
DeepSeek新论文提新训练方法SPCT,R2要来了?
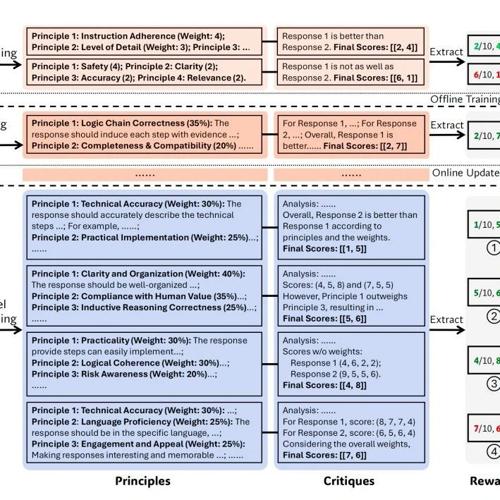
近日,DeepSeek和清华大学提出了一种新的训练方法SPCT(Self-Principled Critique Tuning),用于提升点式生成式奖励建模(GRM)的质量和可扩展性。该方法通过让模型学会先定原则、再写点评来改进通用RM的准确性,并实现了推理阶段的可扩展性提升。
近日,DeepSeek和清华大学提出了一种新的训练方法SPCT(Self-Principled Critique Tuning),用于提升点式生成式奖励建模(GRM)的质量和可扩展性。该方法通过让模型学会先定原则、再写点评来改进通用RM的准确性,并实现了推理阶段的可扩展性提升。
