
日期: 2025 年 4 月 24 日

开源TTS领域迎来重磅新星!Dia-1.6B:超逼真对话生成,开源2天斩获6.5K Star!

由Nari Labs开发的Dia-1.6B因其逼真的对话生成能力而受到关注,仅开源两天便在GitHub收获了6.5K+Star。它支持多角色对话、拟人化表达、零样本声纹克隆等功能,并且运行效率高,音质媲美ElevenLabs和Sesame。
AI 阅读新姿势!支持MCP协议,打通微信读书与 Claude,让你的笔记活起来!

通过微信读书 MCP 服务器项目mcp-server-weread,用户可以实现与AI工具无缝集成,方便管理和分析阅读笔记。
解决Diffusion Transformers优化困境!南京大学与字节等提出DDT:解耦扩散模型

oder Transformer 能否加速收敛并增强样本质量?
>>
加入极市CV技术交流群,走在计
重磅!微软上线GPT-image-1模型,支持高级功能定制

OpenAI发布GPT-image-1模型,微软Azure云服务同步上线。该模型支持深度定制和全网爆火功能,提升图像生成效率和质量。适用于教育、出版和游戏等行业,确保内容合规性和伦理规范。
CVPR’25|CV 微调卷出天际,打破全参数微调性能枷锁!即插即用的提点神器Mona:我小,我强,我省资源

仅调整5%骨干网络参数,Mona方法在实例分割、目标检测等视觉任务中超越全量微调效果,显著降低适配和存储成本。
虚拟动点助力“利亚德集团2025年生态合作伙伴大会”圆满落幕

利亚德集团2025年生态合作伙伴大会在京成功举办,李军携核心管理层参会并分享显示、AI及文旅行业发展趋势。虚拟动点CEO刘耀东代表公司阐述了基于空间计算技术的AI研究成果与布局。
刚刚,OpenAI发布GPT-image-1模型,更强吉卜力版本来啦

今天凌晨,1点30分,OpenAI发布了全新图像模型GPT-image-1,并已向全球开发者开放使用。该模型可通过API控制生成图像的多个参数,支持全网爆火的吉卜力模式等特性。目前已有Adobe、Figma、HeyGen、Wix等知名企业集成此模型。
医学顶刊TMI 2025|Zig-RiR:高效医学图像分割的Zigzag RWKV-in-RWKV
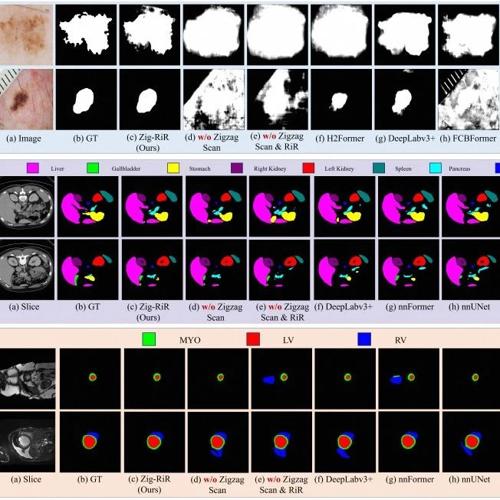
本文介绍了一种名为Zig-RiR的新型医学图像分割模型,通过创新的嵌套结构和锯齿状扫描机制实现了对二维和三维医疗图像的高效精准分割,显著提升了计算效率并降低了GPU内存使用。