

📢本周AI快讯 | 1分钟速览🚀
1️⃣ 🧠 字节豆包推出”深入研究” :基于 Agent 能力的新功能开启免费测试,支持复杂任务处理,可生成可视化报告并一键转换为播客。
2️⃣ 🎯 百度开源文心 4.5 系列 :发布 10 款模型,包括 47B 和 3B 的 MoE 模型,采用多模态异构架构,28 项基准测试超越 DeepSeek-V3。
3️⃣ 🚀 华为首次开源盘古模型 :推出 盘古 Embedded 7B 和 盘古 Pro MoE 72B,单卡推理达 1148 tokens/s,引入”快慢思考”双系统框架。
4️⃣ 🎵 阿里通义开源音频生成模型 ThinkSound :首个引入”思维链”的音频生成模型,音画同步精度提升 37.2%,提供三种规模版本。
5️⃣ 👁️ 智谱开源 GLM-4.1V-Thinking :90 亿参数视觉推理模型,23 项任务达 10B 级别最佳,18 项持平或超越 Qwen-2.5-VL-72B。
6️⃣ 🎬 谷歌文生视频模型 Veo 3 全球开放 :向 159 个国家 Pro 会员开放,每天可生成 3 个 8 秒 720p 视频,支持对话和音效同步生成。
7️⃣ 🔍 xAI Grok 4 模型细节意外曝光 :源代码泄露 Grok 4 和 Grok 4 Code 两款新模型,后者专为开发者设计,将集成至代码编辑器。
8️⃣ 💰 xAI 筹集 100 亿美元 :包括 50 亿债务和 50 亿股权,估值达 800 亿美元,用于扩展 Colossus 超算至 100 万 GPU。
9️⃣ 💎 Perplexity 推出 Max 订阅 :月费 200 美元高端计划,提供 o3-pro 和 Claude Opus 4 优先使用权,无限 Labs 访问。
🔟 💻 Cursor 发布网页应用 :支持浏览器管理 AI 编码智能体,自然语言分配任务,Pro 用户专享(20 美元/月)。
1️⃣1️⃣ 🏢 Meta 成立超级智能实验室 :挖角 11 位顶尖 AI 人才,包括多位 GPT-4o 和 o3 共同创建者,签约奖金高达 1 亿美元。
1️⃣2️⃣ 🧪 谷歌发布认知预测模型 Centaur :基于 Llama 3.1 微调,在 31 项认知任务中击败传统模型,内部表示与人类 fMRI 高度一致。
01|字节豆包 AI “深入研究”功能开启测试
6 月 30 日,字节跳动旗下 AI 助手豆包宣布,其全新功能“深入研究”已在 App、网页版和电脑版正式开启测试,用户可免费体验。该功能基于模型的搜索、推理及 Agent 能力,旨在帮助用户更快速、全面和结构化地处理高难度的复杂任务。
