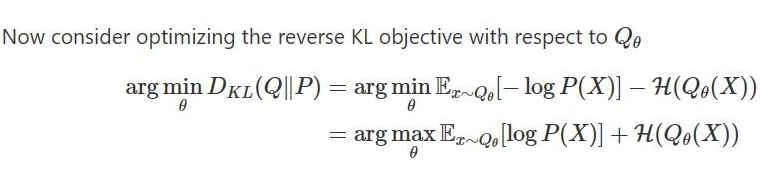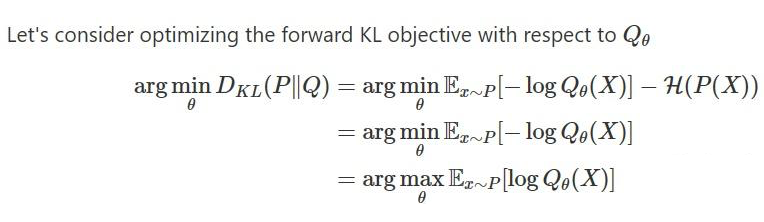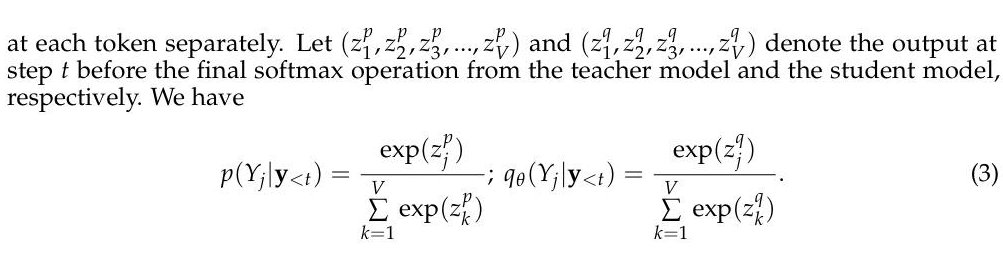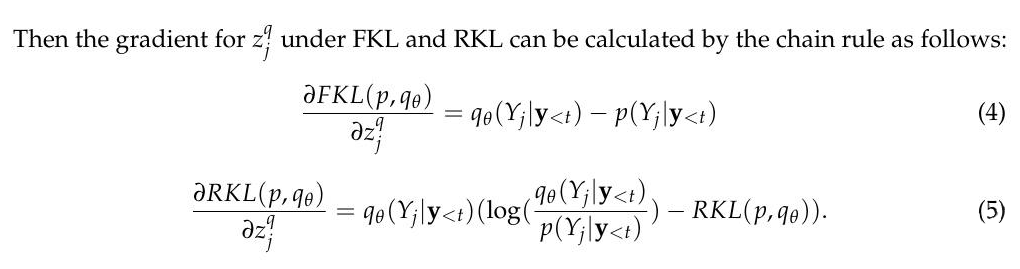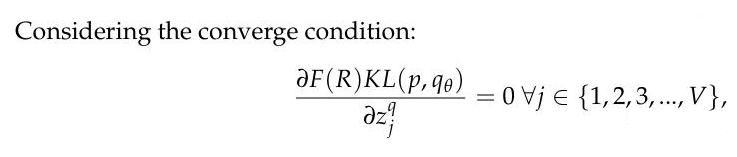©PaperWeekly 原创 · 作者 | Taki5
单位 | 香港大学
研究方向 | LLM efficiency, trustworthy
导言: 近来有很多文章尝试做 LLM 的蒸馏,有几篇文章都提到说,使用 Reverse KL 会比 Forward KL 好,并且给出了自己的理由,事实真的如此么?
