DeepSeek R1 彻底出圈:震动整个AI行业,高强度刷爆社媒,赞誉,恐慌,破防,八卦全都来了

权威基准测试中,DeepSeek R1综合排名第3,并且在多个技术领域表现出色。此外,R1还被评为人类最后的考试排名第二,引起Meta恐慌。
权威基准测试中,DeepSeek R1综合排名第3,并且在多个技术领域表现出色。此外,R1还被评为人类最后的考试排名第二,引起Meta恐慌。

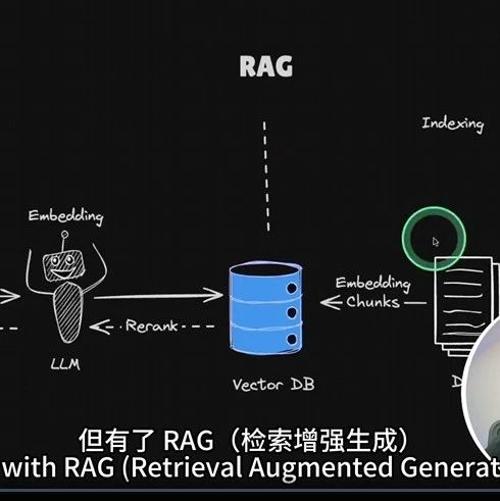
DeepSeek-R1 是一款性能与 OpenAI-o1 相当,费用只有其不到 10% 的开源推理模型,作者使用它构建了 Agentic RAG 应用,并介绍了相关的技术栈和架构图。

DeepSeek-R1模型引发广泛关注,成本从数十万到几百元不等。其表现超越多种榜单和测试任务,包括LiveBench和PlanBench,在公开数据上甚至超过GPT-4和Gemini Flash。同时引发了关于构建新平台强化微调的兴趣。

木易分享了对AI模型DeepSeek-R1的测试体验,指出其在24点问题上的表现优于o1-preview,并强调其推理过程更加简洁明了、中文化和性价比高。
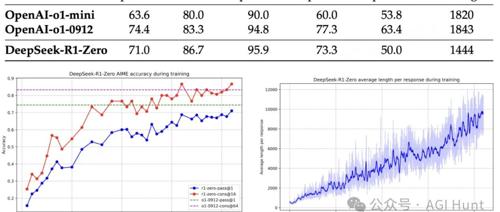
DeepSeek AI 推出 DeepSeek-R1 模型,引入群体相对策略优化(GRPO)和多阶段训练方法。通过强化学习提升大语言模型推理能力,并在监督微调和拒绝采样后形成最终模型。
DeepSeek-R1模型在不到一天内获得了5000多收藏,并且在GitHub上公布了其源代码。该模型展示了出色的理科和文科能力,响应速度快、成本低。然而,在处理英文问题以及使用少样本提示词时存在局限性。总体来看,DeepSeek-R1具有广泛的应用潜力。

中国版o1 DeepSeek R1通过大规模强化学习训练,在多项任务中与OpenAI o1打成平手,展示了不依赖监督微调数据也能显著提升推理能力的潜力。