“深入研究”功能适用于长途旅行攻略、复杂购买决策、最新政策解读、商业科技趋势发展等需要获取大量资料、长时间研究的问题。用户只需更新至最新版豆包 App 或电脑版,进入「深入研究」功能,输入详细指令或一句话提示词,几分钟内即可生成初步方案。生成的研究报告可通过可视化网页和文档两种方式呈现,方便用户查看和分享。此外,豆包 App 还支持将报告内容一键转换为播客形式,方便用户随时聆听。
02|百度开源文心 4.5 系列 10 款模型
6 月 30 日,百度正式开源 文心大模型 4.5 系列,涵盖 10 款不同规模的模型,包括激活参数为 47B 和 3B 的混合专家(MoE)模型,以及 0.3B 的稠密型模型。此次开源不仅提供了预训练权重和推理代码,还同步开放了 API 服务,开发者可通过飞桨星河社区、Hugging Face、GitHub 等平台下载部署使用。
文心 4.5 系列模型基于百度自研的飞桨深度学习框架,采用多模态异构 MoE 架构,支持文本与视觉模态的联合训练。通过引入模态隔离路由机制、路由正交损失和多模态 token 均衡损失等技术,提升了模型在多模态理解、文本生成和跨模态推理等任务中的性能。
在训练和推理方面,文心 4.5 系列模型采用异构混合并行和分层负载均衡策略,结合 FP8 混合精度训练和细粒度重计算方法,显著提升了预训练吞吐量。推理阶段则引入多专家并行协作方法和卷积码量化算法,实现 4-bit/2-bit 的无损量化,提升了模型的推理性能。
性能评估显示,文心 4.5 系列模型在多个文本和多模态基准测试中达到 SOTA 水平,尤其在指令遵循、世界知识记忆、视觉理解和多模态推理任务上表现突出。例如,ERNIE-4.5-300B-A47B 模型在 28 个基准测试中超过了 DeepSeek-V3 模型,ERNIE-4.5-21B-A3B 模型在多个数学和推理任务中表现出竞争力。
03|华为首次开源盘古 7B 稠密与 72B MoE 模型
6 月 30 日,华为正式宣布开源其盘古大模型的核心能力,涵盖 70 亿参数的稠密模型 盘古 Embedded 7B 和 720 亿参数的混合专家模型 盘古 Pro MoE 72B。此次开源还包括基于昇腾 AI 平台的模型推理技术,标志着华为在构建自主 AI 生态系统方面迈出了关键一步。