FKL vs RKL 先介绍介绍基础知识,KL 散度在知识蒸馏 KD 中有广泛应用,也广为大家所使用。不过,KL 散度并不是对称的,正向 KL 不等于反向 KL。这里介绍一个讲的比较好的 blog: https://dibyaghosh.com/blog/probability/kldivergence.html
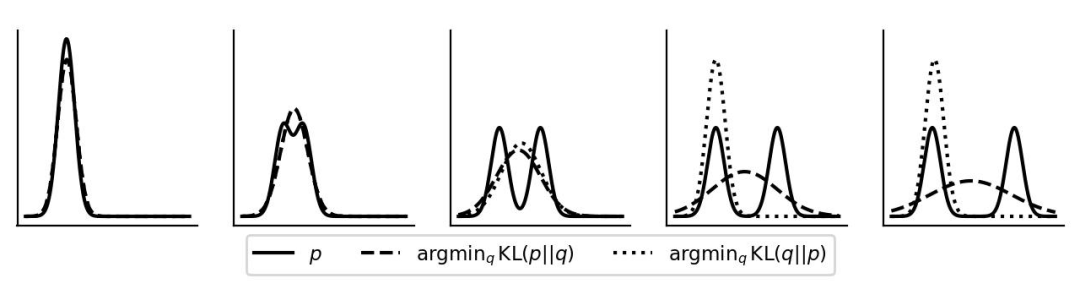
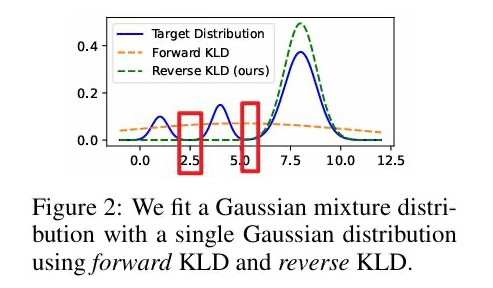
在知识蒸馏里,P 是 teacher 模型的输出,不带参数 ,Q 是 student 模型的输出,带可优化的参数。 常规来说,我们使用正向 KL,因为正向 KL 可以拆分为: 正向 KL 可以拆分为 1)-1* 不变的 P 的 entropy 和 2)P,Q的交叉熵,这样优化正向 KL 相当于优化交叉熵。 按照相同的方法对 反向 KL 进行优化,那么便会得到 1)-1* 可变的 Q 的 entropy + 2)Q,P 的交叉熵,前后两项都是带参数的,那么就很难做进一步分析了,需要同时来看两项 loss。 通常认为,前向 KL 是 mass-covering 也就是 mean-seeking,反向 KL 是 mode-seeking
也就是说 前向 KL 会尽可能同时拟合多个峰,反向 KL 倾向于拟合单个峰 。如上图所示。 https://zhuanlan.zhihu.com/p/372835186
值得注意的是,里面关于反向 KL 的分析有个 entropy 的说法有误,因为不能只分析一个 loss,忽略另外一个 loss,正确的思路应该是: https://dibyaghosh.com/blog/probability/kldivergence.html
RKL比FKL更适合LLM的KD? 近来,MiniLLM 这篇论文提出,RKL 应该比 FKL 更适合 LLM 的 KD,理由是:
简单来说就是,FKL 在传统任务好,是因为传统分类任务的输出空间小,mode 比较少,也就是多峰的时候少,但是对于 LLM 来说,输出空间更复杂,mode 更多。再使用 FKL 的话,q 就会关注 p 的空区域,就会产生不好的样本。
意思是正向 KL 会让学生模型给 这种应该概率低的区域赋比较高的值,进而带来麻烦。 因此,MiniLLM 提出来说要使用 reverse KL 来代替 forward KL 进行蒸馏。
PromptKD: Distilling Student-Friendly Knowledge for Generative Language Models via Prompt Tuning
https://arxiv.org/abs/2402.12842
DistiLLM: Towards Streamlined Distillation for Large Language Models
https://arxiv.org/abs/2402.03898
Gkd: Generalized knowledge distillation for auto-regressive sequence models
https://arxiv.org/abs/2306.13649
f-Divergence Minimization for Sequence-Level Knowledge Distillation
