


Adobe 发布了其 Firefly AI 平台的重大更新,使其从一个独立的图像生成器转变为一个用于创建各种类型数字内容的综合性系统。此次更新特别在声音相关功能上取得了显著进展,为创意工作者提供了更强大的音频创作工具。以下是对声音相关功能的详细扩展:
Adobe Firefly 的“翻译音频”功能允许用户将音频文件中的语音内容翻译成多种语言,同时保留原始声音的语音、语调和节奏。这一功能支持超过 20 种语言,包括中文、德语、英语、法语和西班牙语等。用户可以准备一个格式为 .mp3、.aac 或 .wav 的音频文件,时长至少为 5 秒,最长不超过 10 分钟。在 Firefly 主页上,进入“Audio”部分,选择“Translate Audio”,上传音频文件后,系统会自动检测源语言,用户也可以手动选择目标语言。点击“Generate”开始翻译,完成后可以下载翻译后的 .wav 文件。
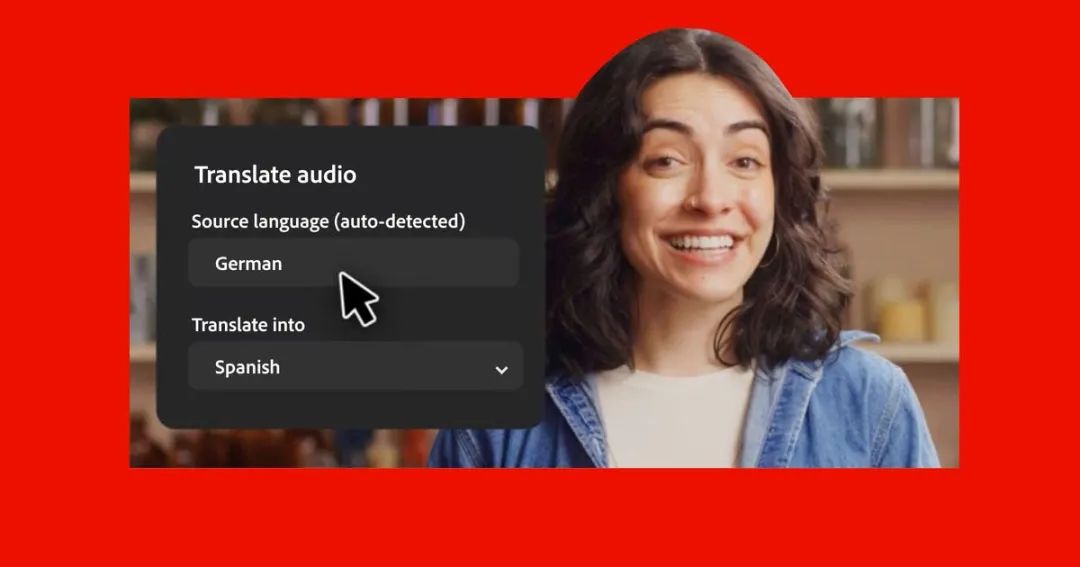
这一功能适用于跨国项目中的多语言配音、跨境电商广告的本地化、国际活动宣传片的制作以及多语言教程的开发等多种场景。其技术优势在于能够高度还原原始声音的特征,使得翻译后的内容听起来更加自然真实,极大地节省了专业配音的时间和成本。
Firefly 的“翻译视频”功能不仅支持音频翻译,还能自动调整视频中人物的口型动作,使其与翻译后的声音完全匹配。支持的视频格式包括 .mp4 和 .mov,音频格式包括 .mp3、.aac 和 .wav。视频文件最短支持 5 秒,最长支持 10 分钟。输出的视频文件为 .mp4 格式,音频文件为 .wav 格式。这一功能极大地简化了多语言视频制作的流程,节省了大量时间和成本,适用于跨国企业的宣传视频制作、多语言教育视频的开发以及国际活动的宣传内容制作等。它通过将音频翻译与视频编辑相结合,为创意工作者提供了一个高效的一站式解决方案。

此外,Firefly 还支持根据文本提示生成背景音乐和音效。例如,在广播剧制作中,Firefly 可以根据剧本的情节和氛围,自动生成相应的背景音乐和音效,增强作品的感染力。这种音频生成能力为创作者提供了更多的灵活性和创意空间,使得他们能够更加专注于内容的创作,而不是花费大量时间在音频素材的寻找和编辑上。
除声音功能外,Adobe 还推出了新的图像和视频生成模型。新的 Firefly 图像模型 4 包括标准版和超高清版,能够满足 90% 的典型创意需求,并在渲染复杂场景时表现出色。Firefly 视频模型可以生成长达五秒的 1080p 视频片段,支持多种宽高比,并允许用户自定义镜头运动。为了提高创作效率,Firefly 新增了“文本转矢量”模块和“Firefly Boards”工具,分别用于创建可编辑的矢量图形和协作开发创意。

Adobe 还宣布将推出适用于 iOS 和 Android 的移动应用,支持随时随地创作并同步项目。Adobe 正在通过整合第三方供应商的 AI 模型来扩展其平台,首批支持的模型包括 Google 的 Imagen 3、OpenAI 的 GPT 图像生成、Veo 2 和 Flux 1.1 Pro。未来,Adobe 还计划引入 fal.ai、Runway、Pika、Luma 和 Ideogram 等合作伙伴的模型。为了保持透明度,Adobe 将为所有 AI 生成的内容附上“内容凭证”,标明使用了哪种模型进行创作。

Adobe 强调,只有其专有的 Firefly 模型是专门使用许可数据进行训练的,因此可以安全用于商业用途。
Adobe Firefly AI 平台的最新更新标志着其在创意生成领域的又一次重大进步。通过引入新的图像和视频生成模型、扩展功能工具、移动应用支持以及第三方模型的整合,Adobe 为创意工作者提供了更强大的工具和更灵活的选择。这一更新不仅提升了创作效率,还为创意产业的发展注入了新的活力。
(文:AI音频时代)