盘古 Pro MoE 72B 模型采用华为自研的分组混合专家架构(Mixture of Grouped Experts, MoGE),通过将专家划分为多个分组,并在每个分组内激活等量的专家,实现了跨设备的计算负载均衡,显著提升了训练和推理效率。该模型在昇腾 800I A2 平台上实现了单卡 1148 tokens/s 的推理吞吐性能,借助投机加速技术可进一步提升至 1528 tokens/s,性能优于同等规模的稠密模型。
盘古 Embedded 7B 模型引入了“快思考”和“慢思考”的双系统框架,能够根据任务复杂度自动选择合适的推理模式,在延迟和推理深度之间实现平衡。在多项复杂推理测试中,该模型的表现优于阿里巴巴的 Qwen3-8B 和智谱的 GLM4-9B 等同规模模型。
目前,盘古 Pro MoE 72B 和 盘古 Embedded 7B 模型的权重和基础推理代码已在开源平台上线,开发者可通过 GitCode 平台获取相关资源:https://gitcode.com/ascend-tribe。
04|阿里通义开源 AI 音频生成模型 ThinkSound
7 月 4 日,阿里通义实验室正式开源其首个音频生成模型 ThinkSound,该模型首次将“思维链”(Chain-of-Thought, CoT)推理机制引入音频生成领域,模拟专业音效师的创作流程,实现音画同步的高保真音频生成。ThinkSound 支持从视频、文本、音频等多种模态输入生成音频,广泛适用于影视后期、游戏开发、无障碍视频制作等场景。
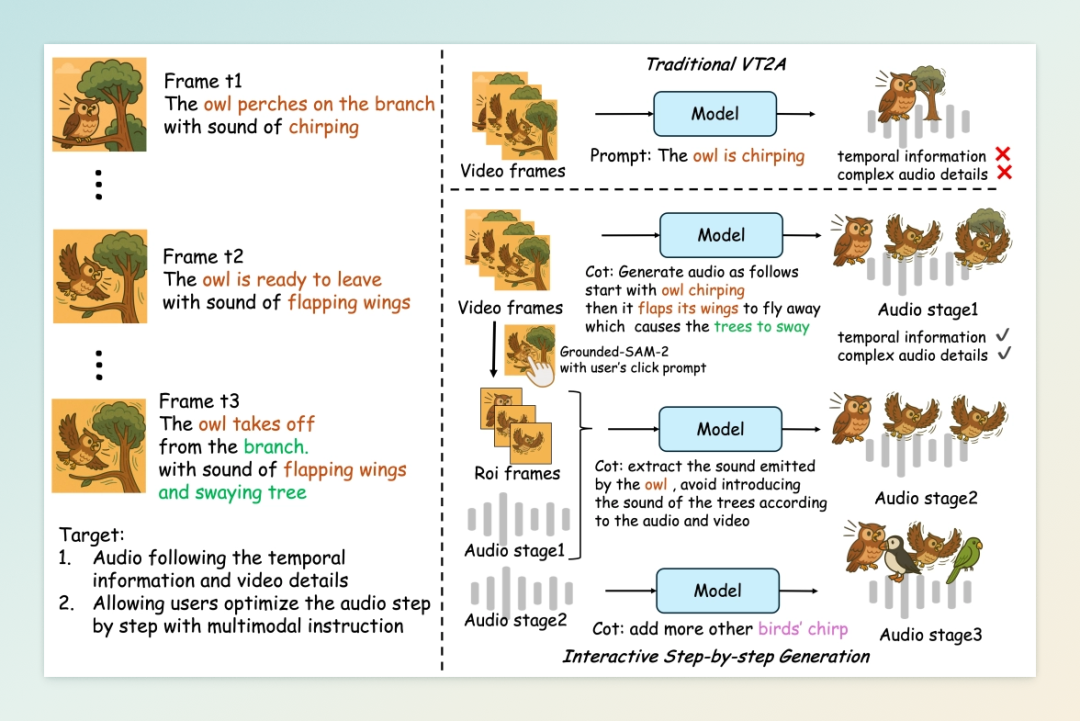
ThinkSound 的核心创新在于其三阶段推理架构:首先,模型解析视频中的视觉事件,识别关键动作和物体材质;其次,推导相应的声学属性,如频谱特性和空间反射;最后,进行时序对齐合成,确保音频与视频帧的精准同步。这一流程显著提升了音画同步的精度,将传统手工音效制作中耗时数小时的工作压缩至分钟级完成。
在性能评估方面,ThinkSound 在 VGGSound 测试集上表现优异,Fréchet 音频距离降至 34.56,较此前主流模型 MMAudio 提升 20.1%;时序对齐误差率仅为 9.8%,同比降低 37.2%。此外,阿里团队还构建了全球首个带思维链标注的音频数据集 AudioCoT,包含 2531.8 小时的多源异构数据,为模型提供了丰富的训练素材。
目前,ThinkSound 提供三种模型规模(1.3B、724M、533M),已在 GitHub、HuggingFace、魔搭社区等平台开源,开发者可免费下载体验。
05|智谱联合清华开源视觉推理模型 GLM-4.1V-Thinking