https://arxiv.org/abs/2307.15190
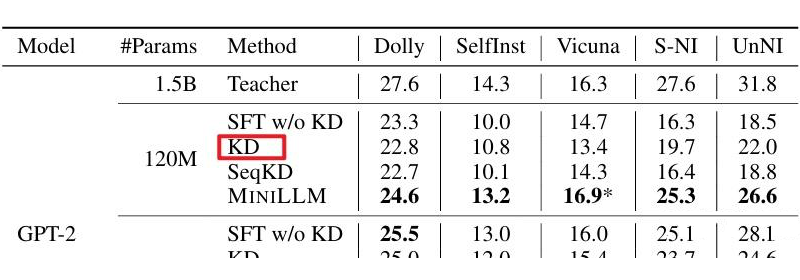
一些疑惑 然而,在 LLM 的 KD 任务中,这种 mean-seeking 和 mode-seeking 真的会存在? 3.1 理论角度 问题一:FKL 与 RKL 的特性,需要学生模型输出符合高斯分布,教师模型输出符合混合高斯分布才行。这点并不满足:学生与教师模型的输出是由 SoftMax 得到的,并不符合高斯分布。 问题二:学生与教师模型的输出的 logits 都是离散的,并不是连续的,所谓的 p 比较小的区域,很可能是没有定义的。 问题三:BERT 的词表大小是 30522,也就是说输出的 logit 是 30522 维度,LLaMa 的词表也不过 32000,为何之前的 BERT 预训练任务的蒸馏用 FKL 就可以,现在的 LlaMa 就需要 RKL? 3.2 实验角度 从实验的角度来看,MiniLLM 明显缺乏一组 RKL 的实验:
比如说,这里的 KD 应该补一组 RKL 的实验结果。 在别的论文中,比如 DISTILLM: Towards Streamlined Distillation for Large Language Models,可以看出 这里的 RKLD(使用 RKL)并不一定能超越 KLD(使用 FKL)。 类似地,在Revisiting Knowledge Distillation for Autoregressive Language Models 中,可以看出: 3.3 DPO的视角 在 MiniLLM 的最后,作者提出,这种 RKL 其实类似于强化学习的 IRL。 最近的一个论文 Beyond Reverse KL: Generalizing Direct Preference Optimization with Diverse Divergence Constraints 指出说:
实现与 human 对齐的常见技术是 RLHF,最近的论文提出了 DPO 方法,这种方法是 RLHF + Reverse KL 的近似,DPO 的优势是不再需要分两阶段训练 reward 模型进而相比 RLHF 大为简化。本文章发现,考虑更 general 的 KL散度(f 散度)时,RLHF 也可以简化为 DPO 的形式。
简单来说,就是之前的论文认为 RKL 下 RLHF 才可以简化成 DPO,但是该论文发现 FKL 和其他的 KL 都可以做这个近似。具体解读参考: https://zhuanlan.zhihu.com/p/689394611 也就是说,RKL 在 DPO 中的角色可以被 FKL 所替代。侧面也反应了二者一定程度的等价性。 所以说, RKL 比 FKL 更适合 LLM 的 KD 任务,其实不一定对。
那么应该是怎么样的? 直觉来说, 对于 FKL 与 RKL,loss=0 都等价于 P 与 Q 重叠,最终的优化目标的都是 Q 与 P 一致。
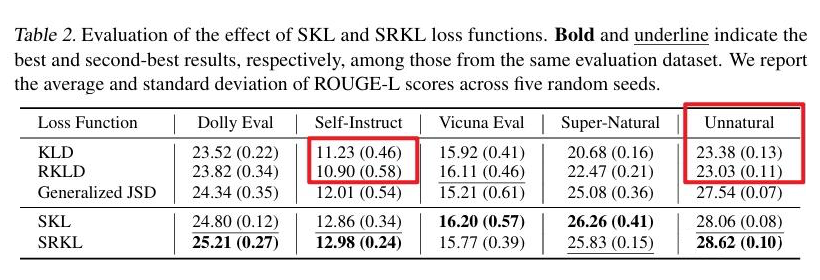
[CoLING 2025] Rethinking Kullback-Leibler Divergence in Knowledge Distillation for Large Language Models
