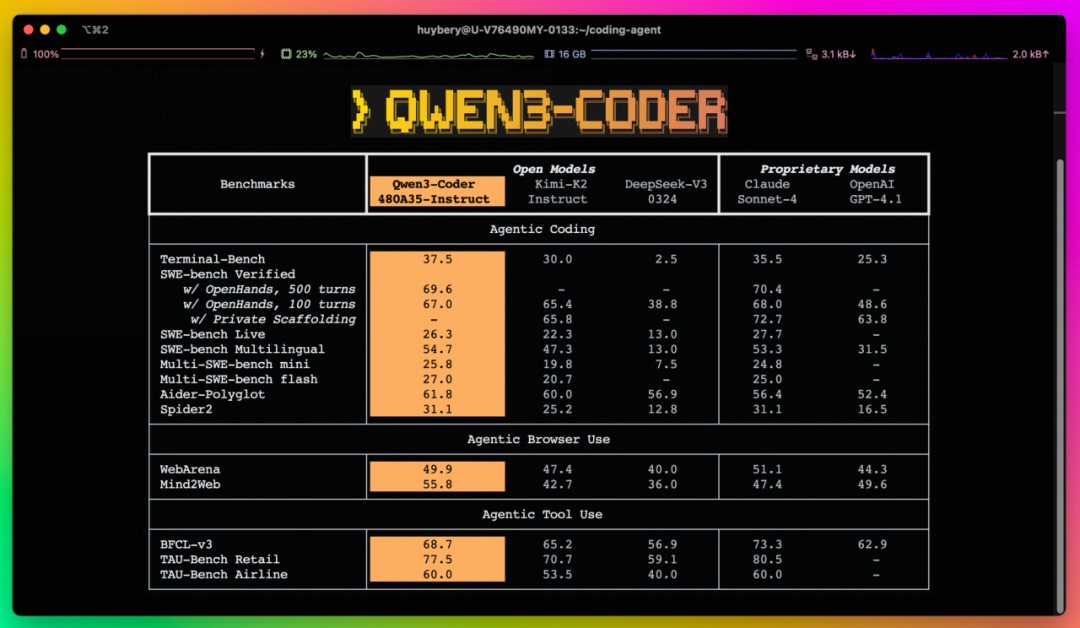
7.23 Qwen3-Coder发布,这是480B参数激活35B参数的MoE代码模型,支持256K上下文扩展至1M,具备卓越的代码和Agent能力,在开源模型中表现优异,同时推出Qwen Code命令行工具,可与Claude Code、Cline等结合使用,支持通过API调用,未来还将探索更多尺寸和自改进能力。
-
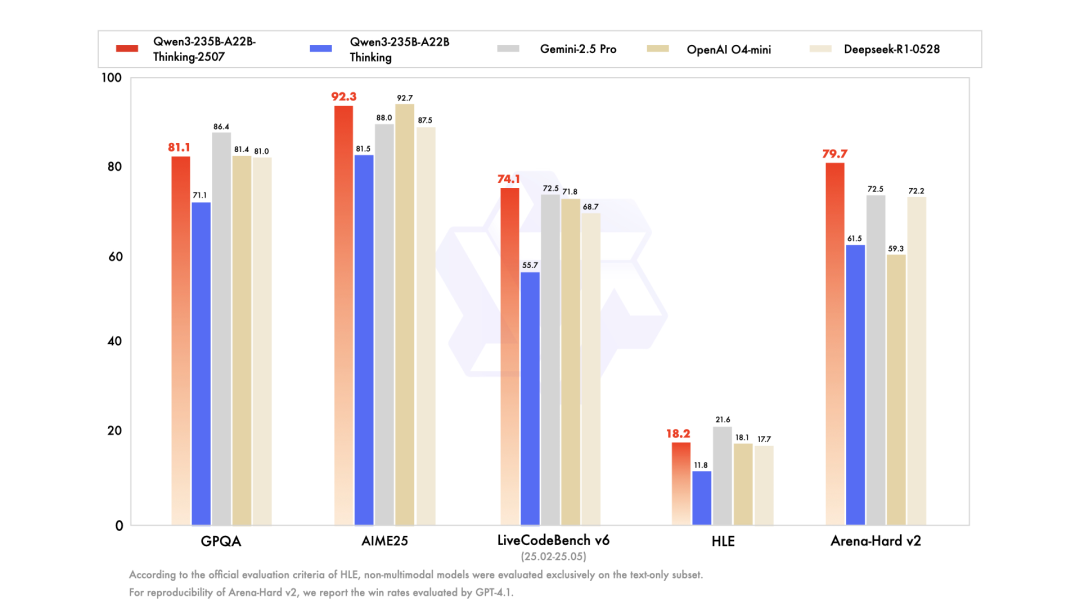
7.25 Qwen3-235B-A22B-Thinking-2507推理模型正式推出,其在编程、数学等核心能力及知识、创意写作、人类偏好对齐、多语言能力等通用能力上实现飞跃,支持256K长文本理解,已在魔搭社区、Hugging Face开源并采用Apache2.0协议,可免费商用。
-
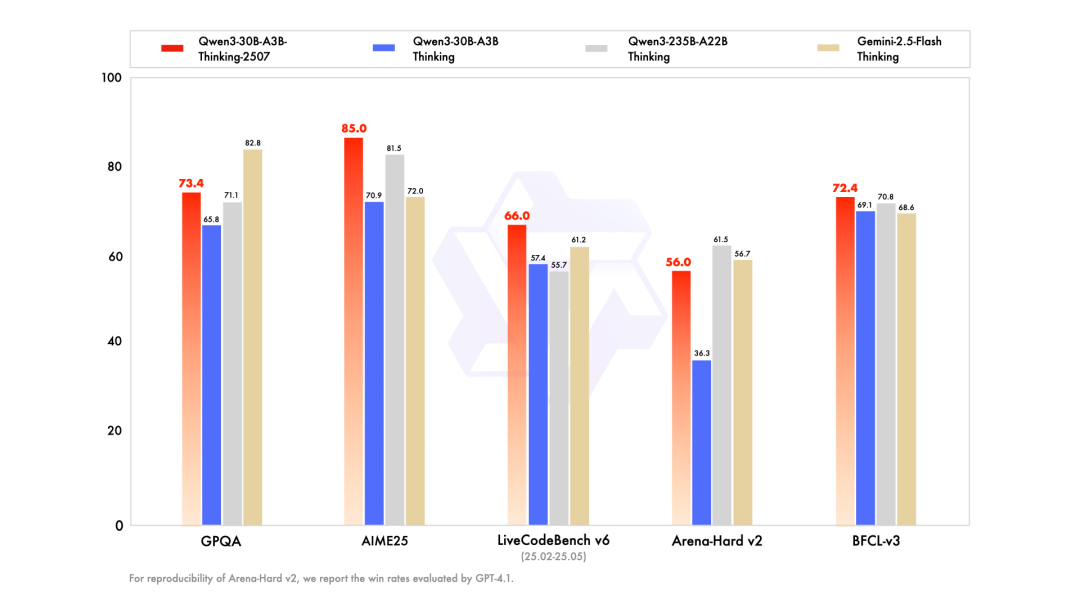