7 月 2 日,智谱 AI 与清华大学 KEG 实验室联合发布并开源了全新视觉语言模型系列 GLM-4.1V-Thinking,主打 90 亿参数规模的 GLM-4.1V-9B-Thinking 模型。该模型引入“思维链推理”(Chain-of-Thought Reasoning)机制,并结合课程采样强化学习(RLCS)策略,显著提升了模型在多模态任务中的推理能力和稳定性。
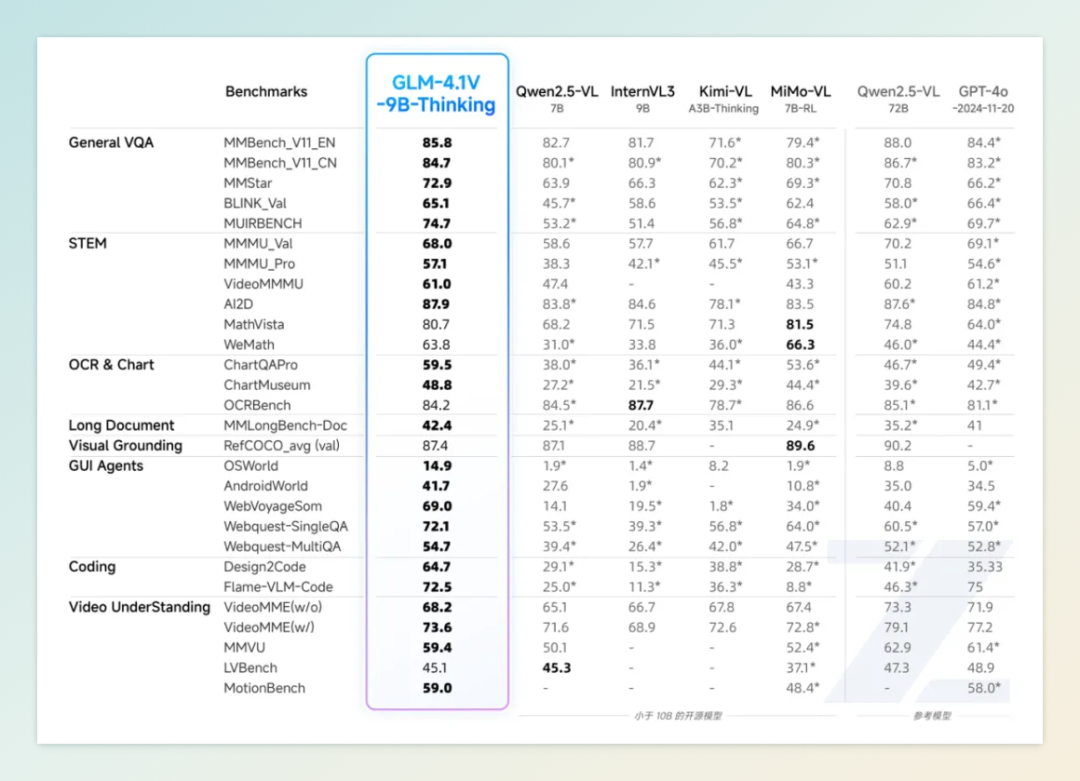
在 28 项权威评测中,GLM-4.1V-9B-Thinking 在 23 项任务中取得了 10B 级别模型的最佳成绩,其中 18 项任务的表现持平或超越了参数量高达 72B 的 Qwen-2.5-VL-72B 模型,展现出小体积模型的极限性能潜力。
该模型支持图像、视频、文档等多模态输入,具备图文理解、数学与科学推理、视频理解、GUI 与网页智能体任务、视觉锚定与实体定位等多项能力。在架构设计上,GLM-4.1V-9B-Thinking 采用 AIMv2-Huge 作为视觉编码器,结合 MLP 适配器和 GLM 语言解码器,支持 64k 上下文长度和高达 4K 的图像分辨率。
目前,GLM-4.1V-9B-Thinking 模型已在 GitHub、Hugging Face 和 ModelScope 等平台开源,供研究者和开发者使用。
06|谷歌 AI 视频模型 Veo 3 面向全球开放
7 月 3 日,谷歌官宣其最新一代 AI 视频生成模型 Veo 3 正式向全球 159 个国家和地区的 Gemini 应用 Pro 会员开放使用。此前仅限于 Ultra 会员的高级功能,如今 Pro 用户每人每天可生成 3 个 8 秒钟、720p 分辨率的短视频,超出配额后将回退至 Veo 2 模型。这一扩展使更多创作者能够体验 Veo 3 的高质量视频生成能力。
Veo 3 是谷歌 DeepMind 于 2025 年 I/O 大会上发布的旗舰级文生视频模型,支持文本或图像提示生成视频,并可同步生成对话、背景音效和环境音。其核心优势在于对现实物理的模拟、精确的唇形同步以及更强的叙事理解能力。Google 表示,未来还将上线“照片生成视频”(Photo-to-Video)功能,进一步拓展创作场景。
为确保内容安全,所有由 Veo 3 生成的视频均嵌入可见水印和不可见的 SynthID 数字水印,以标识其为 AI 生成内容。尽管如此,近期仍有用户利用该工具生成带有种族歧视内容的视频在 TikTok 等平台传播,引发了对 AI 内容审核机制的关注。
