
作者|沐风
来源|AI先锋官
近日,DeepSeek和清华大学共同发表了一篇论文《Inference-Time Scaling for Generalist Reward Modeling》,探讨了奖励模型的推理时Scaling方法。
现在,强化学习(RL)已广泛应用于LLM的大规模后训练阶段。
简单说,就是先训练一个奖励模型 (Reward Model, RM) 来模仿人类对 LLM 输出的偏好(比如判断哪个回答更好,或者给回答打分),然后用这个RM作为“奖励信号”去指导 LLM 的进一步学习,让LLM生成更符合人类期望的内容。
但现有的RM在通用领域却表现出受限的情况,尤其是在面对复杂、多样化任务的时候。
因此,就出现了两个关键挑战点。
一个是通用RM需要灵活性(支持单响应、多响应评分)和准确性(跨领域高质量奖励)。
另一个则是现有RM(如标量RM、半标量RM)在推理时扩展性差,无法通过增加计算资源显著提升性能。
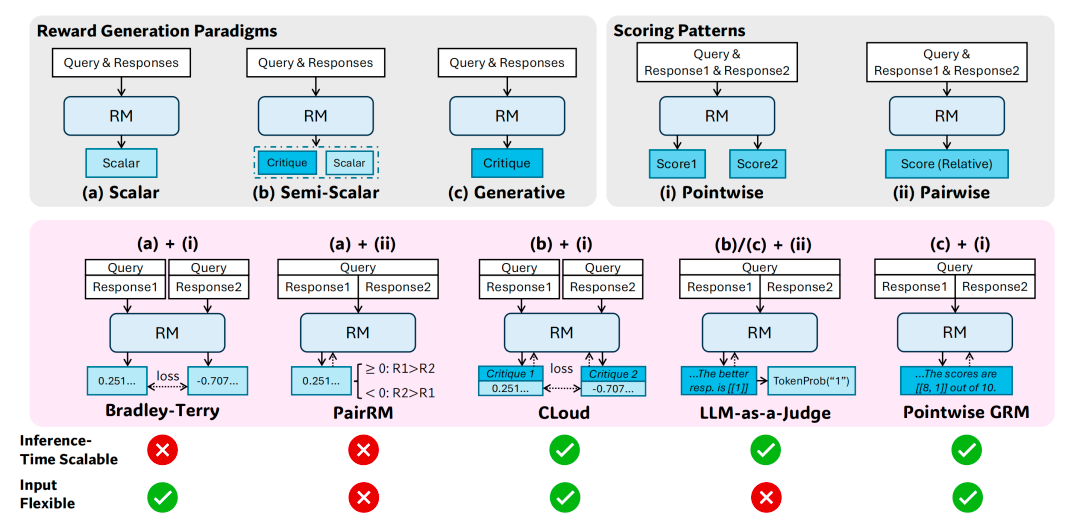
是否有可能通过增加推理计算资源,来提升通用查询场景下RM的能力,即通用RM在推理阶段的可扩展性呢?
DeepSeek和清华的研究者发现,在RM方法上采用点式生成式奖励建模(Pointwise Generative Reward Modeling, GRM),就能提升模型对不同输入类型的灵活适应能力,并具备推理阶段可扩展的潜力。
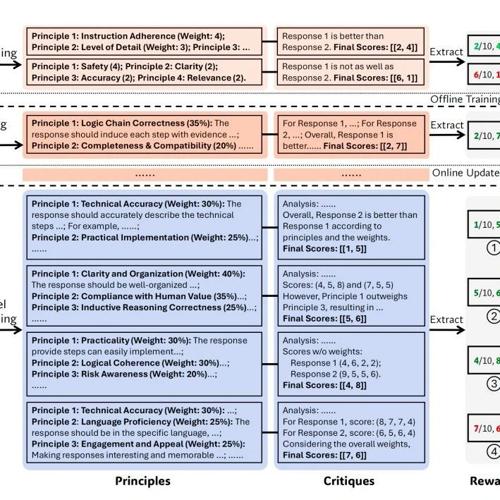
对此,这篇论文提出了一种新的训练方法“SPCT”(Self-Principled Critique Tuning),可以理解为“自定原则、自我点评”的调优方法。
SPCT 主要用在GRM上,通过在线强化学习(RL)训练GRM,使其能动态生成高质量的原则(principles)和点评(critiques),从而提升奖励质量。
SPCT的核心思想是: GRM先评估应该看重哪些“原则” (Principles),然后再根据这些刚定好的原则去写一段“点评”(Critique),最后再从点评中提炼出分数。
