
Adobe Firefly 增加音效生成功能!

Adobe 推出了全新的生成式人工智能电影制作工具Firefly,提升了音效和视频生成能力,并优化了工作流程。新功能包括生成音效、更平滑的过渡效果、虚拟形象视频和风格预设等,让创作者能够更专注于创意本身。
Adobe 推出了全新的生成式人工智能电影制作工具Firefly,提升了音效和视频生成能力,并优化了工作流程。新功能包括生成音效、更平滑的过渡效果、虚拟形象视频和风格预设等,让创作者能够更专注于创意本身。

Meta 挖角 AI 研究员,包括华人学者如汪滔、毕树超等加入 Meta。这些新成员在各自领域具有影响力。Meta 已招揽 11 名顶级研究员,涵盖超级智能实验室和多模态研究等多个方向。
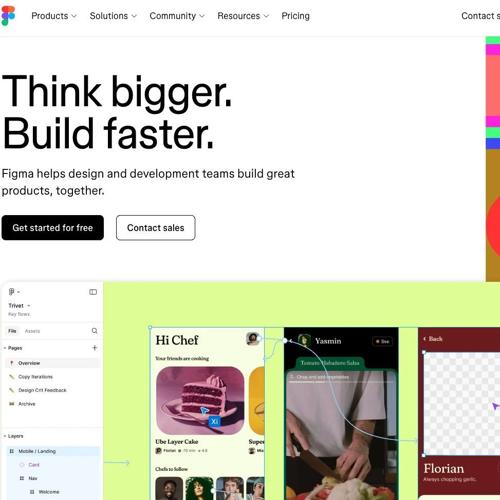
设计公司Figma发布多项新功能,包括AI驱动的网站创建工具、面向营销人员的素材生成方式和全新绘图工具。该公司的网站创建工具Figma Sites允许设计师轻松创建并发布网站,并支持协作修改元素。此外还推出了Figma Make工具和内容管理系统的Figma Buzz以及矢量编辑工具Figma Draw,旨在与Canva等创意解决方案竞争。

Adobe 发布Firefly AI平台新版本,新增翻译音频、视频功能及背景音乐生成能力,提升创意工作效率。支持多种语言翻译、声音与视频同步调整,并提供图像和视频生成模型,增强内容创作灵活性。
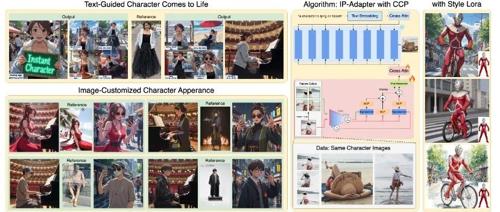
GPT-image-1 是 OpenAI 最新、最先进的图像生成模型,支持高级定制和多种艺术风格。InstantCharacter 仅需单张图片即可个性化角色生成,适用于各种下游任务。Cooragent 提供智能体协作平台,简化复杂任务完成流程。Austen 利用 AI 和 Mermaidjs 分析书籍角色关系并可视化。Describe Anything 模型能生成图像/视频特定区域的详细描述,并发布新的评估基准。
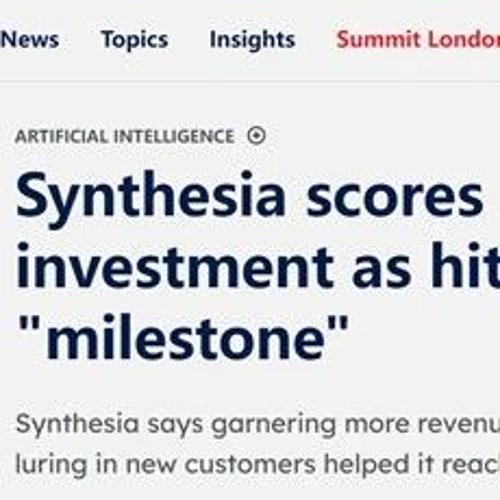
英国初创公司Synthesia凭借其在企业AI生成视频化身领域的表现成功获得Adobe战略投资。目前超过6万家公司在使用Synthesia服务,预计年底将达10万。该公司已完成1.8亿美元D轮融资,估值达到21亿美元。

Adobe近期为Premiere Pro推出一系列基于人工智能技术的新功能,包括高效精准的音频处理、智能声音修复和360沉浸声场支持等,提升了视频创作者的工作效率与质量。
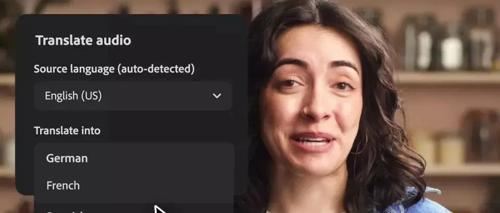
新的 Firefly Web 应用程序提供了一套由 Firefly 系列模型支持的工具,直接集成到 Adobe 应用程序中,新增了语音和视频翻译功能。

专注于AIGC领域的专业社区分享了Adobe发布的全新生成式AI应用Adobe Firefly。它支持图像、矢量图形及视频生成功能,并且首次推出处于公测试阶段的文生视频模型,实现了从文本提示到高质量1080p视频的转化。

Adobe的研究者提出了一种名为MotionBridge的算法,它可以在保持高质量的同时提供多种可控信号(如关键帧、运动轨迹、掩码和引导像素)来生成逼真的视频。