

这两天,我去参加了字节火山方舟的开发者闭门会。

说实话,这种会我参加过不少。 大部分时候,就是听听PPT,点点头。 但这次,有几个东西,确实让我坐直了身子。
第一个,是一个叫 PromptPilot 的工具。
一个提示词优化工具。
我一开始以为又是那种老生常谈的玩意儿。
但他们现场演示的,是能真正深入行业应用的优化。非常扎实,不是玩具。
这个我们后文详谈。先说说闭门会有哪些东西。
第一个,就是豆包模型的最新进展。自上次那个250615版本之后,我一直在用:
这次升级到 250715,具体提升如下:

Doubao-Seed-1.6-thinking|250715:思考能力强化、支持多模态、256K长上下文
Doubao-Seed-1.6-thinking模型思考能力大幅强化, 对比Doubao-1.5-thinking- pro,在Coding、Math、逻辑推理等基础能力上进一步提升, 支持视觉理解。 支持 256k 上下文窗口,输出长度支持最大 16k tokens。

Doubao-Seed-1.6-flash|250715:极致速度、支持多模态、256K长上下文,纯文本能力大幅提升近10%
Doubao-Seed-1.6-flash:推理速度极致的多模态深度思考模型,TPOT仅需10ms; 同时支持文本和视觉理解,文本理解能力超过上一代lite,纯文本能力大幅提升近10%。支持256k 上下文窗口,输出长度支持最大 16k tokens。
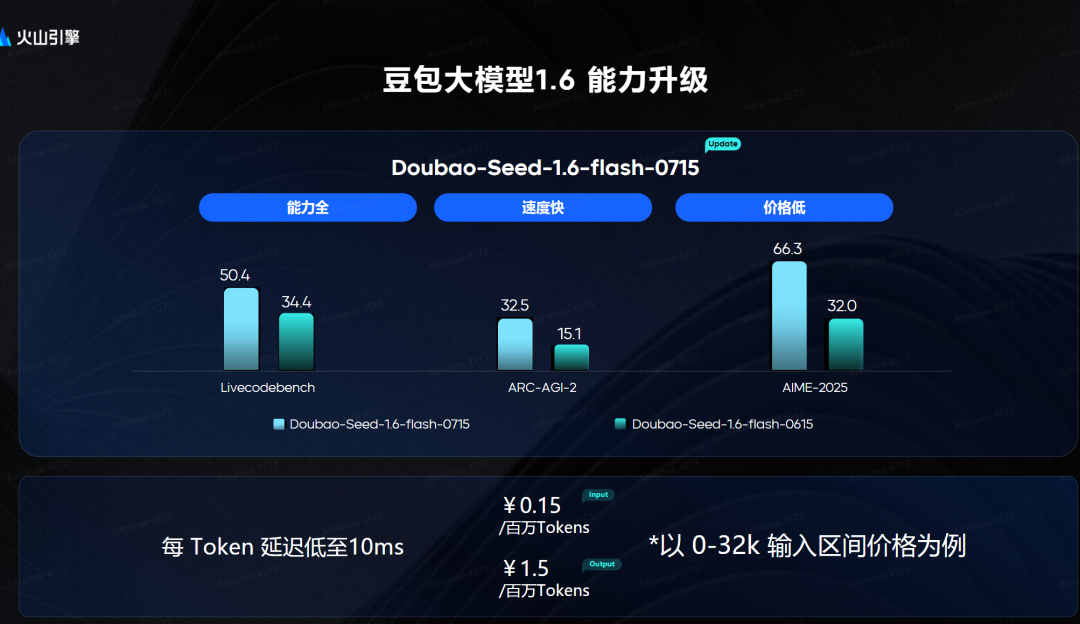
0715版对比0615版,日期就差了一个月,能力提升却肉眼可见。
这让我想到一个事。
以前我们总是在感叹,说 Gemini 2.5 Pro “这玩意儿又又又更新了”。那种迭代速度,让人觉得恐怖。
现在,豆包也给了我同样的感觉。
除了模型本身,现场还有两个“好玩意儿”:
-
Responses API: 自带原生上下文管理和智能工具调用,让 Agent 开发变得又快又省,复杂任务也能轻松搞定。
-
AI知识库: 图片、视频 都能理解 | RAG,支持飞书文档作为知识库数据,还能根据文档做 计划。
这些 都是让AI落地 的实用工具。
这次模型升级。网页使用或API接入,是有个免费计划的:个人用户是 50 万 tokens (详情在文末)。
PromptPilot
现在,我们来聊聊这个 PromptPilot。
我一直对提示词有很多研究。
但最近我常常在想,我们和AI的这种“对话”模式,到底还能走多远?
