

AI 的发展正经历一场深刻的进化:从最初解决“知识局限”的 RAG,到赋予模型“行动能力”的 AI Agent,我们正迈向一个更宏大、更系统的终极形态——上下文工程 (Context Engineering)。这不再是关于“提示词技巧”或“检索增强”的战术优化,而是构建下一代生产级 AI 应用的系统性架构科学。
本文将深度剖析这场进化的内在逻辑,并结合最新发布的顶级综述《A Survey of Context Engineering for Large Language Models》,为你揭示:
-
1. AI 的进化三部曲: 为何 RAG 只是起点,Agent 是过程,而上下文工程才是未来? -
2. 核心矛盾: 为什么 LLM “读得懂”复杂信息,却“写不出”同等水平的内容?揭示驱动技术演进的根本性“理解-生成鸿沟”。 -
3. 终极蓝图: 首次系统性拆解上下文工程的框架,理解其如何统一 RAG、Agent、记忆系统和工具使用,构成 AI 应用的“中枢神经系统”。
这篇文章,是你理解 AI 应用开发下半场竞赛规则的必备指南。
AI 应用的进化之路:从 RAG 到 Agent
要理解上下文工程的革命性,我们必须先回顾 AI 应用是如何一步步走到今天的。这是一条从“被动回答”到“主动行动”的清晰进化路径。
起点:RAG,让 AI 首次连接真实世界
大语言模型(LLM)的诞生,如同创造了一个个拥有渊博知识但与世隔绝的“缸中之脑”。它们强大,但被囚禁在预训练数据的静态牢笼里,面临三大原罪:
-
1. 知识过时: 无法获知训练截止日期后的新信息。 -
2. 事实幻觉: 在知识盲区会“一本正经地胡说八道”。 -
3. 领域局限: 缺乏企业内部的私有领域知识。
为了打破这层壁垒,检索增强生成(Retrieval-Augmented Generation, RAG) 应运而生。这是 AI 走出象牙塔、连接真实世界数据的第一座桥梁。其核心思想简单而有效:在回答问题前,先从外部知识库(如公司文档、数据库)中检索相关信息,然后将这些信息连同问题一起“喂”给 LLM,让它基于这些新鲜、准确的“食材”来生成答案。
然而,初代的“朴素 RAG”(Naive RAG)很快就暴露了其局限性。它就像一个只会用一张大网捕鱼的渔夫,虽然能捞上东西,但网里往往鱼龙混杂,甚至混入了垃圾。用户模糊的提问、低效的检索算法、未经处理的信息块,都会导致“垃圾进,垃圾出”的窘境。
进化:Agent 崛起,AI 学会了“动手”
RAG 解决了 LLM 的“知识输入”问题,但一个新的、更大的野心正在浮现:AI 能否不仅仅是信息的搬运工和整合者,而是成为一个能自主规划、使用工具、执行任务的行动者?
AI Agent(智能体) 的概念应运而生。它将 LLM 从一个被动的“应答机”变成了一个主动的“决策大脑”。Agent 的核心是 “思考-行动”循环(Reasoning-Acting Loop),经典的 ReAct 框架就是其典型代表。一个成熟的 Agent 系统通常具备四大核心能力:感知(Perception)、规划(Planning)、记忆(Memory)和行动(Action)。
在这个新范式下,RAG 的角色发生了根本性转变——它从一个完整的解决方案,降级为了 Agent 工具箱里的一件工具。
一个 Agent 在解决复杂问题时,可能会进行如下操作:
-
1. 思考(Planning): 分析任务“帮我预订下周三去上海出差的行程,并整理一份当地AI产业的调研报告。” -
2. 行动(Action – Tool Use): -
• 调用日历查询工具,确认“下周三”的具体日期。 -
• 调用航班/酒店预订 API,查询并预订行程。 -
• 调用RAG 工具(即一个内部 RAG 系统),从公司数据库和网络搜索引擎中检索关于“上海 AI 产业”的信息。 -
• 调用文档生成工具,将检索到的信息整理成报告。 -
3. 观察(Perception): 查看每个工具的返回结果,并根据结果进行下一步思考和行动,这个过程可能需要动用**记忆(Memory)**来记录中间状态。
Agent 的出现,让 AI 应用的复杂度指数级增长。我们面临的挑战不再仅仅是“如何给模型提供正确的信息”,而是“如何让模型学会自主规划、选择和使用一系列工具来获取和处理信息”。这标志着我们已经踏入了系统工程的深水区,需要一个更宏大的理论框架来统一这一切。
新范式:上下文工程,AI 应用的系统科学
从 RAG 的精密化到 Agent 的崛起,背后贯穿着一条清晰的主线:我们与 LLM 的交互,早已超越了简单的“一问一答”。为了构建真正强大的 AI 应用,我们必须管理一个由指令、外部知识、工具、记忆和环境状态组成的、动态变化的信息流。
这正是 上下文工程(Context Engineering) 的核心。最新发布的权威综述《A Survey of Context Engineering》为我们提供了该领域的首个形式化定义。
上下文工程,是关于如何系统性地设计、优化和管理 LLM 在推理时所需信息有效载荷的正式学科。
它将过去零散的概念(RAG、Agent、记忆、工具使用)整合进一个统一的理论框架之下。
从字符串到系统:上下文的重新定义
上下文工程首先在数学上重新定义了“上下文”。它不再是一个简单的文本字符串 Context = prompt,而是一个由动态组装函数 𝒜 精心构建的结构化信息集合:
𝐶 = 𝒜(𝑐_instr, 𝑐_know, 𝑐_tools, 𝑐_mem, 𝑐_state, 𝑐_query)
这里的每一个组件 𝑐,都代表着 AI 系统与世界交互的一个关键维度:
-
• 𝑐_instr: 系统指令 (System Prompt),定义了 AI 的角色、规则和目标。 -
• 𝑐_know: 外部知识,主要由 RAG 系统提供,用于打破模型的知识局限。 -
• 𝑐_tools: 可用工具,Agent 的核心能力来源,使其能够与 API 和外部系统交互。 -
• 𝑐_mem: 记忆,包括短期(对话历史)和长期(持久化存储),赋予 Agent 学习和个性化的能力。 -
• 𝑐_state: 当前状态,无论是用户、世界还是多智能体系统的状态,让 Agent 具备环境感知能力。 -
• 𝑐_query: 用户即时请求。
因此,上下文工程的终极目标,是找到一个最优的函数集合 ℱ = {𝒜, Retrieve, Select, ...},在满足上下文长度等约束的条件下,最大化任务奖励的期望值。这本质上是一个复杂的系统级优化问题,而非简单的文本撰写。
|
|
|
|
| 数学模型 | C = prompt
|
C = 𝒜(...)
