

这个夏天,注定不平静。
GPT-5、Grok 4、DeepSeek-R2,有太多值得期待的新模型。
上周,我在《马斯克新模型曝光:Grok 4 和 Grok 4 Code 现身 xAI 控制台!》这篇文章中记录了马斯克 xAI 新模型的细节爆料。
而就在本周末,一组疑似 Grok 4 / Grok 4 Code 模型的基准测试截图突然流传开来。
这些数据虽只是“源码爆料”,并没有被 xAI 官方认证,但其“亮眼程度”,如果真实,足以掀起不小波澜。
最原始的数据源于下面这张截图。

后被有心的网友总结了一下。

单看 Grok 4 / Grok 4 Code 的测试数据,感受不是那么直观。如果和其他顶级模型的结果放在一起,对比将会一目了然。
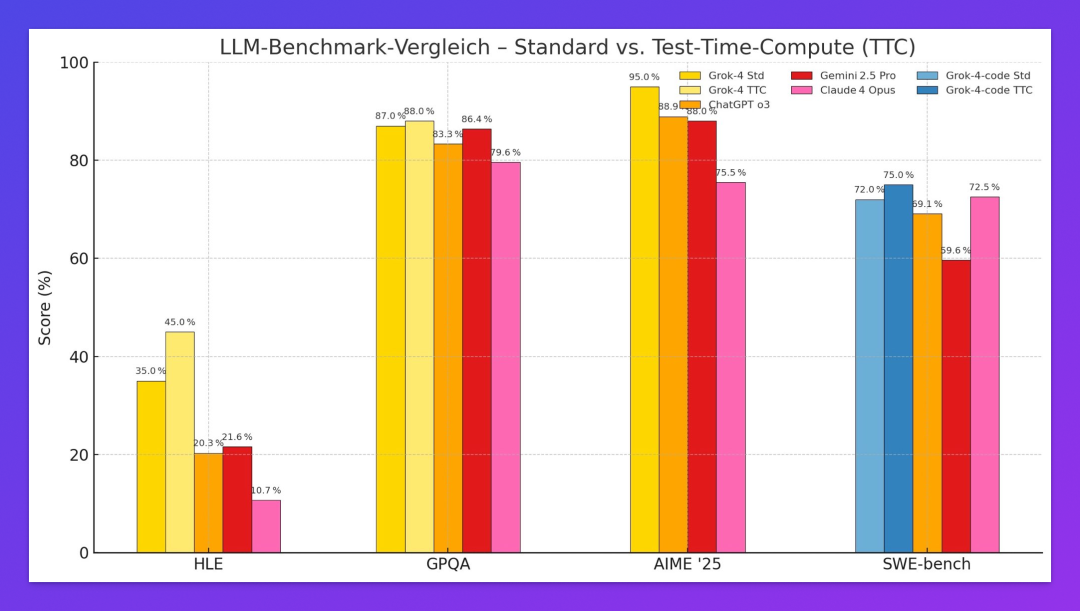
特别说明:这组基准测试数据主要来自 X 平台及媒体爆料,非 xAI 官方公布,真实性仍需验证。
01|HLE:Grok 4 成为首个突破 30% 警戒线的模型?
这里面最值得一提的,就是被称为“人类最后一场考试”的 HLE。
HLE,全称 Humanity’s Last Exam,是近年来被广泛引用的“AI 高阶能力”标杆测试,最新版包含 2500 道题目,范围涵盖哲学、社会学、伦理等复杂跨学科题目。
