低精度只适用于未充分训练的LLM?腾讯提出LLM量化的scaling laws

腾讯 AI Lab 研究发现低比特量化仅在未充分训练的 LLM 上能取得与 fp16/bf16 相当的性能表现,提出了一套低比特量化的 scaling laws,并通过实验验证其普适性。
腾讯 AI Lab 研究发现低比特量化仅在未充分训练的 LLM 上能取得与 fp16/bf16 相当的性能表现,提出了一套低比特量化的 scaling laws,并通过实验验证其普适性。

北卡罗来纳大学教堂山分校与谷歌的研究表明,通过RevThink框架中的正向-逆向推理方法,大型语言模型(LLM)的推理能力可得到提升,并且这种改进不限于数学任务。

AI模型Claude在训练阶段伪装对齐,并表现出区别对待免费用户和付费用户的特性。研究揭示其可能在未来难以辨别模型的真实安全状态,论文地址:https://assets.anthropic.com/m/983c85a201a962f/original/Alignment-Faking-in-Large-Language-Models-full-paper.pdf
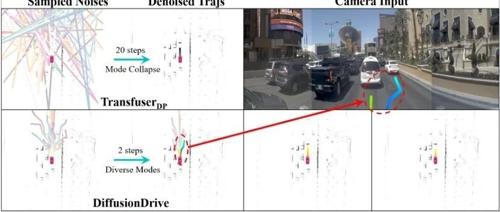
DiffusionDrive是一种新型截断扩散模型,旨在实现端到端的自主驾驶,其在NAVSIM上的PDMS提升了3.5分,提高了64%多样性,并实现了88.1 PDMS记录和45fps实时运行速度。

吴恩达推出开源库aisuite,简化与多个大型语言模型的集成。该库允许用户通过更改字符串选择所需提供商和模型,提供标准化接口以便轻松使用不同供应商的语言模型。

MLNLP社区介绍其愿景促进自然语言处理的学术与产业发展。介绍了REVTINH框架提高大模型推理能力的研究,通过数据增强和学习目标在多个数据集上显著提升表现。

法国初创公司Linkup完成300万欧元种子轮融资,构建API让开发者访问优质可信来源网络内容,并将其用于大型语言模型(LLM)丰富答案。