
DPO-Shift:一个参数可控改变DPO分布,缓解似然偏移

在人工智能领域,直接偏好优化(DPO)方法因其简单易用和稳定性而受到广泛关注,但其训练过程中会出现似然位移现象。本文提出DPO-Shift方法,在Bradley-Terry模型中增设参数函数以缓解该问题,并通过理论分析与实验验证了其有效性。
在人工智能领域,直接偏好优化(DPO)方法因其简单易用和稳定性而受到广泛关注,但其训练过程中会出现似然位移现象。本文提出DPO-Shift方法,在Bradley-Terry模型中增设参数函数以缓解该问题,并通过理论分析与实验验证了其有效性。

视觉强化微调项目 Visual-RFT 通过规则奖励和强化学习方法,实现了视觉语言模型在目标检测、分类等任务中的高效提升。项目已开源,欢迎加入。
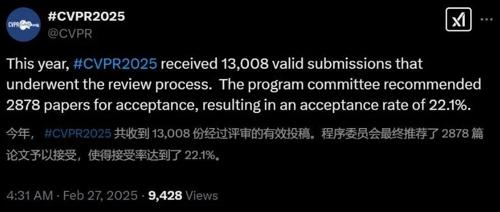
CVPR 2025录用结果出炉!今年共13008篇论文投稿,最终录取率仅为22.1%。大模型时代的研究方向集中在端到端、闭环仿真3DGS、多模态大模型和扩散模型等前沿领域。科研辅导服务帮助学生解决选题、实验设计、创新点设计等问题。

MIT教授Markus J. Buehler团队提出的新自学习AI框架PRefLexOR能够像人类一样进行深度思考和自主进化。它通过迭代的推理改进自我学习,具有记忆、微生物修复和自进化系统等特性。

摩根大通指出,英伟达、Marvell和亚马逊等客户下调了2025年CoWoS订单预期,主要是因为此前的预期过于乐观。尽管如此,台积电在2025年的CoWoS产能仍将供不应求,英伟达的Blackwell芯片出货量有望达到600万片。




