




在后训练阶段,则精心整理了一个包含13万个可验证的数学和编程问题的数据集用于强化学习,整合了一种由测试难度驱动的代码奖励机制,以缓解稀疏奖励问题,并采用了策略性的数据重采样方法来稳定训练过程。

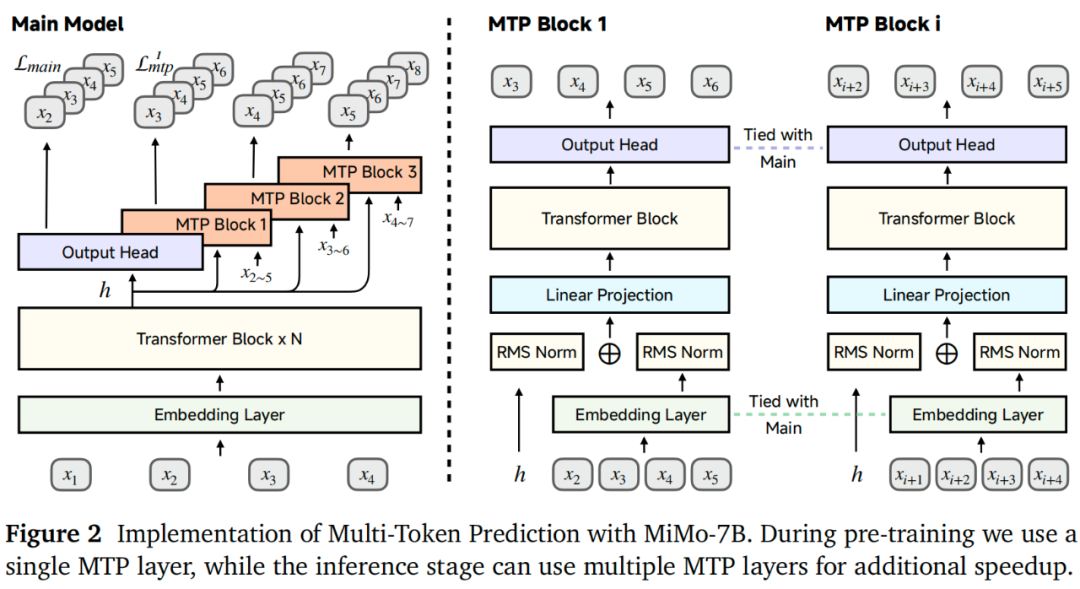
在强化学习(RL)基础设施方面,小米团队开发了一个无缝采样引擎,整合了连续采样、异步奖励计算以及提前终止机制,从而将GPU的闲置时间降至最低,实现了训练速度提升2.29倍,验证速度提升1.96倍。并且在vLLM(一种高效的语言模型推理库)中支持多词元预测(MTP),增强了强化学习系统中推理引擎的稳健性。
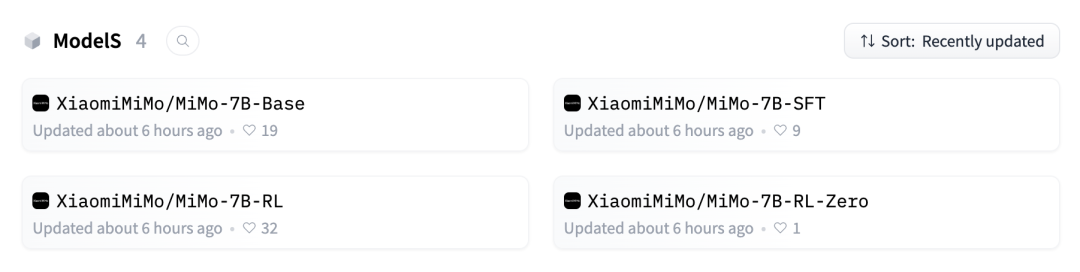
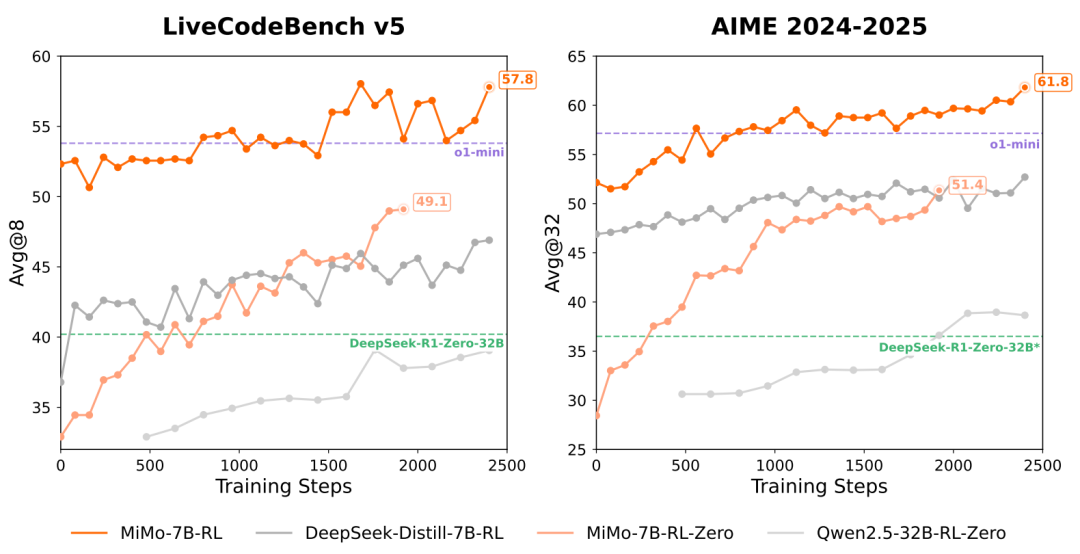
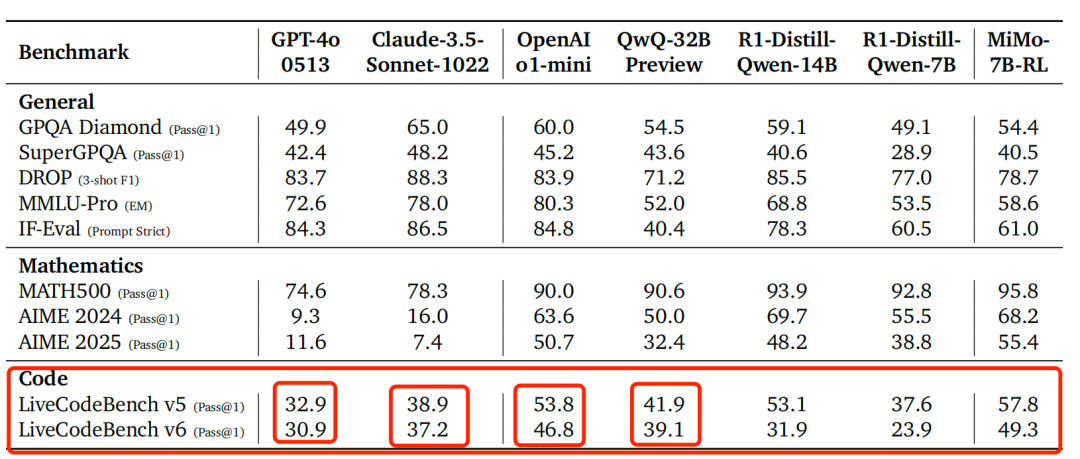
首批开源了四个模:MiMo-7B基础模型的表现优于约70亿参数的当前最优(SoTA)开源模型;MiMo-7B-RL-Zero在数学和代码任务上超越了320亿参数基础模型的强化学习训练性能;MiMo-7B-RL取得了出色的推理性能;以及一个MiMo-7B监督微调(SFT)模型。