目前,Veo 3 可通过 Gemini 应用或谷歌 Flow 平台使用,Pro 会员月费为 19.99 美元,Ultra 会员则需 249.99 美元。对于希望尝试的用户,谷歌还提供了通过 Google Cloud 免费试用 Veo 3 的途径,享受为期 3 个月的免费体验。
07|xAI Grok 4 模型细节意外曝光
7 月 2 日,开发者在 xAI 控制台的源代码中意外发现了两个未发布的模型:Grok 4 和 Grok 4 Code,引发了业界的广泛关注。据泄露信息显示,Grok 4 被定位为 xAI 的最新旗舰模型,旨在提供卓越的自然语言处理、数学推理和多模态理解能力。而 Grok 4 Code 则是专为开发者设计的编程助手,计划集成至代码编辑器,如 Cursor,支持实时代码生成与调试,直接挑战 GitHub Copilot 等现有工具。
此次曝光恰逢 xAI 宣布跳过原定的 Grok 3.5,直接推出技术跃迁更大的 Grok 4。马斯克在社交平台上表示,Grok 4 将于 7 月 4 日后发布,具备更强的推理能力和实时任务处理性能。此外,xAI 还获得了 100 亿美元的新一轮融资,估值飙升至 1130 亿美元,显示出其在 AI 领域的雄心。
值得注意的是,Grok 4 的训练理念颇具争议。马斯克提出“重写人类知识库”的目标,旨在通过纠正错误、填补空白和清洗数据,构建更准确、可靠的 AI 模型。这一策略可能对现有的知识体系产生深远影响,也引发了对 AI 训练数据选择和处理方式的讨论。
08|马斯克 xAI 宣布成功筹集 100 亿美元资金
7 月 1 日,埃隆·马斯克旗下的人工智能公司 xAI 宣布成功筹集 100 亿美元资金,其中包括 50 亿美元的债务融资和 50 亿美元的股权投资。此次融资由摩根士丹利牵头,债务部分包括浮动利率的定期贷款和固定利率的担保票据,年收益率约为 12% 至 12.5%。股权投资则吸引了包括 Andreessen Horowitz、红杉资本、BlackRock、Fidelity、NVIDIA、AMD 以及沙特王国控股公司在内的多家顶级机构参与。

这笔资金将主要用于扩展 xAI 的旗舰产品 Grok AI 聊天机器人平台,以及在美国孟菲斯建设全球最大的 AI 超级计算机 Colossus。目前,Colossus 已部署约 20 万个 GPU,xAI 计划到 2027 年将其扩展至 100 万个 GPU,打造全球最大的 AI 集群。此外,xAI 还在孟菲斯购买了第二个占地 100 万平方英尺的场地,用于进一步的数据中心扩展,预计可容纳多达 35 万个 GPU。这些数据中心将配备全球最大的特斯拉 Megapack 电池部署,用于备份电源。