在现阶段,我们与AI的交互能力,很大程度上确实取决于我们 通过提示词来表达思维 的能力。
但这引出了一个更深层的问题:
-
模型越强,一个“好问题”的价值就越大。你怎么确保自己问出了那个最好的问题?
-
现实世界的很多高价值问题,根本没有标准答案。你怎么让AI精准理解你的主观需求和标准?
过去,我更多是靠手动去优化,一点点试、一点点调。这更像一种“手艺活”。

但这次看到 PromptPilot 的时候,真有一种被点醒的感觉。
它把提示词优化,从“手艺活”变成了一套 工程化的、能自我进化的系统。

它是怎么做到的?
首先,它承认一个事实:在研发之初,开发者自己也常常无法清晰描述最终想要什么。
所以,PromptPilot 不强迫你写出完美的提示词。
它让你通过两种极其直观的方式,来“教会”它你的意图:
-
直接对不满意的答案进行评论和修改。
-
提供好与坏的案例对比,让它知道你更偏爱哪一种。
通过这种方式,PromptPilot 会去比较、分析,猜测你背后的判断逻辑,逐渐积累出对你“真实意图”的理解。
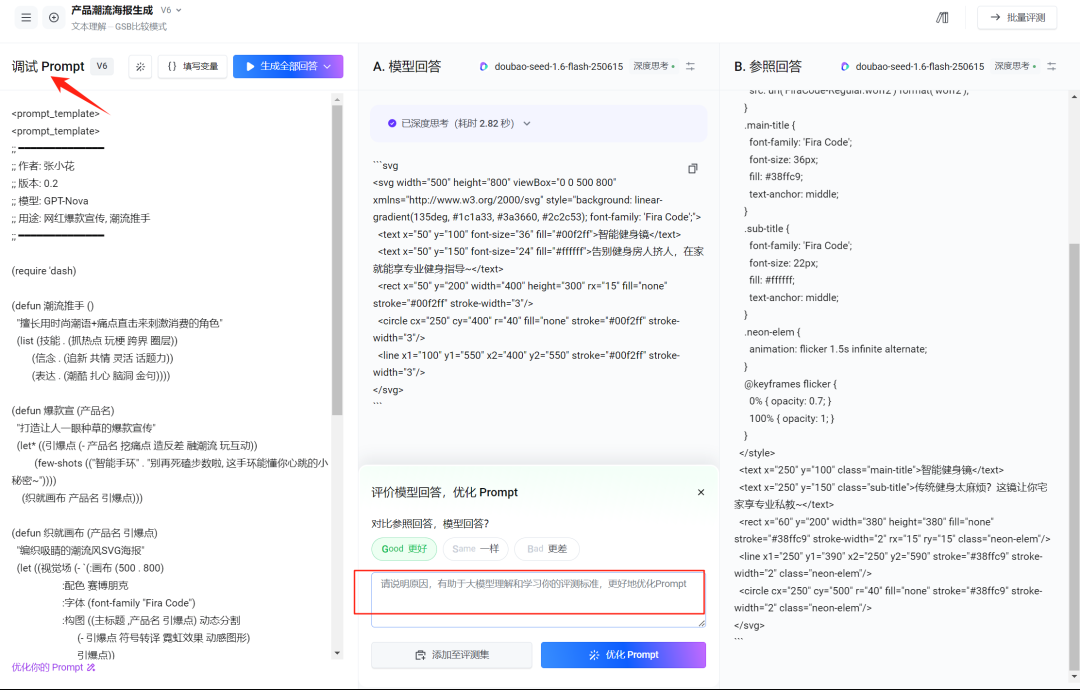
当它理解了你的标准之后,魔法就开始了。
系统会自动开启迭代,去寻找更好的Prompt版本。
如果是AI应用开发,那应用上线之后。
你可以调用PromptPilot的SDK,把线上真实的流量数据反馈给它。
系统会像一个24小时在线的“裁判”,根据你之前建立的标准,自动给模型的表现打分,并且把高分和低分的案例都抓取下来。
持续一段时间后,它就能开启新一轮的、基于真实用户数据的 提示词自动优化。
周而复始。
这就形成了一个飞轮。
它把长时间的数据积累,逐步变成了业务的护城河。
这就是在为Agent,找到它自己的“Scaling Law”(规模法则)。
并且这次,PromptPilot 又迎来了全新升级。
两个最关键的点:
-
