
最近的国产 AI 圈,是真的热闹。
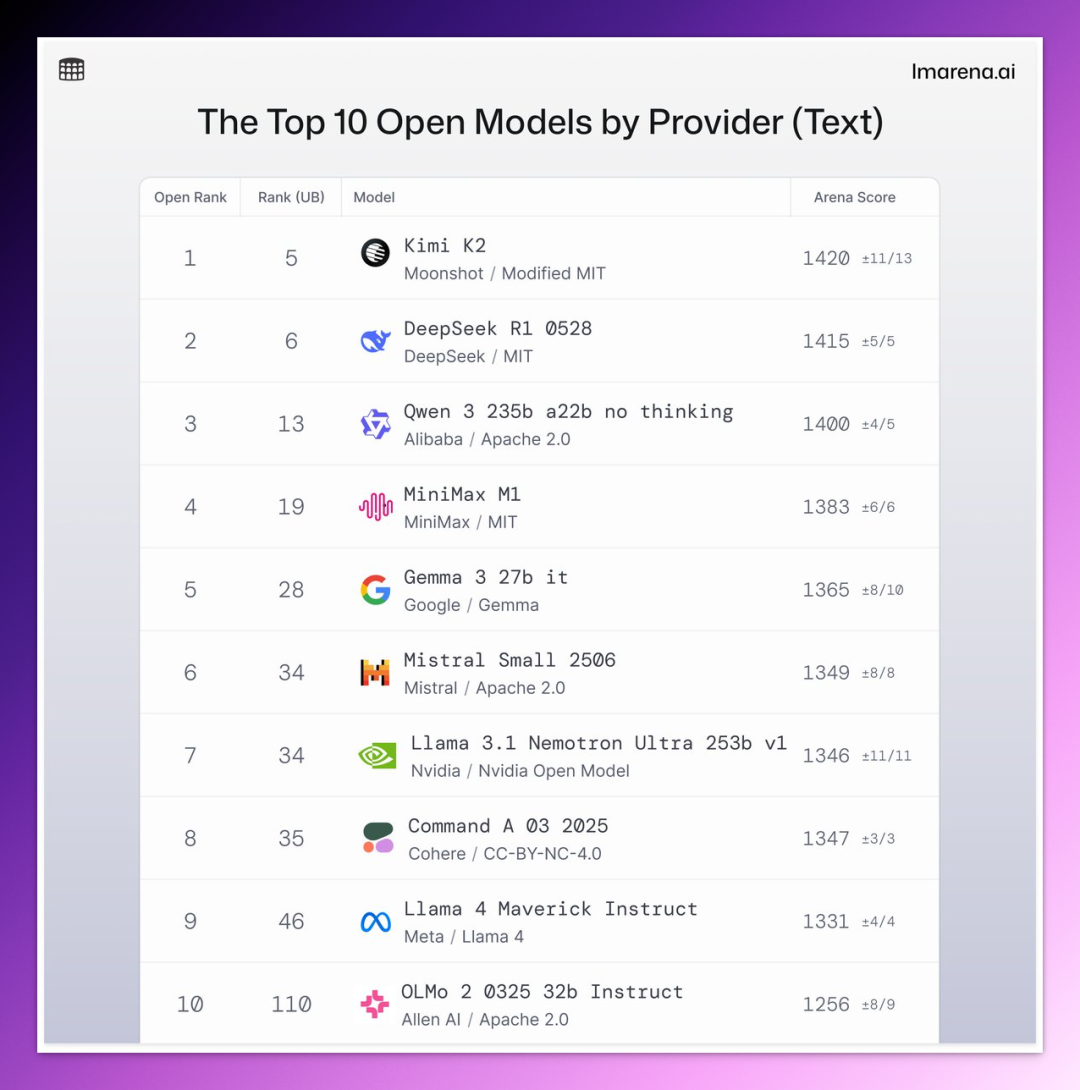
就在上周,月之暗面凭借 Kimi K2,一举击败 DeepSeek、阿里 Qwen、Meta Llama,坐上了全球开源模型排行榜的头把交椅。
不过这个“第一”的位置还没捂热,阿里 Qwen 就突然发力,在两天内连续发布两个新模型反击:Qwen3-235B-A22B-Instruct-2507 和 Qwen3-Coder。
虽然名义上只是“小版本升级”,关注度和实力却一点不小。
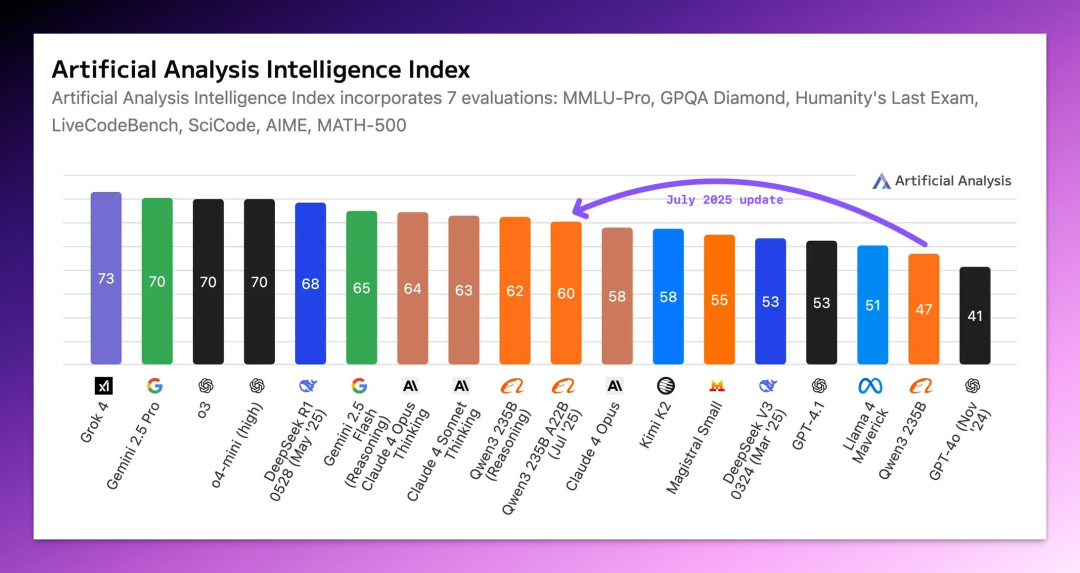
Artificial Analysis 排行榜直接发文:“Qwen3-235B-A22B-Instruct-2507 是目前最强的非推理模型,在 Artificial Analysis 指数上超过了 Kimi K2 和 Claude 4 Opus(非推理)!”