此次融资使 xAI 的估值达到 800 亿美元,并计划进一步筹集高达 200 亿美元的股权融资,目标估值在 1200 亿至 2000 亿美元之间。尽管 xAI 自 2023 年以来已筹集了 140 亿美元的股权资金,但截至 2025 年第一季度末,公司仅剩约 40 亿美元现金,预计在第二季度末前将全部支出,反映出每月约 10 亿美元的现金消耗率。2025 年的预计收入约为 5 亿美元,预计到 2029 年将增长至 140 亿美元,并在 2027 年实现正向 EBITDA。
09|Perplexity 推出 200 美元/月 的 Max 订阅计划
7 月 2 日,AI 搜索平台 Perplexity 正式推出其全新高端订阅服务 Perplexity Max,月费高达 200 美元,年付则为 2000 美元。该计划旨在满足专业用户对先进 AI 工具的需求,提供无限制的使用权限和优先体验。

Perplexity Max 订阅者将享受以下核心权益:
-
先进模型优先使用权:包括 OpenAI 的
o3-pro和 Anthropic 的Claude Opus 4,以及未来推出的前沿模型。 -
无限制 Labs 访问:用户可无限制地使用 Labs 工具,创建报告、仪表板、演示文稿和网页应用等。
-
新功能抢先体验:如即将推出的 AI 浏览器 Comet,Max 用户将优先获得使用权。
-
专属客户支持:提供快速响应和专属基础设施支持,确保用户问题得到及时解决。
该订阅计划主要面向内容创作者、商业策略师、学术研究人员等对 AI 工具有高需求的专业用户。Perplexity 表示,未来还将推出面向企业的 Max 版本,以满足组织级别的使用需求。
10|Cursor 推出网页端和移动端 Agent
7 月 1 日,AI 编程平台 Cursor 的开发公司 Anysphere 正式发布了其网页应用,允许用户通过桌面或移动浏览器直接管理 AI 编码智能体网络。这一举措标志着 Cursor 从集成开发环境(IDE)向多平台协作工具的扩展,进一步提升了开发者的工作灵活性与效率。
新推出的网页应用支持用户以自然语言指令分配任务,如编写新功能、修复 Bug 等,AI 智能体将自动执行这些任务。用户可以实时监控智能体的工作进度,查看代码差异,并将完成的更改合并到代码库中。此外,每个智能体任务都配有可分享的链接,方便团队成员之间的协作与进度跟踪。
目前,Cursor 的网页应用对订阅了 Pro 计划(20 美元/月)及以上的用户开放,免费用户暂时无法使用此功能。 Anysphere 表示,此次发布旨在“消除用户在使用 Cursor 时的摩擦”,让 AI 编码助手无处不在,随时可用。
