斯坦福打脸大模型数学水平:题干一改就集体降智,强如o1也失准,能力涌现怕不是检索题库

斯坦福大学研究表明,在更换数学题变量名称后,大模型的准确率直线下降。即使是表现最好的o1-preview模型,其准确率也从50%降至33.96%,表明它们可能更多依赖已存储的答案而非推理能力。团队提出Putnam-AXIOM。该基准解决了现有评估基准数据污染和饱和的问题,为自动化评估提供方法并生成变体数据集。
斯坦福大学研究表明,在更换数学题变量名称后,大模型的准确率直线下降。即使是表现最好的o1-preview模型,其准确率也从50%降至33.96%,表明它们可能更多依赖已存储的答案而非推理能力。团队提出Putnam-AXIOM。该基准解决了现有评估基准数据污染和饱和的问题,为自动化评估提供方法并生成变体数据集。

2025 年,AI 将获得“
永久记忆
”;
2028 年,美国将耗尽全部能源储备;
2030 年,

点击
上方
硬AI
关注我们
一文看懂2024年大模型的颠覆性突破!
硬·AI
作者
| 硬 AI
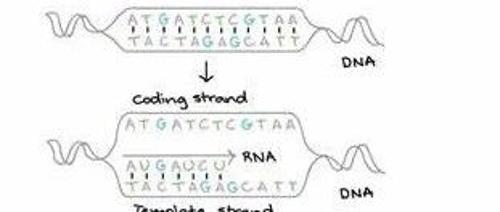
大模型的核心在于特征提取和重建。Transformer架构在NLP领域表现突出,而CNN则适用于图像处理。序列到序列(Seq2Seq)用于具有连续性内容的生成,如机器翻译、语音识别及视频处理等领域。CNN擅长处理不连续且独立的图像数据。

2024年人工智能领域取得了显著进展,OpenAI、Anthropic等巨头在大模型开发上持续领先。中国模型厂商如字节跳动、Deepseek等表现突出。LLM的推理能力提升、图像和视频生成技术突破以及机器人和自动驾驶领域的进展令人瞩目。总体来看,2024年是人工智能技术取得重大成就的一年,AI助手功能全面升级,AGI(通用人工智能)可能已在实现中。

木易总结2024年国内AI领域发展:360AI搜索获web端最佳流量奖、百度文库和Kimi分列app端前两名;阿里通义、DeepSeek、零一万物获奖模型;Kimi在UI设计上表现优秀;腾讯作为大厂默默无闻,百度和360因用户体验问题受挫。

雷军亲自挖人,小米计划招聘1200名AI人才进军大模型领域。罗福莉,北大硕士95后AI天才少女加入小米AI实验室,领导小米大模型团队,助力小米在大模型领域追赶竞争对手。