
从“AI焦虑”到“AI自信”:开发者必备的LLM应用开发实战手册
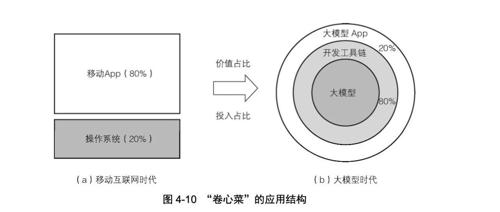
开发者朋友,你是否感受到被AI浪潮裹挟的焦虑?这本书《探秘大模型应用开发》,正是我精心绘制的学习与实践路线图。拒绝碎片化知识,构建体系化学习脉络;洞察本质,提供深入浅出解答。无论你是传统开发者、技术新人还是管理者,《探秘大模型应用开发》都将助你走出迷茫区,掌握LLM应用开发的核心知识与技能。
开发者朋友,你是否感受到被AI浪潮裹挟的焦虑?这本书《探秘大模型应用开发》,正是我精心绘制的学习与实践路线图。拒绝碎片化知识,构建体系化学习脉络;洞察本质,提供深入浅出解答。无论你是传统开发者、技术新人还是管理者,《探秘大模型应用开发》都将助你走出迷茫区,掌握LLM应用开发的核心知识与技能。

腾讯在最新财报中强调了AI的重要性,并加大了对AI的投资力度。马化腾表示腾讯业绩受益于AI赋能,增加了AI投入并计划进一步增加资本支出。此外,在全球数字生态大会上,腾讯系统阐释了关于AI战略思考。

OpenAI与CoreWeave签署5年119亿美元协议,使微软依赖度降至62%,并缓解投资者担忧。此举加剧了微软与OpenAI的竞争关系。

DeepSeek 揭示其模型推理系统成本利润率高达545%,通过优化硬件配置、动态资源调度和采用大规模跨节点专家并行技术,实现了高吞吐量和低延迟。
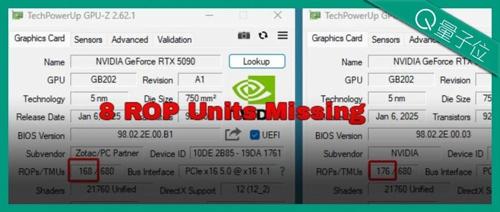
英伟达的5090显卡因ROP缺失导致性能下降,目前已有多个发行商版本出现同样的问题。英伟达表示生产异常已被纠正,受影响用户可找发行商换货。




