速递|英伟达黄仁勋强调DeepSeek利好英伟达,将2025年实现强劲增长

Nvidia CEO 黄仁勋在财报电话会议上重申DeepSeek不会影响销售,并强调其旗下的R1模型对Nvidia来说是重大利好消息。黄仁勋还宣布NVIDIA专为推理定制的最新Blackwell芯片需求强劲,公司收入创纪录达到393亿美元。
Nvidia CEO 黄仁勋在财报电话会议上重申DeepSeek不会影响销售,并强调其旗下的R1模型对Nvidia来说是重大利好消息。黄仁勋还宣布NVIDIA专为推理定制的最新Blackwell芯片需求强劲,公司收入创纪录达到393亿美元。

文章介绍了Claude 3.7 Sonnet混合推理模型的编程能力及其性能表现,并展示了其在生成HTML/CSS/JavaScript代码、AI小游戏开发以及终端编程工具等方面的使用案例。

阿里发布Qwen Chat中的新模型’思考(QwQ)’,基于Qwen2.5-Max的推理模型,支持思考、联网和Agent工具。预览版本在数学理解、编程和代理方面表现优异,计划于近期开放源代码并发布正式版APP。

DeepSeek R1 在 think 过程中的需求和问题引起了广泛关注,包括输出思考过程的需求、过长或过短的思考时间以及控制思考方向。文章探讨了这些问题,并提出了通过调整模型设置、修改prompt模板和干预token解码采样的方法来解决。
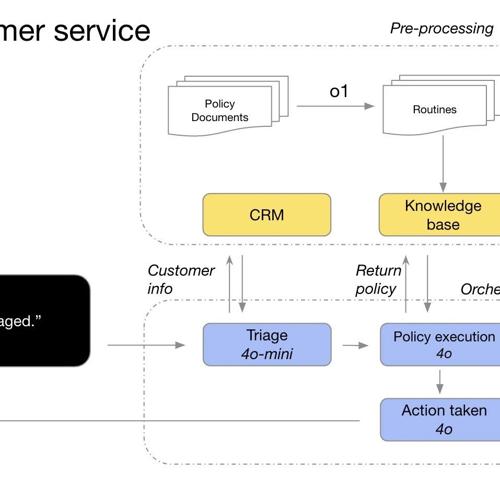
OpenAI发布了推理模型的最佳实践,包括何时使用这些模型(如模糊任务、大海捞针)、如何有效利用以及一些基本原则和技巧。

马斯克试水20万卡GPU训练的Grok3表现强于现有多数模型,在Math、Science和Coding任务上优于DeepSeek-V3和GPT4o等模型,但与Colossus相比参数量仍不足,预训练规模限制了其性能提升。

R1 发布后,国内外多个云平台迅速部署,并邀请火山引擎专家分享 R1 使用经验。主要讨论企业如何使用推理模型、接入策略及未来方向。