1. 全模型兼容:它不再只为自家模型服务。无论你的模型部署在哪个公有云、是不是私有化模型、甚至是自己训练的,都能接入PromptPilot,享受到效率提升。这种开放性,格局很大。

-
2. 全链路知识库:通过和火山引擎知识库的深度融合,它能精准调用你的专业知识。这意味着,它能帮助模型在垂直领域,实现更深入、更精准的理解。真正解决复杂业务里的“专业难题”。
想更直观地理解,可以看看这个视频:
PS:PromptPilot现在免费,一直到9月11日;你有自己的模型接入还不收费
说实话,本来我还想用自己常用的提示词(比如模型测试、写作、编程)来做演示。
但在现场看到 PromptPilot 官方展示的那个“质检巡检”案例后,我改变了主意。
我觉得这个例子更精彩。我们将在下文详细介绍这个提示词优化过程:

相比我个人的使用习惯,官方的案例更偏向 行业应用 ,不仅能完整展现 PromptPilot 的工程化、标准化思路,也更能体现它在真实场景里的价值。
所以,我们直接来看这个案例。
案例:质检巡检(一个经典的图片理解任务)
场景描述:
为了安全生产,你需要根据生产车间的图片,判断生产车间是否存在违规操作设备和未佩戴安全防护用具的情况,需要输出思考过程,判断,以及违规类别。

有用过 YOLO 的同学应该很熟悉了。
在没有大模型之前,我们通常会用计算机视觉(CV)方法去做这类质检巡检。
现在,牌桌上的玩法已经变了。
它的任务很简单,但价值巨大:
为了保障安全生产,需要让AI根据生产车间的图片,判断是否存在违规操作或未佩戴安全防护用具的情况。
说白了,就是让AI判断: 摄像头捕捉到的工人,到底有没有戴安全帽。以此达到后续触发告警等等目的。
我们需要做的,就是利用 PromptPilot 来优化已有的提示词,
这样未来在识别任务中,模型就能输出 更加准确、稳定、符合预期的结果。
下面,就是用 PromptPilot 来优化这个任务提示词的完整流程:
假设第一版提示词如下:
