
强化学习


百万小时训练!这个中文TTS模型让AI播客告别”机械音”,效果堪比真人主播

MOSS-TTSD 是由清华大学语音与语言实验室开发的开源口语对话语音生成模型,支持中文和英文双语生成,并具备零样本语音克隆能力,广泛应用于 AI 播客、访谈、新闻报道等多种场景。
Karpathy戳破强化学习神话,首提AI复盘式进化!暴力试错将死

Karpathy提出强化学习并非通往AGI的最佳途径,建议采用像人类复盘的学习方法。他认为现有强化学习方法效率低且与人类迭代机制存在差距。他提出了一个新框架来改进当前的强化学习技术。
Karpathy:强化学习「有点问题」,突破还需新算法

Karpathy指出强化学习虽然有效,但其机制存在不足之处。他认为人类在解决问题时会有反思过程,而当前的学习框架缺乏这一环节。他提出了一种新的算法框架来填补这些空白。
马斯克20亿送Grok 4上火星!20万GPU造宇宙大脑,一句话生成3D黑洞

Grok 4发布仅72小时,就惊艳了硅谷。它能在短短2分钟内部署完成一款游戏,并通过1条指令生成整段动画。马斯克的xAI团队投资20亿美元SpaceX,计划未来把Grok模型送上火星。
下一代 AI 系统怎么改?让 AI 自己改?!

下一代AI系统如何改进?让AI自己改!DGM验证了怎样的路径?‘自进化’范式有哪些特征?Sakana AI和UBC提出‘达尔文哥德尔机’探索AI自主学习能力
lmpo:一个简洁易懂的语言模型策略优化GitHub项目
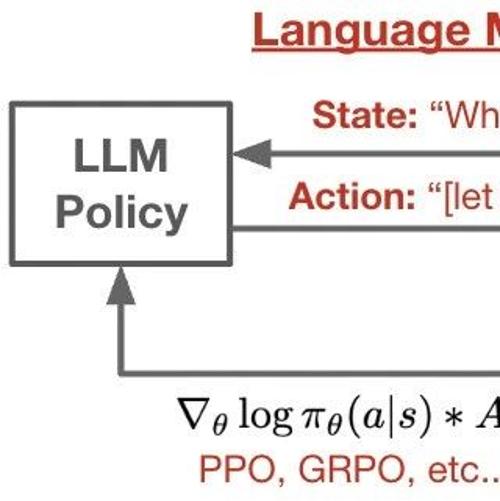
一个简洁易懂的语言模型策略优化GitHub项目(lmpo),通过强化学习提升特定任务表现,核心代码约400行,支持多主机TPU训练和多种LLM强化学习环境。
Kimi首个万亿参数模型开源!免费可用,超强Agent推理,附实测体验
国内大模型独角兽月之暗面发布并开源了其最新一代MoE架构基础模型Kimi K2,总参数量达到1万亿(1T),并在SWE Bench Verified、Tau2和AceBench三项基准测试中取得SOTA成绩。
阿里达摩院开源多模态医学大模型—灵枢
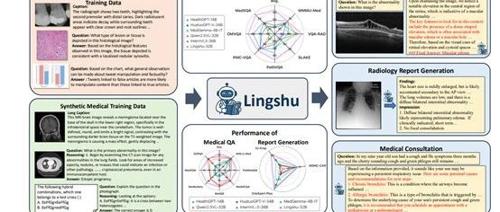
专注AIGC领域的专业社区,聚焦大语言模型在医疗领域的应用研究。目前大模型面临三大难题:医疗知识覆盖不足、幻觉风险高及推理能力欠缺。阿里达摩院开源统一多模态医学大模型灵枢,并详细介绍数据构建与训练方法。