小米大模型团队在推文中表示,2025年虽看似是大模型逐梦的后半程,但坚信AGI的征途仍漫长,所以将从务实创新出发,勇敢探索未知,用思考突破智能边界,用创造回应每一次好奇,同时还顺带提了一下团队正在招募技术人才的需求。
目前,中国开源大模型已经包揽全球开源模型阵营的第一梯队。
入局的开源选手有阿里Qwen、DeepSeek、腾讯混元、智谱AI、昆仑万维、阶跃星辰、百川智能以及即将开源的百度等等,竞争非常激烈,技术角逐也呈现出多样化特点,涵盖模型训练优化、多模态融合、低成本高效能等多个重要领域,目前来看,下半场竞争越来越是实力派大厂的天下。
美国顶尖AI大模型阵营有谷歌、OpenAI、Anthropic、XAI、Meta等,国内有阿里、腾讯、百度、字节跳动、DeepSeek等对阵。

此前,在开源赛道领跑的是AI圈黑马DeepSeek,在2024年12月推出开源模型DeepSeek-V3,创新自研MoE模型,训练成本仅557.6万美元,在性能上超越众多开源模型,比肩OpenAI顶尖闭源模型GPT-4o,一经发布便轰动了整个AI技术圈,DeepSeek趁热打铁在2025年1月20日推出R1推理模型,在数学、代码、自然语言推理等领域实力与OpenAI o1正式版性能相当,且完全开源,直接奠定了市场地位,最近传闻R2模型呼之欲出。
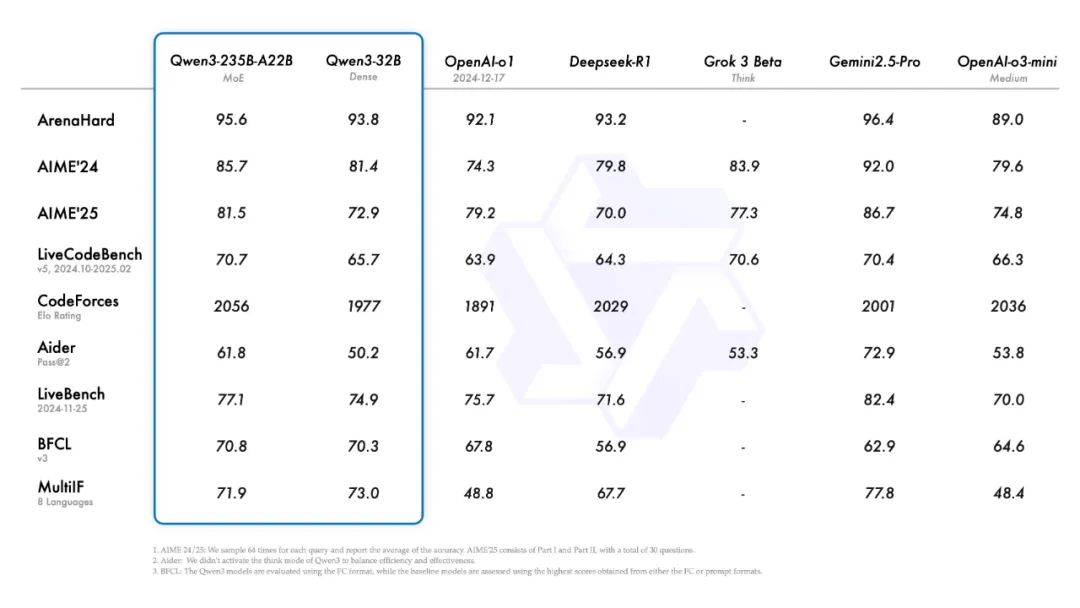