从名字也能看出这个基准测试有多“硬核”。据官方表示,博士级人类专家的准确率仅约为 65%,而高素质非专家的平均准确率为 34%。
在这样一个极有挑战的评估体系中,Grok 4 以标准模式 35%,推理增强模式 45% 的成绩遥遥领先。当然,前提是这个数据是真实无误的。如果真是如此,Grok 4 很可能成为首个正式在 HLE 上“越线” 30% 的通用大模型,而 45% 更接近“非专家人类”的表现区间。
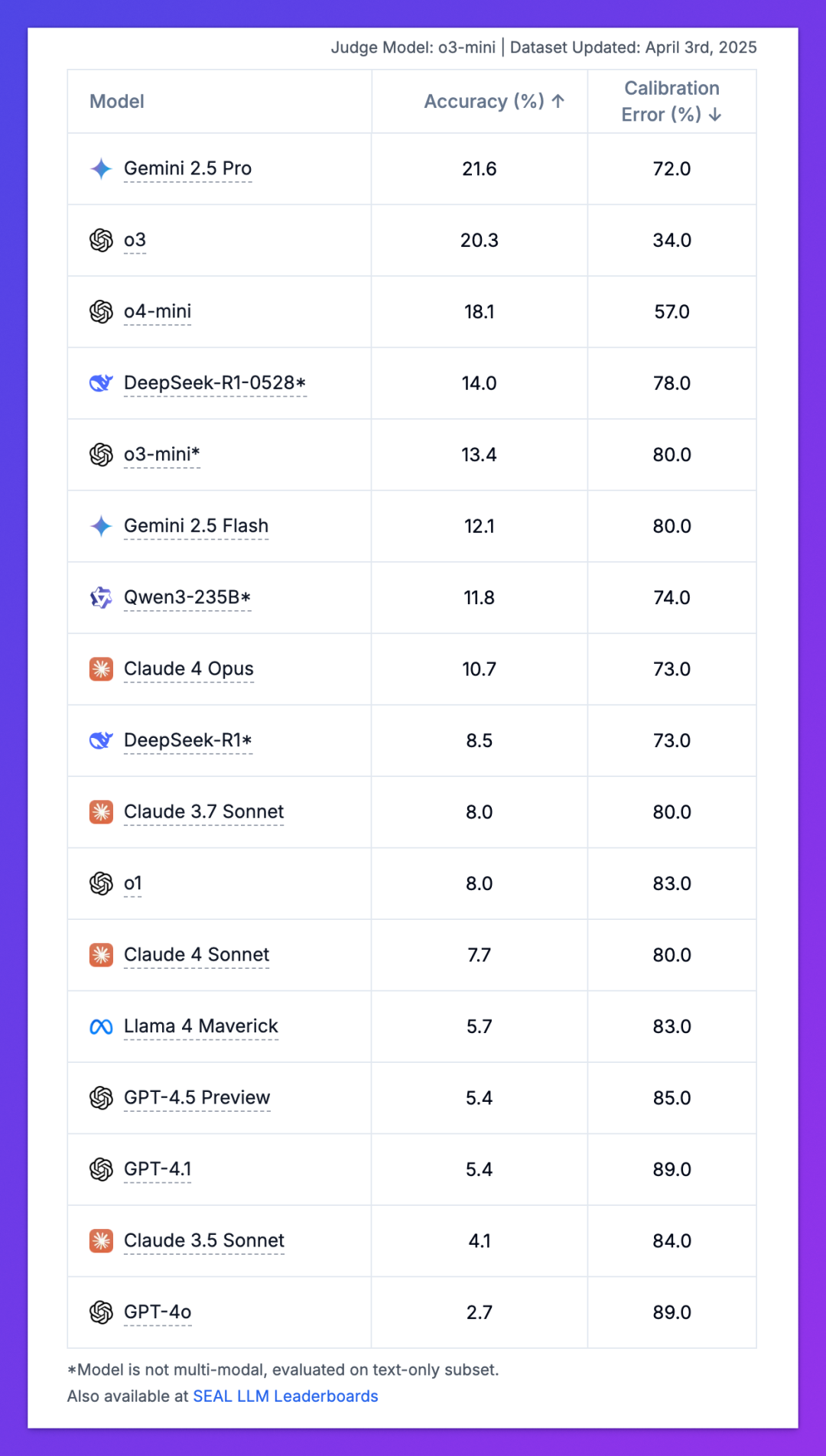
根据 HLE 最新排行,目前排名第一的 Gemini 2.5 Pro 也仅有 21.6% 的准确率。国产之光 DeepSeek-R1 0528 则以 14.0% 的准确率排在第四名。
02|GPQA:知识问答能力超越主流模型
GPQA(Graduate-Level Google-Proof Q&A)则是由麻省理工、UC Berkeley 等机构研究人员发起的研究生水平测评集,涵盖物理、生物、化学等学科难题,对模型推理和精准检索能力要求极高。
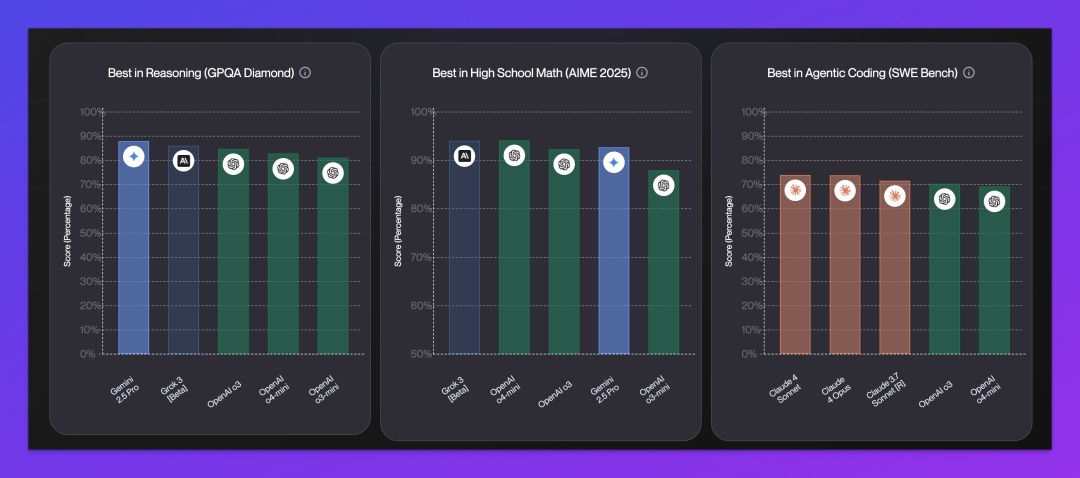
爆料数据中,Grok 4 在该项测试中拿下了 87-88% 的高分,超越 Gemini 2.5 Pro(86.4%)、o3(83.3%)和 Claude Opus 4(79.6%)。