https://arxiv.org/abs/2404.02657 https://github.com/wutaiqiang/LLM_KD_AKL
考虑 离散+非高斯的情况,分析的时候 考虑 softmax 之前的变量 Z(而不是考虑 softmax 以后的分布) ,定义:
以 Z 为切入点去考虑,考虑 loss 对于 Z 的梯度:
模型收敛的条件是,对于参数 Z 的梯度为 0,也就是:
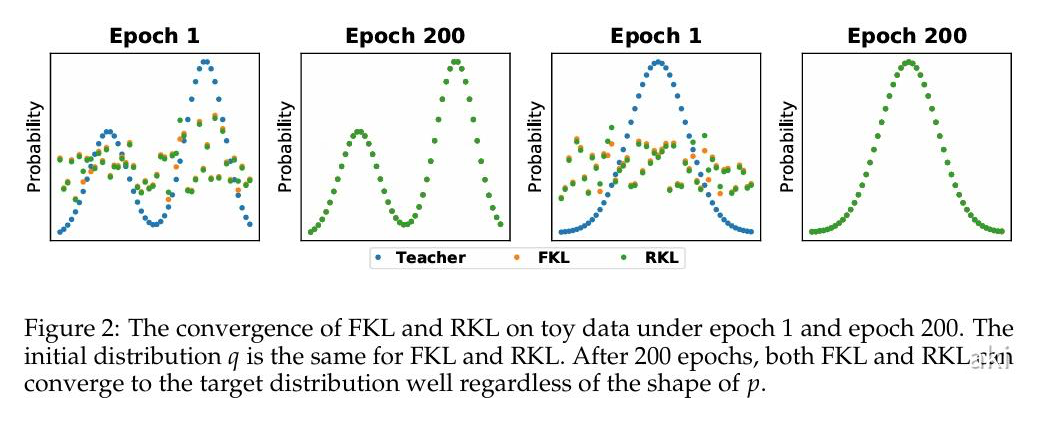
也就是说,如果不加上高斯的约束,那么无论是 FKL 还是 RKL,本质都是 Q 逼近 P。 toy data 的结果也是一致的,不管 teacher 的输出是怎么模态,200 epoch 以后都是二者重叠。 该论文也提供了 f-divergence 角度的分析:
这样解释了为什么会有 mode-seeking 和 mean-seeking。 区别在于拟合过程,FKL 优先拟合 P 概率比较大的区域,也就是 head part,RKL 优先拟合 P 概率比较小的区域,也就是 tail part:
这里选用最常见的长尾分布来建模 teacher 的输出。因为具备位置上的可交换性,真实 teacher 输出做降序排列以后,就是这样的长尾分布。 继续从 f-divergence 的角度来看也可以分析得到:
这篇文章基于这个特性,还提出了新的方法,这里就不详细展开了。 话说回来,实际的蒸馏还是更复杂的。每个 sample 可能只梯度下降一次,并不会如 toy data 一样优化几百次。此外就是蒸馏会看很多样本,并不是单个样本。自然很多理论的分析,实际上都会有出入。不过,RKL 更适合 LLM 的 KD 这件事,基本是不成立,本身波动还是很大的。 此外,这种特性也不仅仅局限于 LLM 的 KD,对于常规的 KD 亦如是。大家在做 KD 的时候,很多都是 FKL 试试,RKL 试试,FKL+RKL 的策略试试,JS 散度的策略试试。更有效的方法还需要进一步的探索。 本文不讨论 FKL RKL 谁更好,只讨论 FKL RKL 的 mean-seeking mode-seeking 是否还成立。最关键的原因就是 mean-seeking mode-seeking 要求学生模型是单峰高斯分布,但实际 case 下是不满足的,而且并不是连续分布。 在这种情况下,分析 PQ 其实不如直接分析获得 PQ 的 Z(假定 Z 经过 softmax 获得 logits)。至于说后续的 COLM 文章,也仅仅从 token 蒸馏的角度出发,提出了一种综合 FKL 和 RKL 的方案。 至于说 sequence-level 怎么去优化,还有待进一步探索。 很多人可能觉得 kl 散度让两个分布的 z 一致有点 trival. 但是之前的人都认为说存在 mode-seeking mean-seeking 的现象,本文就是 rethink 这些观点。 此外, 在训练初始阶段,表现出来的 FKL 优先拟合头部和 RKL 优先拟合尾部,本质上也是一种 mass covering 和 zero avoiding。 重点关注早期的 epoch 比较有意义,毕竟实际蒸馏时 2 个 epoch 已经顶天。
(文:PaperWeekly)