
首个开源AI 3D结构化模型,零件级输出3D,AI真正懂了空间这个概念。

首个结构化3D生成模型PartCrafter发布,从单张RGB图像生成多个语义有意义且几何不同的3D网格。支持部件独立编辑、移除或添加,确保全局一致性与细节。
首个结构化3D生成模型PartCrafter发布,从单张RGB图像生成多个语义有意义且几何不同的3D网格。支持部件独立编辑、移除或添加,确保全局一致性与细节。
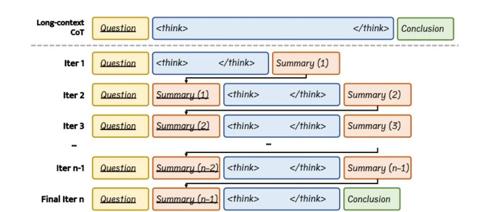
浙江大学和北京大学联合推出InftyThink模型,通过分段迭代推理和中间总结突破传统长推理任务限制,显著降低计算复杂度并保持推理准确性和效率。

银河通用宣布完成11亿元人民币融资,成为具身大模型机器人领域单笔最大融资。公司成立于2023年5月,已累计获得超24亿人民币融资,并推出全球首个预训练端到端具身大模型GraspVLA和GroceryVLA。

MLNLP社区是国内外知名的人工智能与自然语言处理社区,旨在促进学术界、产业界及爱好者的交流合作。近日,北京大学数学天才韦东奕在顶级期刊发表研究成果,《Forum of Mathematics, Pi》发布其关于非线性波动方程的研究。社区致力于为相关从业者提供交流平台。

该研究比较了DPO和GRPO在自回归图像生成中的应用效果,发现DPO在域内任务上表现更好,而GRPO在域外泛化能力上更出色。研究还探讨了不同奖励模型及扩展策略对这两种算法的影响。

三位数学家成功解决希尔伯特第六问题,从弹性碰撞的硬球粒子系统推导出宏观气体行为及流体方程,填补牛顿力学与玻尔兹曼方程间的逻辑鸿沟。

微软研究院、北大和清华联合提出强化预训练新范式RPT,通过RL训练提高LLMs预训练性能。该方法在OmniMATH数据集上优于现有模型,并且随着计算量增加预测准确性提升。

北京大学联合智元机器人团队提出CheckManual评测框架,专注于研究基于说明书的家电操作。该框架包含1107份不同内容的家电说明书,涵盖2211个可操作部位和1464个操作任务。通过OCR、多模态大模型解析说明文字及视觉信息,提出ManualPlan模型进行详细的操作规划,并实现与家用电器的真实交互。