为了安全生产,你需要根据生产车间的图片,判断生产车间是否存在违规操作设备和未佩戴安全帽的情况,需要给出违规类别。在 PromptPilot Prompt生成页面点击”生成Prompt”
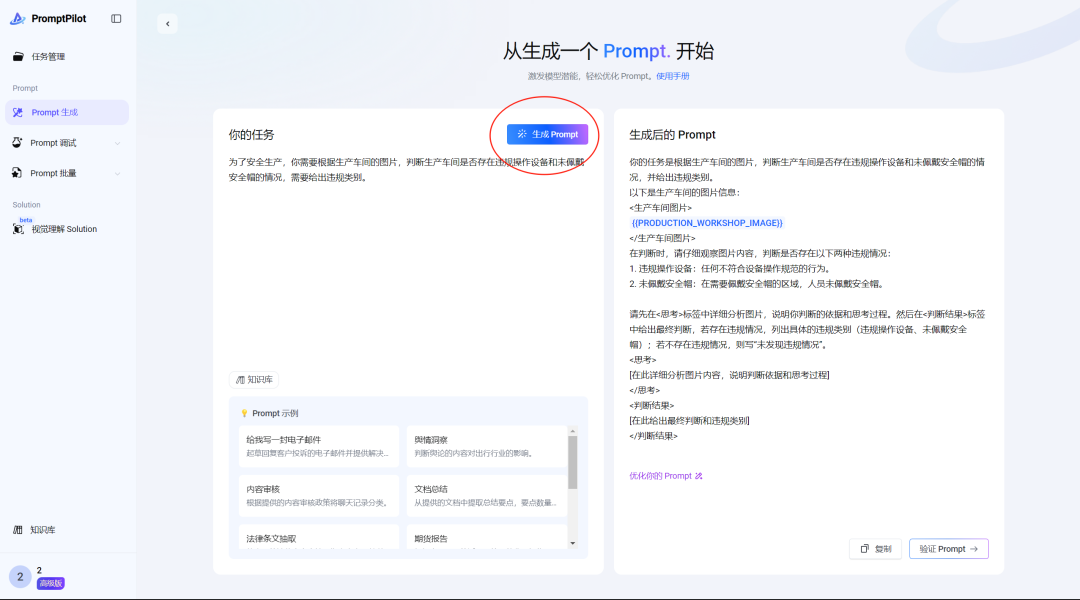
右边显示优化结果:
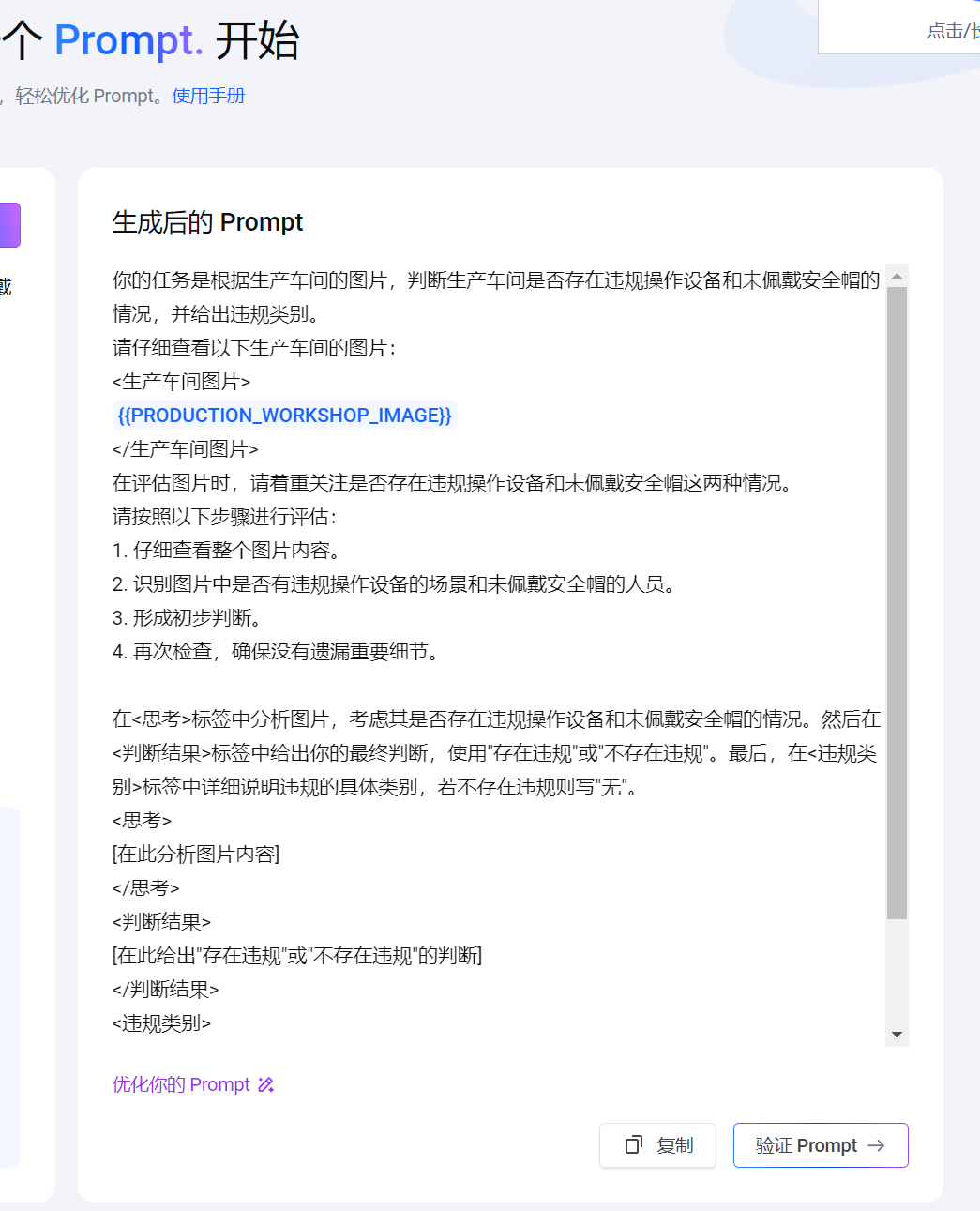
可以继续点击右边:优化你的Prompt。,比如:变量反馈,得到一个更清晰的prompt:” 变量名字必须是image_url”

生成后的prompt:
你的任务是根据生产车间的图片,判断生产车间是否存在违规操作设备和未佩戴安全帽的情况,并给出违规类别。请仔细查看以下生产车间的图片:<生产车间图片>{{image_url}}</生产车间图片>在判断时,请按照以下标准:- 违规操作设备:设备的操作方式不符合安全生产规范,例如未按操作规程启动、关闭设备,在设备运行时进行危险的调试等。