
Qwen3 新模型 Coder:性能、价格、可用性|全详解,包括官方没说的
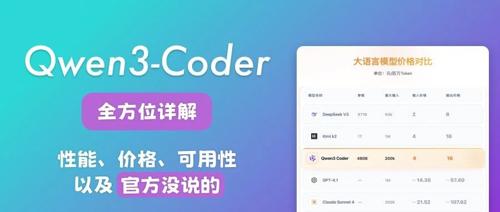
今天凌晨Qwen3-Coder发布最强代码模型,采用MoE架构,开源480B大小。性能上胜过Claude Sonnet4,价格图表对比明确,API及开发方式详述,还有自部署、CLI工具和调用示例等全面信息。
今天凌晨Qwen3-Coder发布最强代码模型,采用MoE架构,开源480B大小。性能上胜过Claude Sonnet4,价格图表对比明确,API及开发方式详述,还有自部署、CLI工具和调用示例等全面信息。

文章介绍了字节跳动豆包大模型团队提出的新稀疏模型架构 UltraMem,该架构有效解决了 MoE 推理时高额的访存问题,推理速度提升2-6倍,成本降低83%。
