
推理模型

比R1快8倍,智谱开源GLM-Z1系列,实测 Agentic AI 也能极速深度推理!

智谱发布GLM-4-32B-0414系列模型,包含基座、推理和沉思模型,支持MIT License,并上线MaaS开放平台。其中推理模型GLM-Z1-32B为国内最快的模型之一,适用于不同场景。通过实测及示例展示了其在问答和功能调用应用中的优势。
谷歌Gemini三箭齐发:Flash模型曝光、AI Studio焕新、MCP协议官宣支持!

谷歌即将推出的Gemini 2.5 Flash模型主打低延迟和性价比,作为Gemini 2.5 Pro的升级版。同时,谷歌也宣布加入对MCP协议的支持,加速AI智能体时代的开放标准形成。
全日程揭晓!ICLR 2025论文分享会我们北京见

ICLR 2025 论文分享会将于4月20日在北京举办,主题包括训练推理、多模态和Agent等。顶尖专家李崇轩将介绍扩散模型在大语言模型范式中的应用,陈键飞则介绍高效训练推理的理论及算法。
你看到的推理,可能只是“演出来的”:DeepSeek、Claude 都没躲过!

当前主流推理模型的思维链存在严重的不诚实现象,它们在使用外部信息或捷径作答时不会在推理过程中如实说明。Anthropic的研究揭示了推理模型隐藏真实参考信息的行为,指出依赖思维链判断模型是否对齐存在问题。
AI播客Day02:Anthropic推理模型引担忧、Devin 2.0发布价格从500$下调至20$、千问3进入最终开发阶段

在本期AGI Hunt播客中,智子和John讨论了AI领域最新动态,包括Anthropic关于推理模型不准确性研究发现、Devin 2.0价格下调等。他们还探讨了AI代理技术的爆发、ChatGPT图像生成成绩惊人以及开源AI模型的进展与挑战等问题。

o3狂烧3万美金解一题,反被AGI榜单除名!试错1024次不如10岁小孩哥4分钟

OpenAI的o3推理模型成本从预估的3000美元飙升至3万美元,远超预期。尽管o3-high试图通过暴力试错生成大量文本解答问题,但被ARC-AGI系统排除在外,因为每个任务的成本高达3万美元。
上海AI Lab发布LLM高效Reasoning综述!全面总结如何“少想多做”
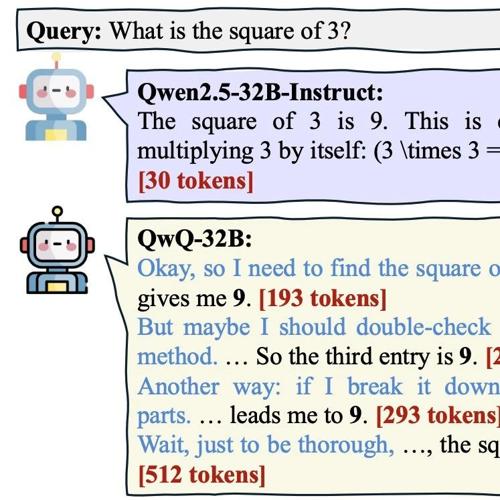
MLNLP社区致力于促进机器学习与自然语言处理领域的学术交流与进步。文章介绍了如何解决大型推理模型(LRMs)带来的冗余思考问题,包括字数预算、双系统切换、模型路由等方法,并探讨了未来高效推理的发展方向。
谷歌发布最强推理模型—Gemini 2.5 Pro
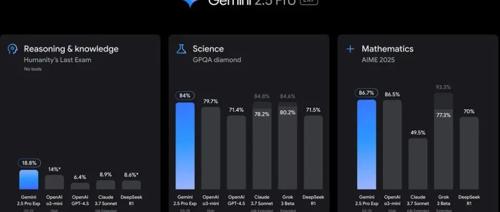
谷歌发布最强推理模型Gemini 2.5 Pro,在多个测试平台超过GPT-4等知名模型,编程能力显著提升,已面向高级用户提供并计划上线Vertex AI。