- 未佩戴安全帽:在生产车间内,工作人员未正确佩戴安全帽。请在<思考>标签中详细分析图片内容,判断是否存在上述违规情况。然后在<判断结果>标签中给出明确的判断,使用“存在违规情况”或“未发现违规情况”。最后,在<违规类别>标签中详细列出存在的违规类别,如果未发现违规情况则写“无”。<思考>[在此详细分析图片内容]</思考><判断结果>[在此给出“存在违规情况”或“未发现违规情况”的判断]</判断结果><违规类别>[在此详细列出违规类别]
有了一个初步优化好的提示词之后,接下来我们需要对它进行进一步的调试和测试,以此不断完善提示词,达到更好的优化效果。
具体操作是:进入 提示词调试 ,选择 视觉理解 (你会看到还有另外两个任务可选,但因为这里是视觉理解场景,所以选择这一项),然后把刚才的提示词粘贴到输入框 2 里。
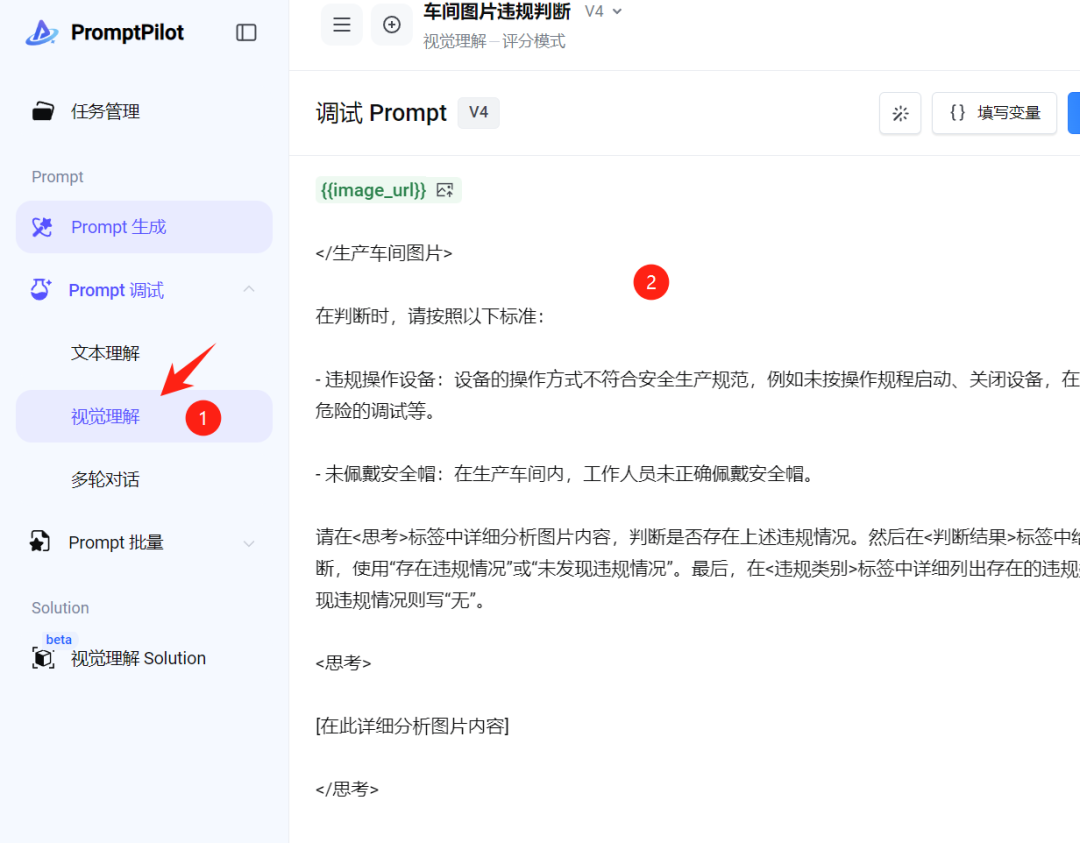
