大语言模型离“数学证明高手”还有多远?斯坦福、伯克利、MIT 团队提出 IneqMath 评测标准

,这些模型真的理解了推理过程吗?还是只是看起来“像那么回事”就蒙出来的?
不等式问题是检验模型“真会
,这些模型真的理解了推理过程吗?还是只是看起来“像那么回事”就蒙出来的?
不等式问题是检验模型“真会

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态。扩散语言模型通过存储和重用先前计算的注意力状态来提升生成速度,但并行解码时往往导致生成质量下降。Fast-dLLM提出基于置信度的平行解码策略来改善这一问题。

斯坦福等团队提出IneqMath基准,用于评估大语言模型在数学不等式证明中的严谨性与合理性。结果显示模型推理正确率远低于答案正确率,暴露出其逻辑缺陷。研究者引入多维度评审器审查模型解题过程,以提升模型的逻辑严谨性。
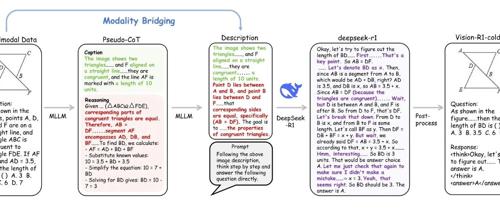
Vision-R1项目通过两阶段策略解决了多模态推理数据稀缺的问题,提出冷启动初始化和RL训练方案,并创新性地引入PTST策略和HFRRF奖励函数,显著提升了模型在多个数学推理基准测试中的表现。

新智元报道
编辑:LRS
STP(自博弈定理证明器)模型通过模仿数学家的学习方式,实现了在「有限数据」的情况下无限运行并自我改进。该方法显著提高了已知模型的扩展性能,并且能够在多种基准测试中实现最优表现。
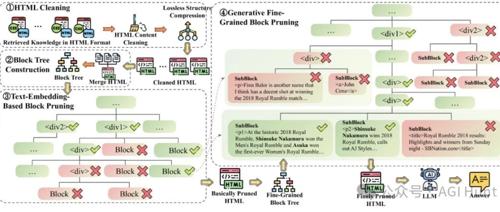
一种名为HtmlRAG的新方法让RAG系统能够充分利用HTML结构信息,大幅提升知识检索准确性。通过HTML清理、块树构建及两阶段剪枝技术,HtmlRAG解决了传统RAG系统的「近视」问题,显著提高了效率和准确性。