7.30 Qwen3-30B-A3B模型更新为Qwen3-30B-A3B-Instruct-2507和Qwen3-30B-A3B-Thinking-2507,前者非思考模式下性能媲美顶尖闭源模型,通用能力、多语言知识覆盖、用户偏好对齐及长文本理解能力大幅提升;后者推理能力显著增强,数学、代码、知识水平、通用能力均超越前代,支持256K原生上下文(可扩展至1M),已在魔搭社区和Hugging Face开源。
-
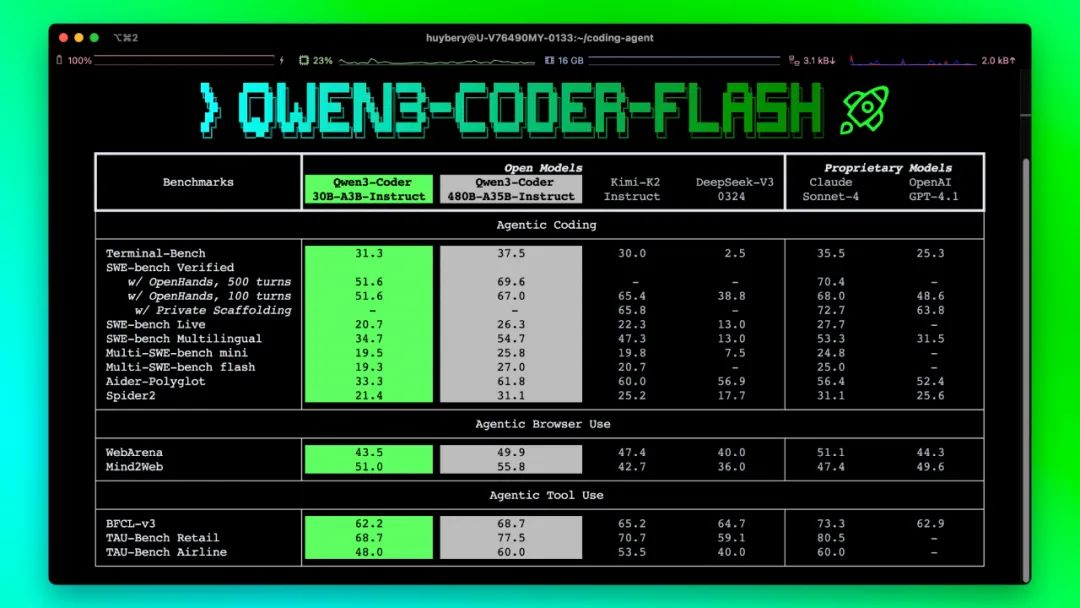
8.1 Qwen3-Coder-Flash(Qwen3-Coder-30B-A3B-Instruct)发布,这是“甜品级”编程模型,拥有超强Agent能力,支持256K原生上下文(可扩展至1M),适配多平台,已在魔搭社区和Hugging Face开源,可自由部署。
https://hf-mirror.com/Qwen/models三、阶跃星辰Step3
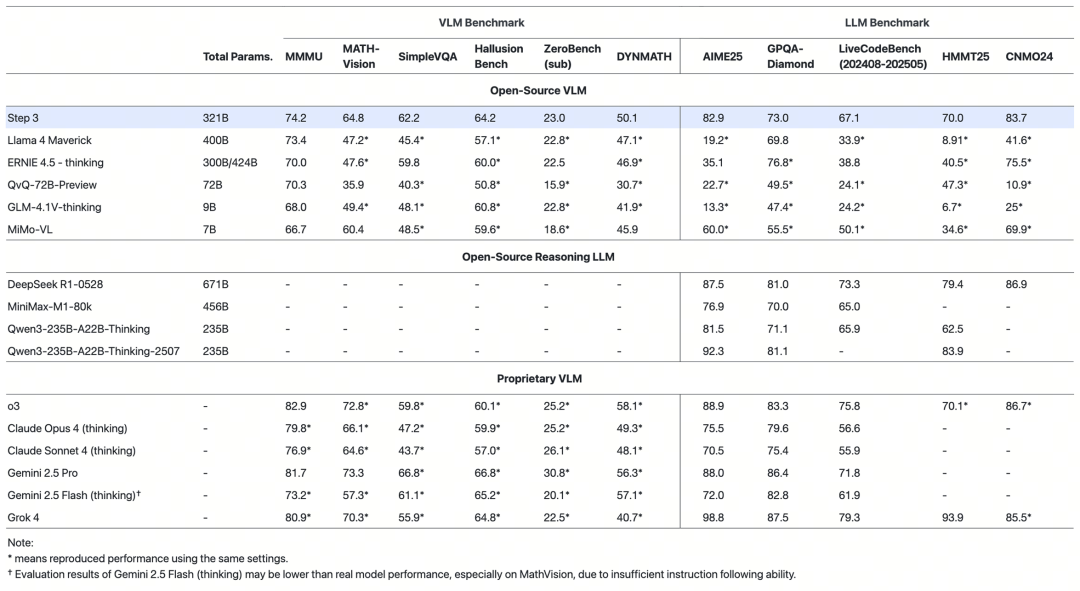
阶跃星辰Step 3正式开源,这是一个总参数量321B、激活参数量38B的多模态推理模型,采用MoE架构,,通过MFA和AFD优化显著提升推理效率,支持跨硬件部署,已在Github、Hugging Face和魔搭ModelScope开源,API上线开放平台,限时折扣中。
https://hf-mirror.com/stepfun-ai/step3四、混元3D大模型
腾讯发布混元3D世界模型1.0(HunyuanWorld-1),这是首个支持物理仿真的开源3D世界生成系统,可依据文本或图像输入生成沉浸式、可交互的3D场景,具备360°沉浸体验、工业级兼容性和原子级交互三大优势,支持“文生世界”和“图生世界”两种生成方式,应用于VR、游戏开发、物体编辑和物理仿真等领域。
https://hf-mirror.com/tencent/HunyuanWorld-1https://3d-models.hunyuan.tencent.com/world/体验地址:https://3d.hunyuan.tencent.com/sceneTo3D
(文:PaperAgent)