那么,这波更新,到底实力如何?
今天就来聊聊阿里 Qwen 的这两个新模型。
01|Qwen3-235B-A22B-Instruct-2507
见名知意。
Qwen3-235B-A22B-Instruct-2507 就是前代模型 Qwen3-235B-A22B 在非思考模式下的一次升级迭代。
之所以强调“非思考模式”,是因为原始版本本身就带有一个非常有意思的设定:混合推理(Hybrid Reasoning)。
简单来说,就像是“一个模型,两个大脑”。遇到简单任务,模型能够不假思索地回答(快思考);但面对复杂难题,模型就会自动切换到推理模式(慢思考)。
而这次发布的 2507 版本,可以看作是对这种“混合架构”的一次拆分。它就是一个纯非推理模型,不再走思维链,主打响应速度、稳定表现,定位更贴近 DeepSeek-V3 和 GPT-4o 这种通用模型。
性能方面,从基准测试结果来看,2507 撑得起 Artificial Analysis 排行榜官方对它的评价。
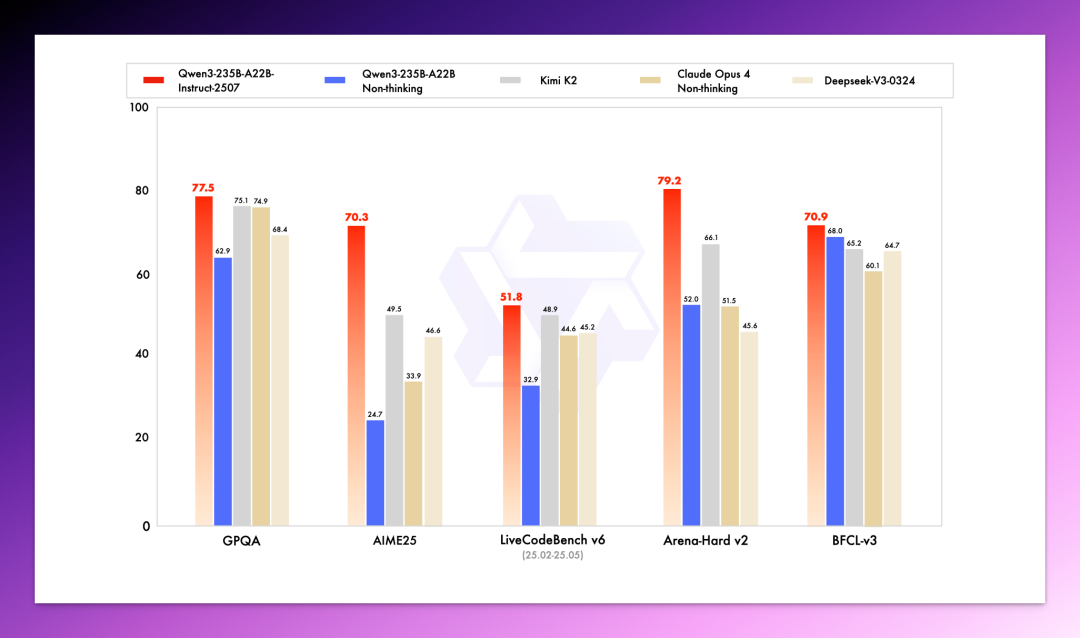
在 GPQA(知识推理)、AIME25(数学)、LiveCodeBench(编程)、Arena-Hard(对齐)、BFCL(Agent 工具使用)这五项测试中,几乎所有指标 2507 都拿下了非推理模型的最高分,平均领先第二名在 5~15 分不等。
尤其是 AIME25,2507 得分 70.3%,远超前代模型的 24.7%、Kimi K2 的 49.5% 和 Claude Opus 4 的 33.9%。这对于一个非推理模型来说,属于实打实的提升了。
另外值得一提的是,2507 的上下文长度已由原来的 131K 提升到了 256K。
当然,基准测试亮眼,实际体验拉跨的模型我们见的也不是一个两个了,所以,2507 具体怎么样,是否符合你的预期,还需要以真实体验为准。
要使用 2507 也很简单,在 qwen.ai 进入 Qwen Chat,左上角 模型选择 菜单里选 Qwen3-235B-A22B-2507 就行。
完全免费,支持 网页、iOS/安卓 app、以及 macOS 桌面客户端。
02|Qwen3-Coder
相比 2507 的通用,Qwen3-Coder 明显更加垂直 —— “为代码而生”。
据阿里官方的说法,这次发布的是当前最强版本:Qwen3-Coder-480B-A35B-Instruct。
