
分享

AI 性格失控等诡异现象,终于有了科学解释

Anthropic新研究揭示了控制语言模型性格特征的神经活动模式,通过生成人格向量解释了AI的恶意、谄媚和幻觉现象,提出了预防性引导来防止模型获得负面性格,并展示了监控功能、数据筛查以及疫苗式防护机制的应用前景。
扣子要做 Agent 时代的 Infra,附开源版搭建全流程

扣子 Coze Studio 开源三天收获13K+ Star,火山引擎 ECS一键部署助力快速上手。扣子开源旨在支持开发者共建生态、确保安全可靠,并通过全球反馈提升产品。


设计师听不懂我说话的难题,lovart用一张能聊天的画布解决了

通过ChatCanvas功能,设计师可以直接在画布上修改设计元素。它支持多轮对话、批量修改和风格变体等功能,大幅提升了设计效率和灵活性。

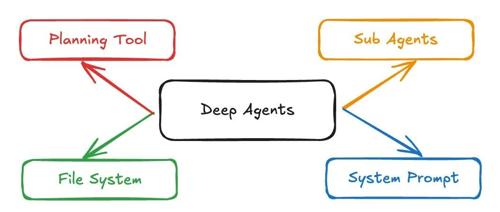
最强MCP开源:Windows-MCP

Windows MCP 是一个开源项目,能够实现AI Agents与Windows操作系统的无缝集成,支持Windows 7至11操作系统,具备轻量级、可定制和开源特点。它提供丰富的用户界面自动化工具,允许大语言模型执行任务如文件导航、应用程序控制等。
北航LiveRepoReflection: 扭转乾坤-仓库级代码反射
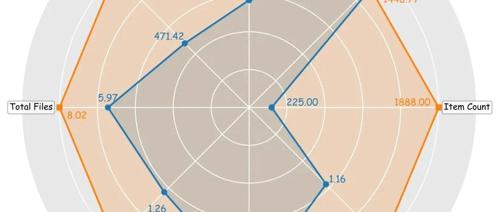
本文提出了一种新的代码仓库反思基准LiveRepoReflection,用于评估多文件仓库上下文中的代码理解和生成能力,该基准包含6种编程语言的1,888个测试案例,并通过严格的筛选流程确保其质量与难度。