11|Meta 超级智能实验室 11 人顶级团队首曝光
7 月 1 日,Meta 首席执行官马克·扎克伯格宣布成立全新 AI 研发机构 Meta 超级智能实验室(Meta Superintelligence Labs,简称 MSL),旨在推动开发具备超越人类能力的通用人工智能(AGI)系统。该实验室整合了 Meta 内部的 Llama 大模型团队、FAIR 基础研究部门和 AI 产品团队,并设立专门研发下一代模型的新实验室。此举标志着 Meta 在 AI 领域的战略重组和加速发展。
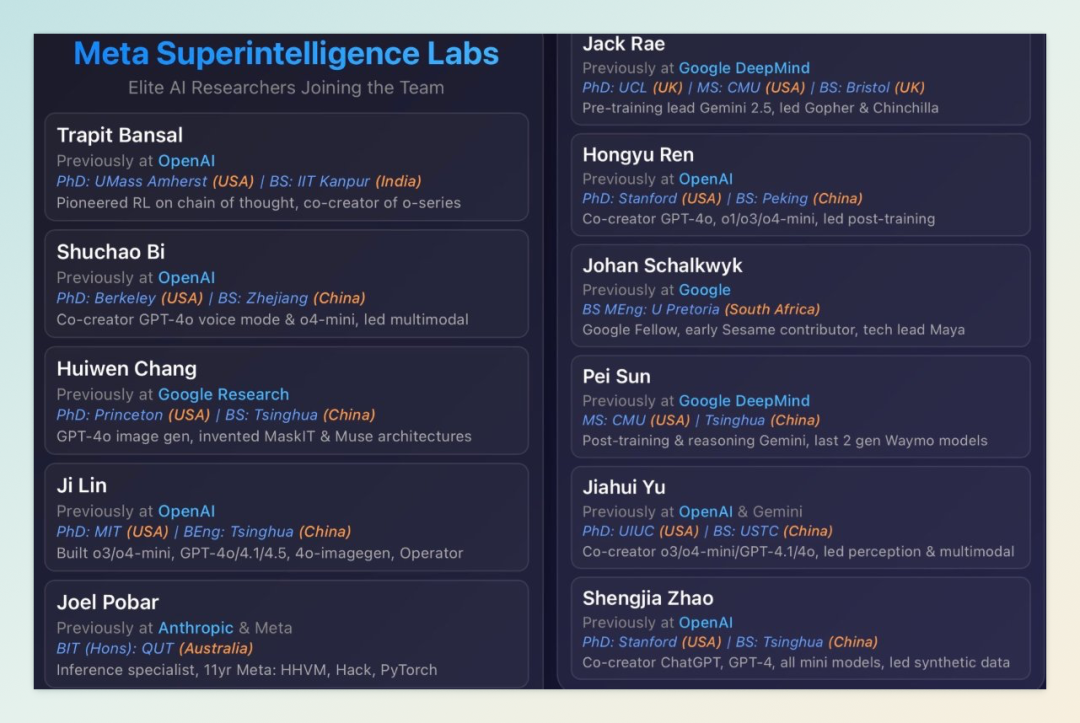
MSL 由前 Scale AI 首席执行官 Alexandr Wang 担任首席 AI 官(Chief AI Officer),联合前 GitHub 首席执行官 Nat Friedman 共同领导。此外,Safe Superintelligence(SSI)联合创始人 Daniel Gross 也加入了 MSL。为组建顶尖团队,Meta 从 OpenAI、Anthropic、谷歌 DeepMind 等公司挖掘了 11 位 AI 领域的杰出人才,其中包括多位华人科学家:
-
Trapit Bansal:思维链(CoT)强化学习技术开创者,OpenAI o系列模型共同创建者。 -
Shuchao Bi: GPT-4o语音模式与o4-mini共同创建者,曾任 OpenAI 多模态后训练负责人。 -
Huiwen Chang: GPT-4o图像生成系统共同创建者,Google Research 期间发明MaskGIT及Muse文生图架构。 -
Ji Lin:参与开发 o3、o4-mini、GPT-4o、GPT-4.1、GPT-4.5、4o-imagegen及Operator推理框架。 -
Joel Pobar:Anthropic 推理系统专家,此前在 Meta 任职 11 年主导 HHVM、Hack、Flow、Redex开发及性能工具与机器学习。 -
Jack Rae: Gemini预训练技术负责人及Gemini 2.5推理架构师,DeepMind 时期主导Gopher、Chinchilla早期大模型研发。 -
Hongyu Ren(任泓宇): GPT-4o、4o-mini、o1-mini、o3-mini、o3、o4-mini共同创建者,曾任 OpenAI 后训练团队主管。 -