尤其值得一提的是,GPQA 属于“Google-proof QA”,即便开放联网搜索,非专业人类的平均正确率也只有 34%。
这意味着当前的顶级模型可能并非靠“关键词”答对题目,而是真的具备跨知识领域的深度理解能力。
03|SWE-Bench:编程能力直逼 Claude
SWE-Bench 是目前最受认可的真实软件工程测试集(之一),任务包括修复代码 Bug、生成 PR、调试等,直接评估模型能否胜任复杂开发任务。
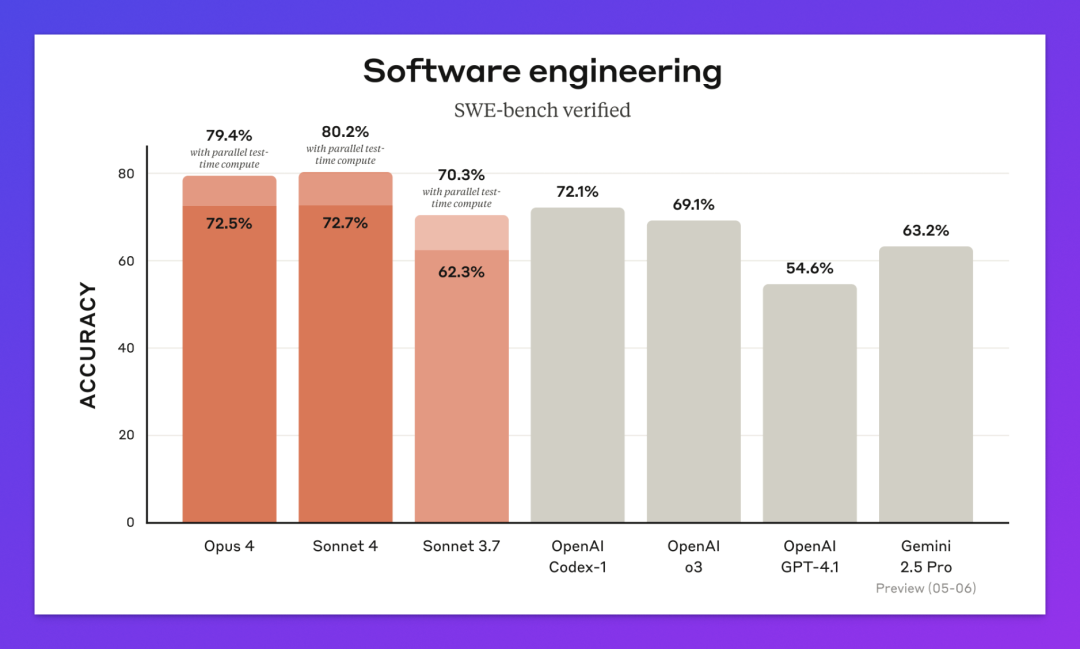
根据爆料,Grok 4 Code 在 SWE-Bench 上得分 72-75%,标准模式已接近目前公认“最强编程模型” Claude 4 Opus(72.5%)。
作为对比,GPT-4o 在相同测试中表现为 54%-56%,而 Gemini 2.5 Pro 约为 63.2%。
此外,还有传言表示 Grok 4 Code 内嵌 Agentic 编程模式,能够和 IDE 协同完成代码诊断、逻辑追踪等任务,若属实,将大幅提升“开发者友好度”。
结语
如果数据属实,那 Grok 4 厉害了,有望成为下一个 SOTA 模型。
就这几天,等实锤。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)