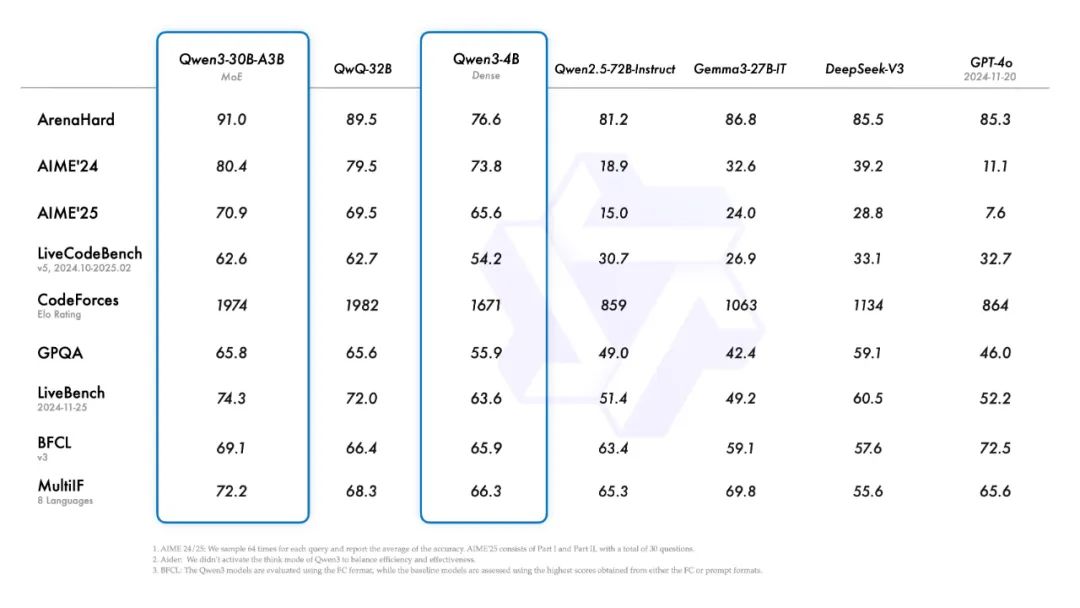
发展开源模型最为迅猛的阿里依靠Qwen系列模型迅速赶超上了DeepSeek和Meta。
日前,新发布的Qwen3模型正式登顶成为开源大模型性能之王,并增强了对MCP的支持,官方给出的性能报告显示已全面超越DeepSeek-R1和OpenAI o1,采用MoE架构,总参数235B,横扫了各大基准,,此外,官方称Qwen系列全球衍生模型数量已突破10万,下载量超过3亿次,超越美国Meta公司开发的Llama模型,问鼎全球第一AI开源模型。
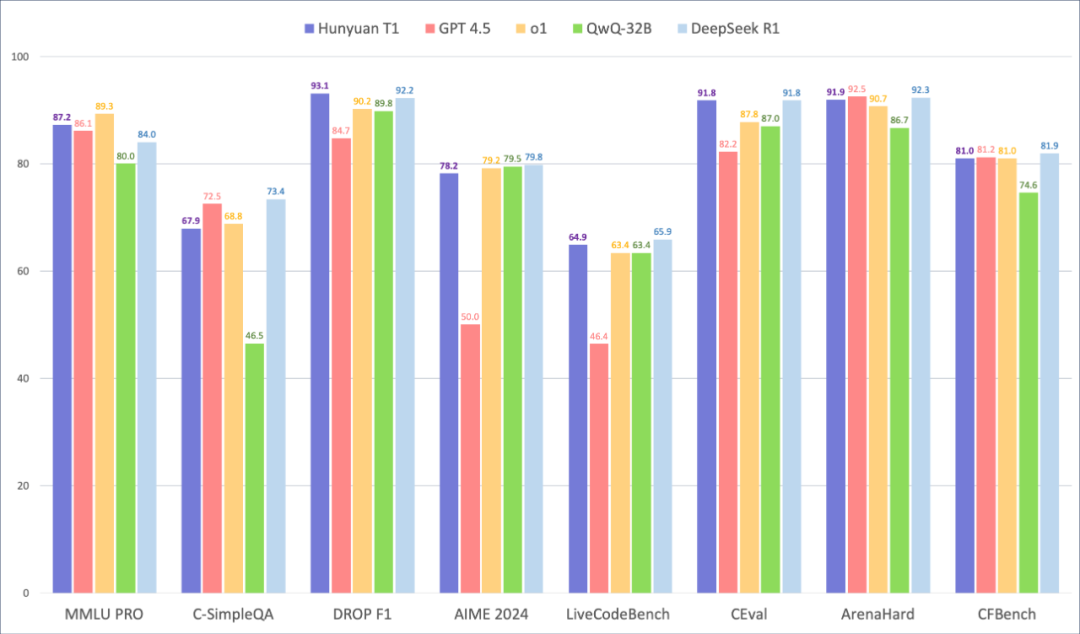
腾讯新推出的推理模型Hunyuan-1性能也比较出众,在一系列基准测试中数据领先,但目前并未有该模型开源的信息,不过Hunyuan团队在AI技术开源方面一直有积极行动,此前已开源多个图生视频模型及全新3D生成模型 ,未来T1也存在开源可能性。
最新消息称,腾讯对其混元大模型研发体系进行了全面重构,围绕算力、算法和数据三大核心板块,内部组织了两大部门,分别是大语言模型部和多模态模型部,负责探索大语言模型和多模态大模型的前沿技术,持续加码研发投入。