|
| 优化目标 |
prompt 字符串 |
ℱ (组装、检索、选择…) |
| 复杂性 |
|
系统级优化
|
| 状态管理 |
|
天生有状态
|
| 可扩展性 |
|
|
| 错误分析 |
|
|
宏伟蓝图:上下文工程的完整分类法
为了系统性地理解这门新兴学科,该综述论文提出了一个全面的分类框架,将整个领域划分为基础组件 (Foundational Components) 和 系统实现 (System Implementations) 两大层次。这不仅是一个分类,更是构建高级 AI 应用的路线图。
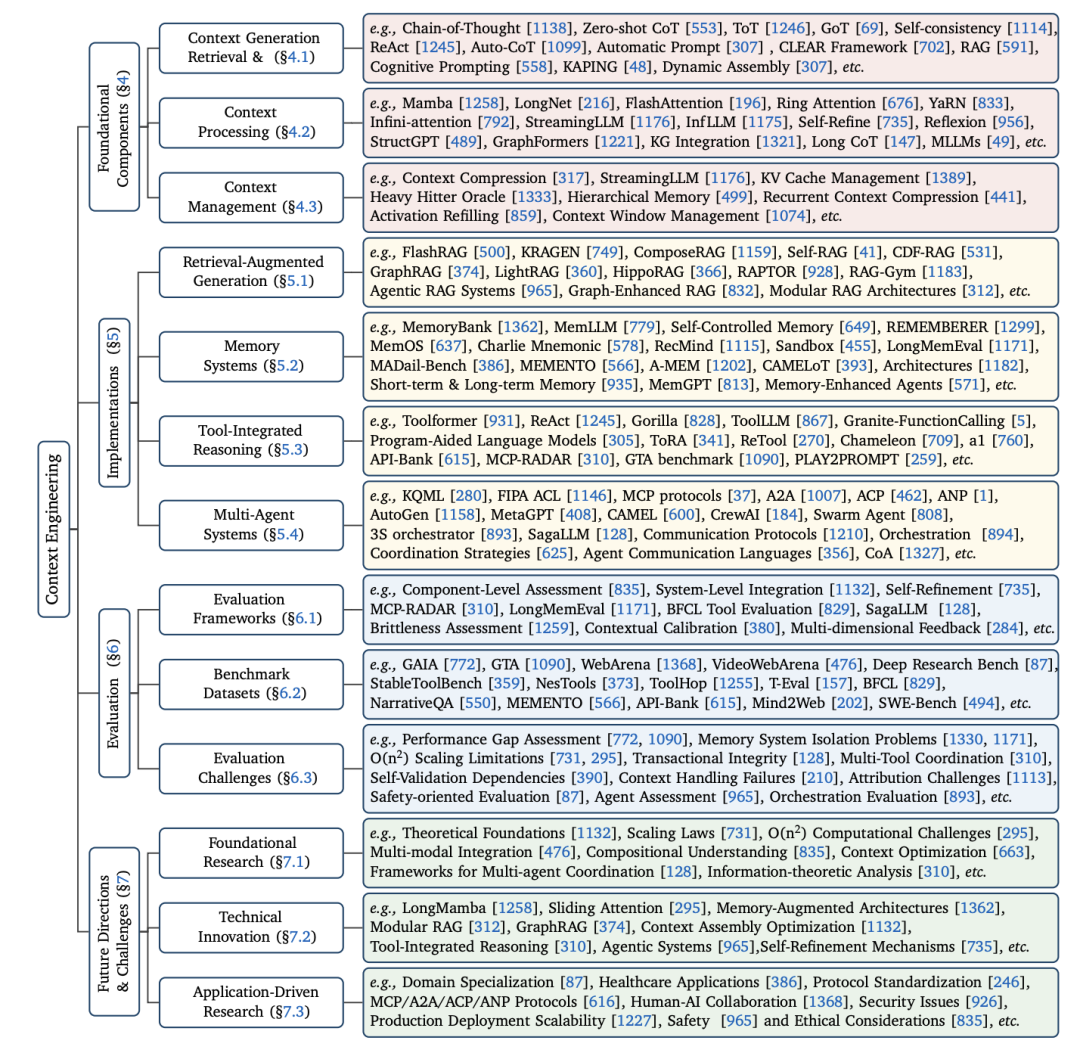
核心支柱:基础组件 (Foundational Components)
这些是构建一切复杂系统的“原子能力”,是上下文“从无到有”再到“优化”的全过程。
一、上下文检索与生成 (Context Retrieval & Generation)
(文:子非AI)