
“ 大模型应用提示词是核心,但智能体中大模型是核心,大模型会接收用户输入和工具调用结果,同样也会返回思考过程和调用参数。”
ReAct Agent基于思考-行动-观察的智能体,简单来说就是让智能体有更强的规划和逻辑推理能力,并且能够依靠自身去解决问题。
在前面的几篇文章中介绍了关于智能体的内容,以及大模型与提示词之间的关系;而今天我们再来仔细分析一下智能体的运作流程。
总之一句话,智能体的核心就是LLM大模型,其主要操作载体是Prompt提示词。
在应用大模型的过程中,提示词是使用大模型的唯一入口;而为了激发大模型的潜力,因此根据不同的应用场景,出现了多种不同的提示词范式;包括思维链(Cot),ReAct,In learning context等多种范式。
从根本上看,所有与大模型的交互确实都通过提示词(Prompt)实现,模型本身仅暴露一个文本输入/输出接口。In-Context Learning (ICL)、Chain-of-Thought (CoT) 等技术本质上都是针对提示词的结构化设计范式,旨在更高效地激发模型能力。
不同范式的核心差异:信息注入方式
虽然底层统一,但不同范式通过提示词向模型注入不同类型的信息结构:
| 范式 |
|
|
|
|---|---|---|---|
| Zero-Shot |
|
指令: <任务描述> |
|
| ICL (Few-Shot) |
|
示例输入→输出\n...\n新输入→? |
|
| CoT |
|
问题:... 让我们一步步思考: ... |
|
| Self-Consistency |
|
|
|
| Tool-Use |
|
|
|
| ReAct |
|
Thought:... Act:... Obs:... |
|
为什么需要多种范式?
因单一线性提示词无法覆盖所有任务需求,需通过结构化设计解决:
| 任务痛点 | 适配范式 |
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
所以,从本质上来说任何对大模型的操作都是基于提示词的操作。
智能体
智能体的运作流程说起来很复杂,但其实也很简单;简单来说就是,把大模型当做一个“人”或者员工,然后把需要的工具给它(tools,本质上就是一个函数),然后告诉它你的需求是什么;之后,就完全由它自己理解你的需求,然后借助自身能力或者使用外部工具来完成任务。
首先,初始化大模型,并把工具绑定到大模型,
# 初始化模型model = init_chat_model("model")tools = ['工具集']# 绑定工具model = model.bind_tools(tools)
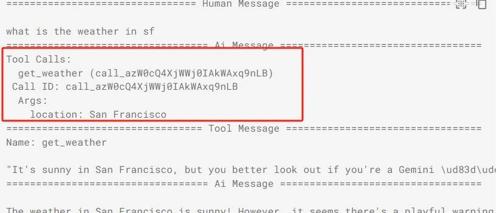
其次,大模型接收到用户输入,并理解需求判断是自身能够解决还是需要调用外部工具解决;如下图所示查询天气,就需要调用天气查询工具,在langchain中,如果需要调用工具,则大模型会返回tool_calls工具列表。
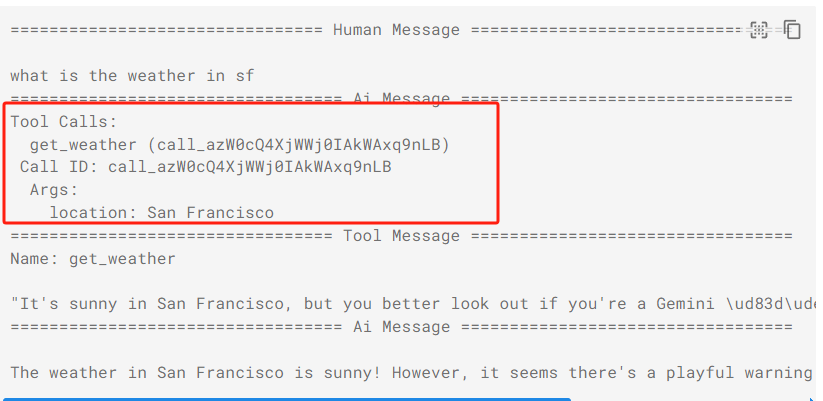
当大模型返回tool_calls调用工具时,langgraph就会通过边流转到ToolNode节点,然后在工具节点中调用外部接口并获取结果。
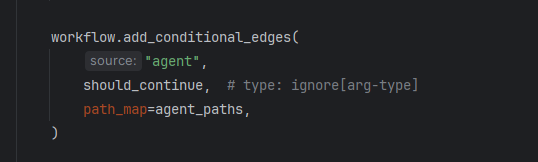
当工具调用返回结果之后,再把结果传给大模型,让大模型判断结果是否能解决用户的问题;如果不行,则继续下一步;否则,则结束;当然,为了防止无限循环调用导致任务无法结束,因此还增加了默认的超时次数,当超过25次问题还没解决,则直接抛出异常。
# Define our tool node# 工具执行过程def tool_node(state: AgentState):outputs = []# LLM会返回调用工具的函数名 以及其参数for tool_call in state["messages"][-1].tool_calls:tool_result = tools_by_name[tool_call["name"]].invoke(tool_call["args"])outputs.append(ToolMessage(content=json.dumps(tool_result),name=tool_call["name"],tool_call_id=tool_call["id"],))return {"messages": outputs}
(文:AI探索时代)