All in AI的百度曾官宣文心大模型4.5系列会于6月30日起正式开源,在刚刚过去的Create2025百度AI开发者大会上,文心大模型4.5 Turbo亮相,其多模态能力优于GPT-4o,文本能力与DeepSeek-V3最新版持平,优于GPT-4.5。
百度的另外一个优势还在于算力硬件方面自研昆仑AI芯片,走的路径有点和谷歌打造TPU相仿,谷歌第七代TPU “Ironwood”在算力、能耗、成本等方面展现出了更多优势,真正创新自研AI芯片的前期投入会在未来长线AI竞争中展现出更多综合优势。

其余的“AI六小虎”如智谱AI、阶跃星辰、MiniMax、月之暗面(Kimi)、零一万物和百川智能等都在大模型商业化层面积极探索,展现出不同的开源技术特色。
例如,智谱近期开源了32B/9B系列GLM模型,涵盖基座、推理、沉思模型等,其推理模型GLM-Z1-32B-0414性能可媲美DeepSeek-R1,其推理速度可达200 Tokens/秒,据说国内商业模型中速度之最。
整体来看,小米作为AI大模型赛道的新晋选手选择的入局时间非常巧妙。
当下AI市场已经走过了前期盲目投入和不确定的试水探路阶段,上一轮市场洗牌进入尾声,且开源AI技术创新力量正处于上升期,海量AI Agent应用正处于大爆发前夜,商业应用正在日趋成熟。
就资本实力而言,小米是远超AI六小虎等创业公司的存在,且有着手机、智能汽车、IoT与生活消费产品、互联网服务等主干业务作为持续营收支撑,数据场景十分丰富,用于研发的投入充沛,可能会快速发力追赶与第一梯队各大厂看齐。