采用 MoE 架构,480B 总参数、35B 激活参数,原生上下文支持 256K,借助 YaRN 甚至可以扩展至 100 万 tokens。
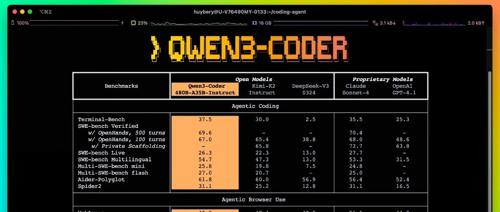
在官方提供的评测结果中,Qwen3-Coder 在 Agentic Coding、Browser-Use 和 Tool-Use 等多个“代理式编程”任务上,都实现了开源模型的 SOTA(State of the art,最优)表现,甚至在部分场景上对标 Claude Sonnet-4。

和 Qwen3-Coder 模型配套的,还有一整套命令行工具。这意味着它不仅能“在线使用”,还可以直接“接入开发环境”,上手即用。
-
Qwen Code(命令行工具):基于
Gemini CLI改造而来(从上面的截图也能看出来),支持 OpenAI SDK 接入,安装门槛低、适配好; -
Claude Code:支持通过阿里云百炼 API 适配
Claude Code工具,原地切换后端模型; -
Cline:可在
Cline工具中通过 DashScope 接入Qwen3-Coder。
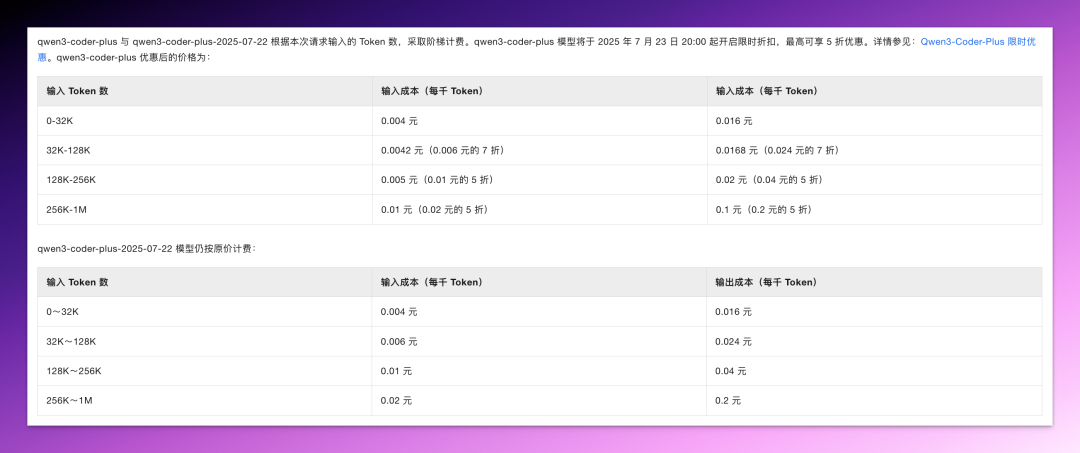
这里不得不提醒一下各位小可爱,如果你是通过阿里云百炼使用 Qwen3-Coder 的 API,需要多加注意它的模型命名和阶梯定价规则。
目前最新的模型版本是 qwen3-coder-plus-2025-07-22,而常见的 API 名称 qwen3-coder-plus 实际上也是指向这个 0722 版本。但区别在于,只有 qwen3-coder-plus 这个别名启用了限时折扣,而直接用全名的 0722 版本则是按原价收费。
同时,阶梯定价意味着随着你聊的越来越多,上下文长度会越来越长(上下文累积),费用也会越来越高。举个极端的例子,256K-1M 的成本能达到 20 元/百万输入 tokens,200 元/百万输出 tokens(原价,人民币)。
一句话总结:越聊越贵。
结语
表面平静,实则暗流汹涌。
国产大模型的竞争,正在悄悄提速。
从 Kimi K2 的突然登顶,到阿里 Qwen 的快速反击,再到像 Qwen3-Coder 这样更偏工程落地的新路线,一个明显的信号是:
开源模型不再只是跑分,而是真正在往“能用”、“好用”靠近。
这或许,才是开源模型真正的下一步。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)