简单来说,SPCT就是把RM的工作流程从“直接给分”变成了“定原则-写点评-提分数”的间接评估。
整体来看,SPCT包括两个阶段,它们分别是:
拒绝式微调(rejective fine-tuning)作为冷启动阶段,通过采样和拒绝策略生成初始数据。
基于规则的在线RL,通过提升生成的原则和点评内容来强化通用奖励的生成过程。
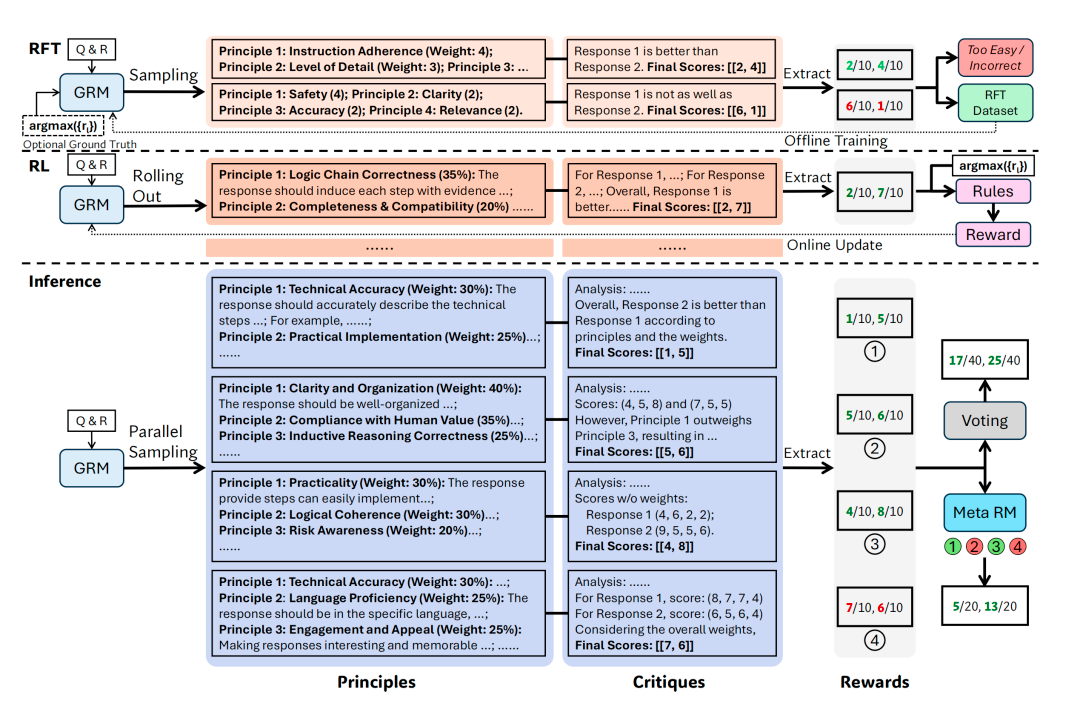
另外,SPCT还可以促进GRM在推理阶段的可扩展行为。
他们基于Gemma-2-27B经过SPCT训练后推出了DeepSeek-GRM-27B。
可以发现,SPCT显著提高了GRM的质量和可扩展性,在多个综合RM基准测试中优于现有方法和模型。
强制模型先想原则再点评,评估结果自然更准确、更可靠。
另外,他们还引入一个元奖励模型(Meta RM),专门评估每次采样生成的 (原则, 点评) 的质量,以提升扩展性能。
SPCT的另外一个核心亮点是“越算越准”。
对同一个问题和回答,让模型独立地、带点随机性地(比如 temperature > 0)思考 k 次。因为想法(生成过程)有多样性,每次可能会得到不同的原则、点评和分数。
论文里的实验结果清楚地显示,随着采样次数 k 增加,不管是Voting还是Meta RM,DeepSeek-GRM 的性能都会往上涨,证明了它确实能有效地“越算越准”。
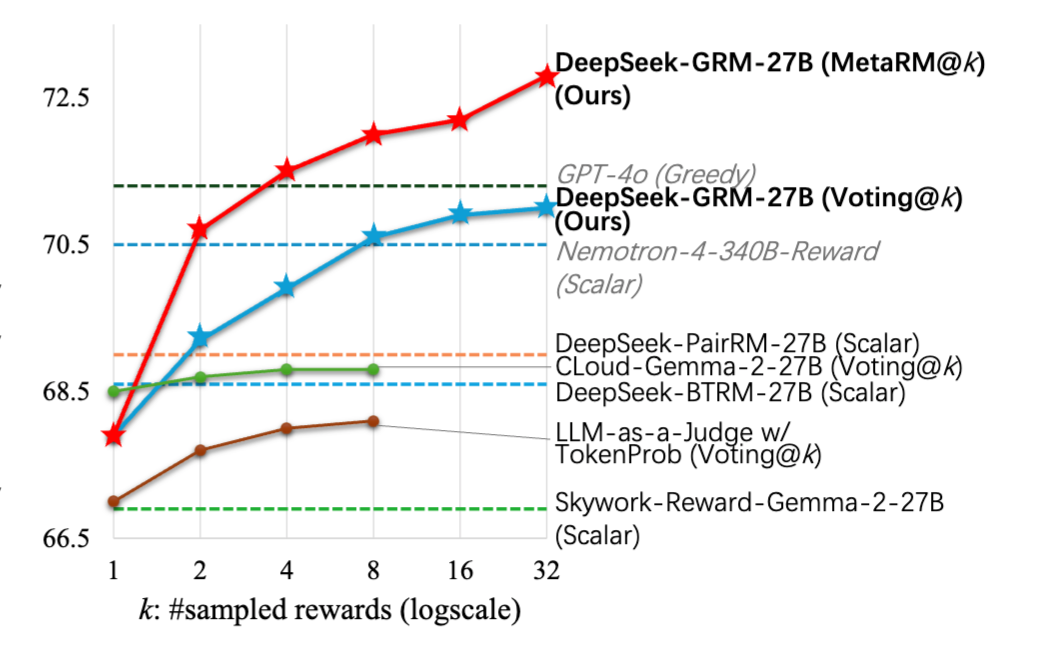
总的来说,SPCT 是个挺有创意的 GRM 训练方法。它通过让模型学会“先定规则、再点评打分”的模式,实打实地提升了奖励模型的准确性、透明度、灵活性和通用性。
最关键的是,它训练出的GRM具备了出色的推理时可扩展性,可以通过多花算力来换取更高的评估质量。
论文也提到,未来可以继续优化 GRM 的效率,或者让它学会使用工具来处理更复杂的评估任务。
论文地址:
https://arxiv.org/pdf/2504.02495
(文:AI先锋官)