开源模型赛道不仅PK开放性,也较量综合性能的领先性,多模态能力,以及性价比,无论是阿里还是百度,都会在推出新模型时把OpenAI和Deep Seek分别拉出来吊打一下。
一直以性价比著称的小米想要在当下AI大模型赛道吃得开也并不容易,就目前推出的MiMo-7B来看,虽然技术创新可圈可点,但距离最先进的水平还有一段路要走,而且,想要实现较高的开源影响力也需要有足够爆点的技术创新改进才行。
去年11月,小米被传出内部成立了AI平台部发力AI大模型,由张铎担任负责人,雷军曾称他为小米的技术“大神”,张铎曾在2016年至2021年期间在小米负责开源工作的规划与推进,2021年离开小米后曾入职神策数据担任研发负责人和首席架构师,2024年9月再度回归小米。
Apache HBase是一个开源的、分布式的、面向列的非关系型数据库,张铎曾在Apache软件基金会旗下近7000个Committer中总贡献数量排到了全球第三,并带领小米团队成为HBase全球社区最活跃、力量最强的技术队伍之一。
去年12月,小米被曝出着手搭建了自己的GPU万卡集群,如今时隔5个月推出MiMo-7B模型,可见其内部对于模型研发推进速度的重视。
随着小米的加入,AI大模型下半场的竞争,可能会比上半场更有意思。

(文:头部科技)