Johan Schalkwyk:前 Google Fellow, Sesame系统早期贡献者,Maya项目技术主管。 -
Pei Sun:谷歌 DeepMind Gemini后训练 / 编程 / 推理架构师,曾主导 Waymo 近两代感知模型开发。 -
Jiahui Yu(余家辉): o3、o4-mini、GPT-4.1、GPT-4o共同创建者,曾任 OpenAI 感知团队负责人,Gemini多模态系统联合主管。 -
Shengjia Zhao: ChatGPT、GPT-4、4.1、o3共同创建者,曾任 OpenAI 合成数据团队主管。
据报道,Meta 为吸引这些顶尖人才,提供了高达 1 亿美元的签约奖金。
12|谷歌联合普林斯顿大学发布认知预测模型 Centaur
由德国 Helmholtz AI 研究计划、谷歌 DeepMind、普林斯顿大学等机构联合开发的通用型 AI 模型 Centaur,近日正式发布。该模型在《自然》杂志发表的研究中展示了其在大规模认知任务中预测人类行为的能力,标志着人工智能在理解和模拟人类认知方面迈出了重要一步。
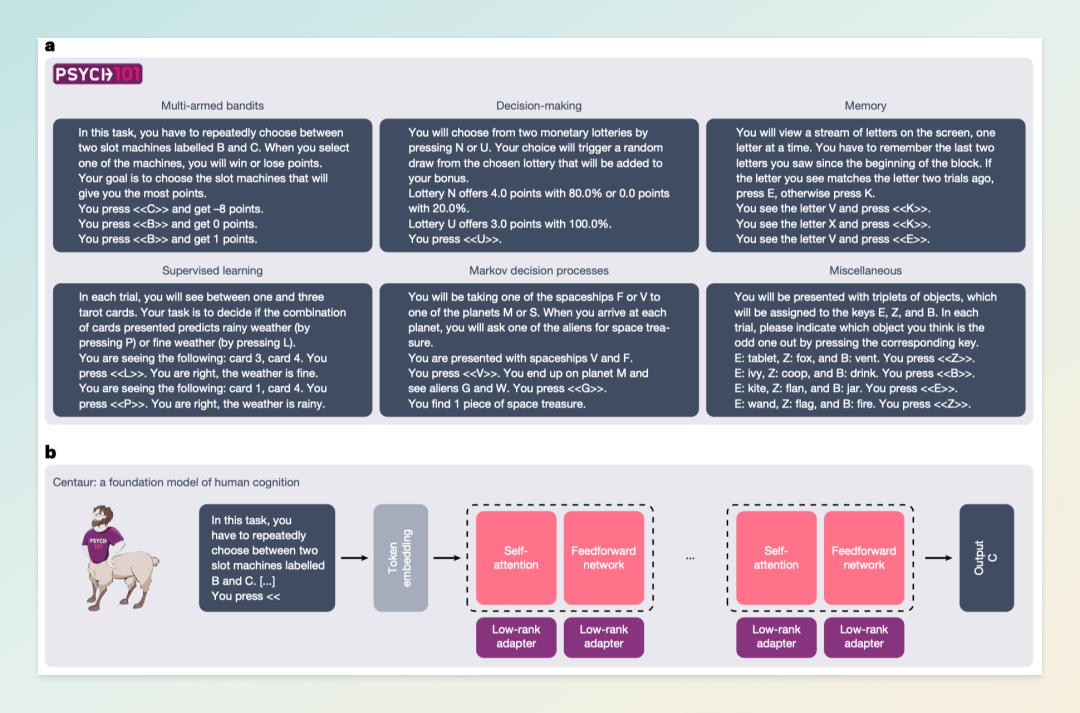
Centaur 基于 Meta 的 Llama 3.1 大型语言模型,通过对名为 Psych-101 的数据集进行微调而成。该数据集包含来自 160 项心理学实验中超过 60,000 名参与者的 1,000 万次决策记录,涵盖记忆测试、风险决策、道德判断等多种任务。研究团队采用 QLoRA 技术,仅调整了模型 0.15% 的参数,使 Centaur 能够在保持高效的同时,准确预测人类在不同情境下的行为。
在测试中,Centaur 在 32 项任务中的 31 项中表现优于传统的认知模型,如前景理论和强化学习框架。尤其值得注意的是,Centaur 能够在未曾训练过的新任务中保持高预测准确性,显示出其强大的泛化能力。此外,研究还发现,Centaur 的内部表示与人类在执行相同任务时的 fMRI 脑部活动模式高度一致,进一步验证了其在模拟人类认知过程中的潜力。
研究团队表示,Centaur 的发布为心理学研究提供了一个“虚拟实验室”,可以在不依赖实际参与者的情况下,模拟和分析人类的决策过程。这对于研究儿童、精神疾病患者等难以招募的群体尤为重要。未来,团队计划扩展 Psych-101 数据集的多样性,并对 Centaur 进行进一步的外部验证,以增强其在不同人群中的适用性。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)