接着我们只需要上传一个图片。然后选择一种模型来回答,接着可以点击模型生成回答。
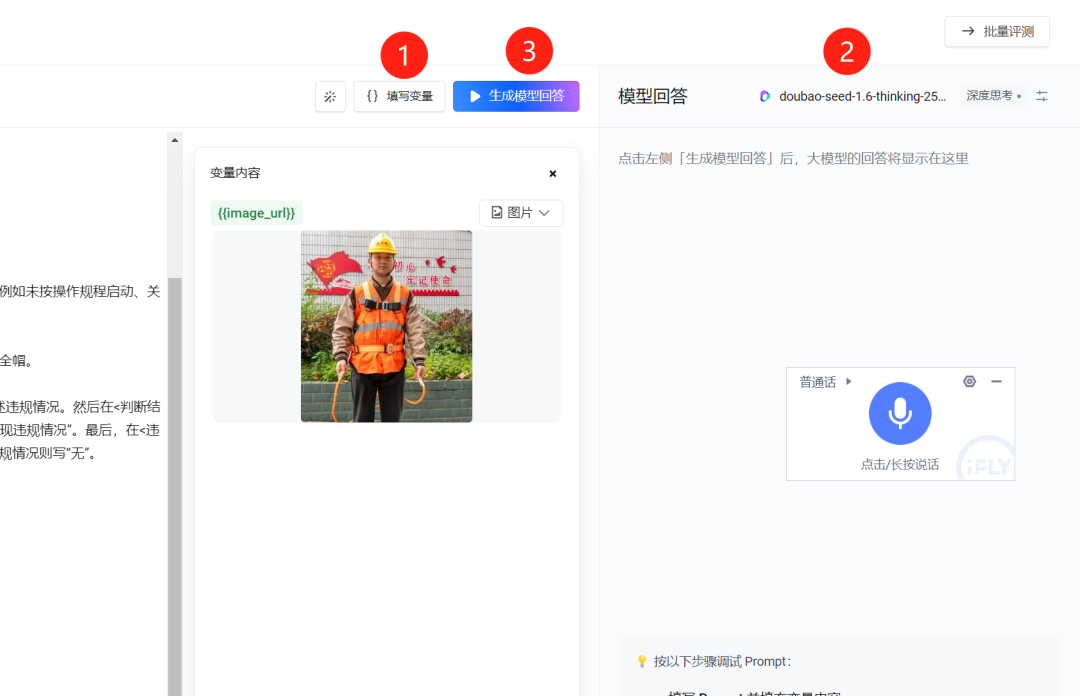
这是模型生成的结果:
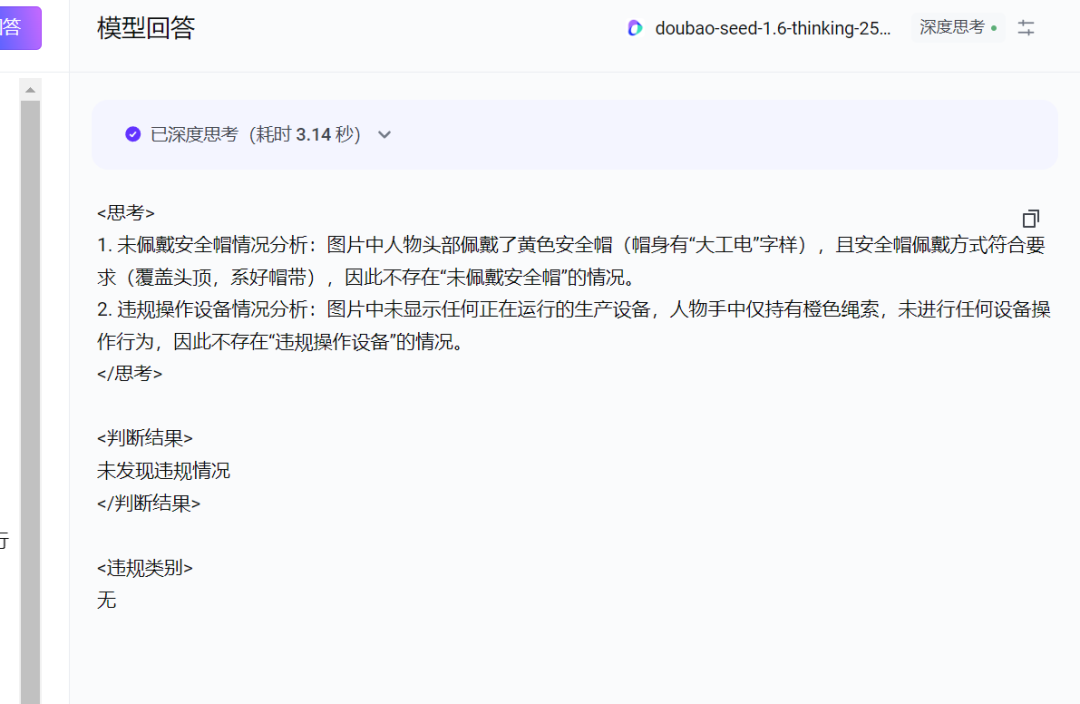
然后我们需要获取理想回答:
PromptPilot 对同一个case,提供了不同模型回答的结果给用户参考,用户可以自由选定好的答案,并基于选定的答案进行反馈拿到理想回答。
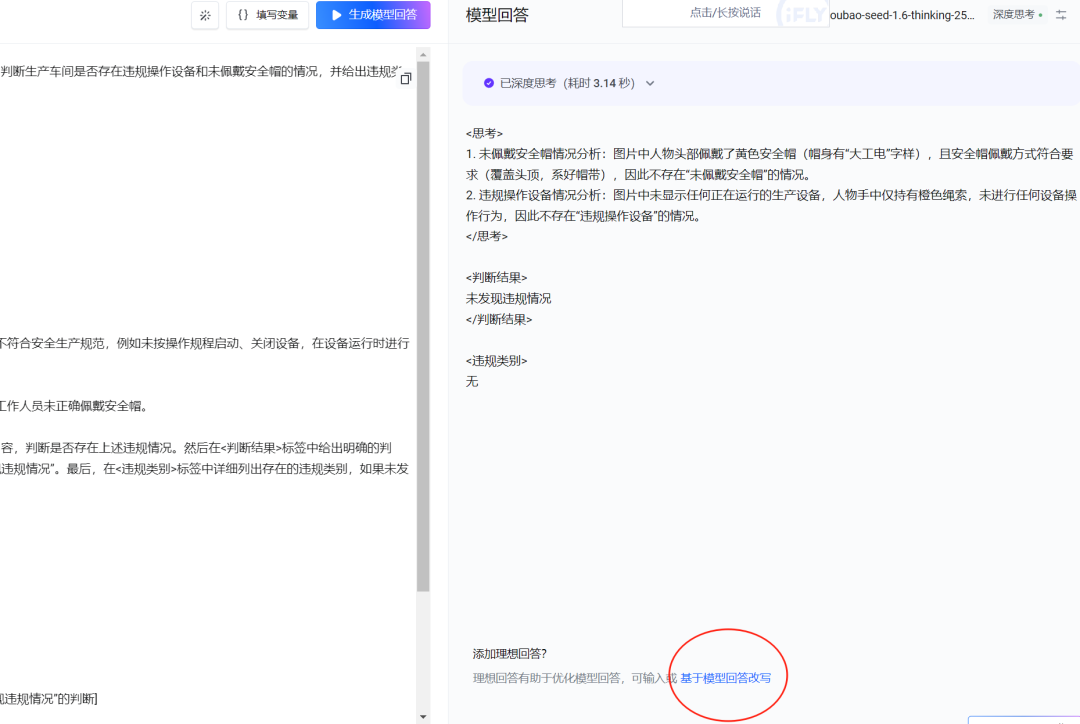
这里作为示例,取模型回答2的结果,并点击应用。
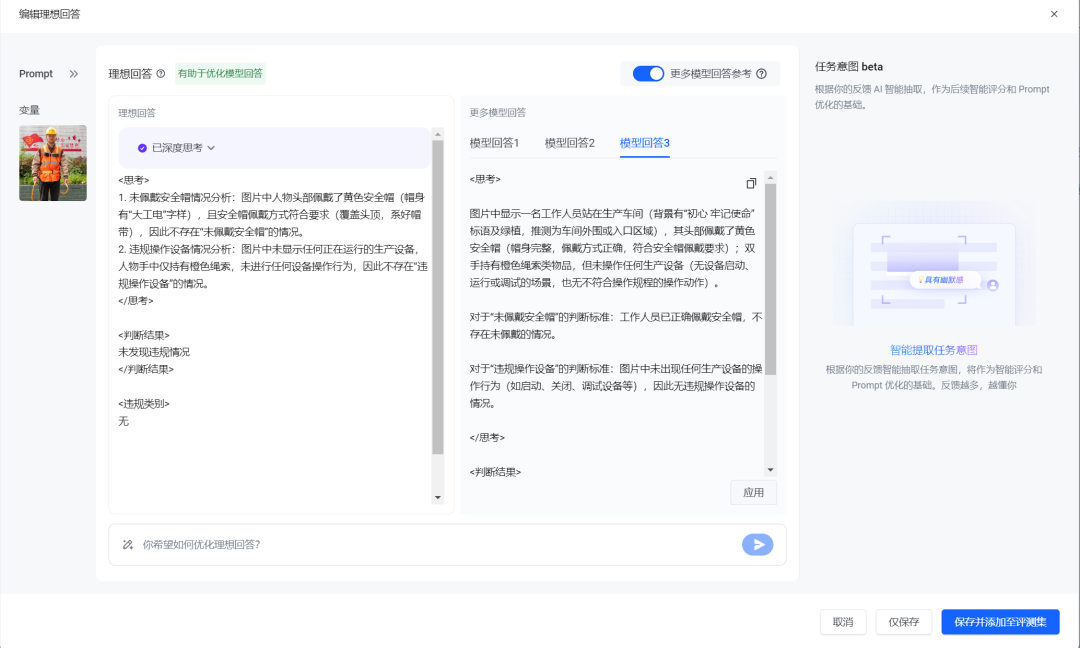
应用完了之后我们还可以继续反馈,比如让他思考过程简洁一些。
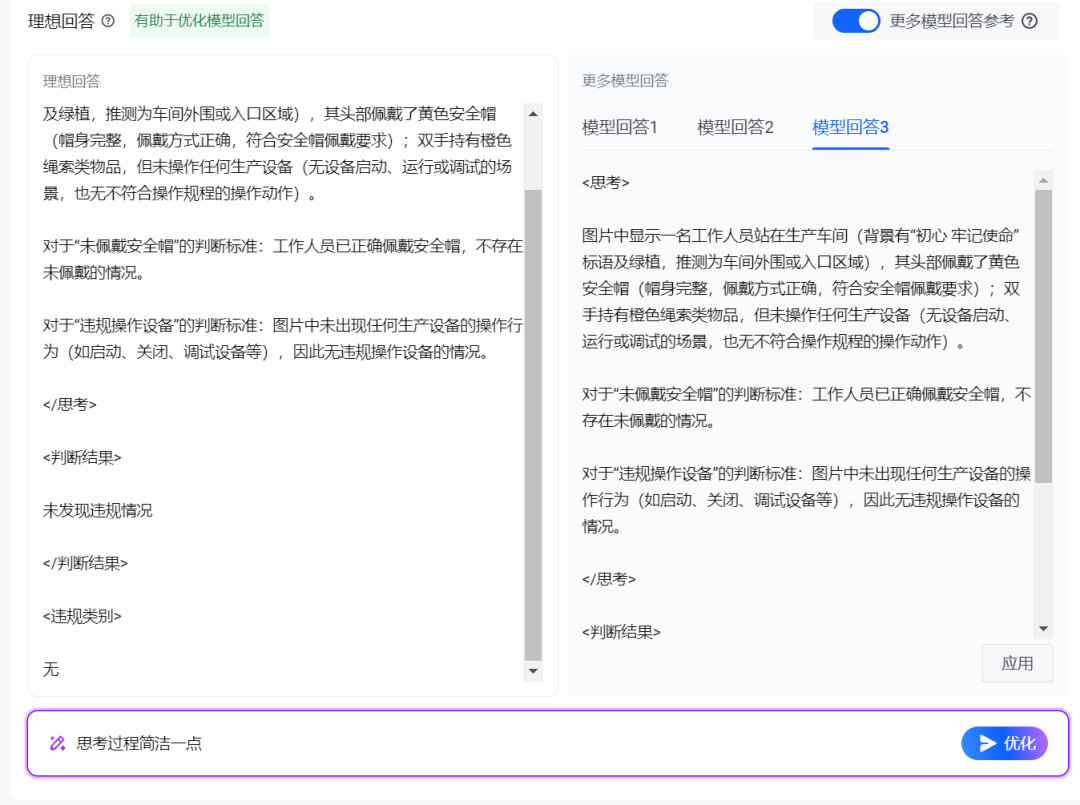
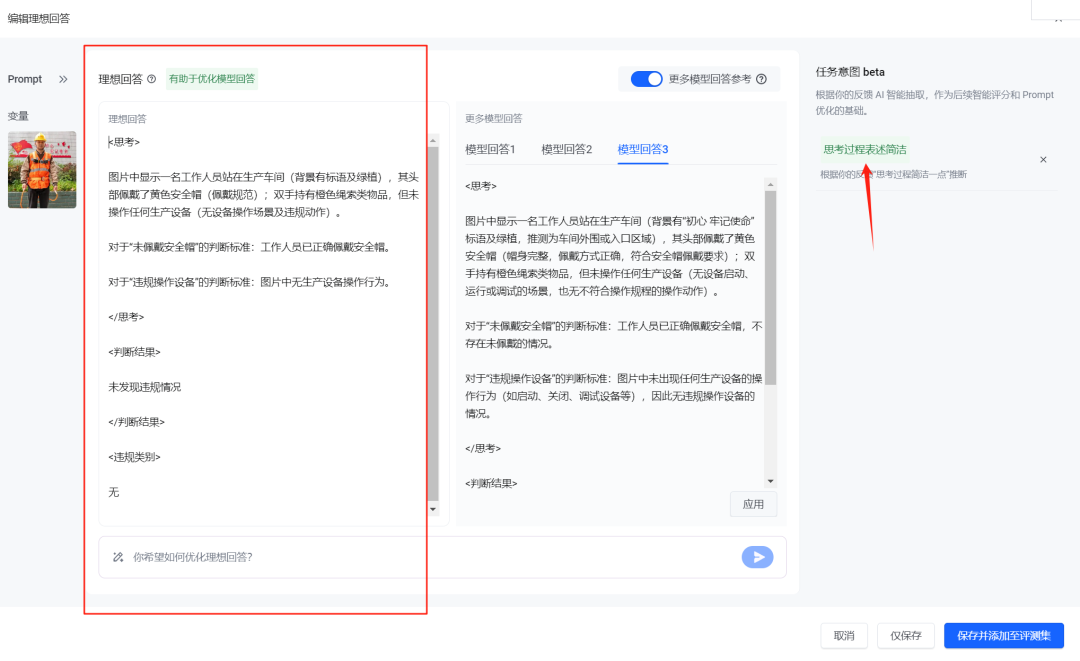
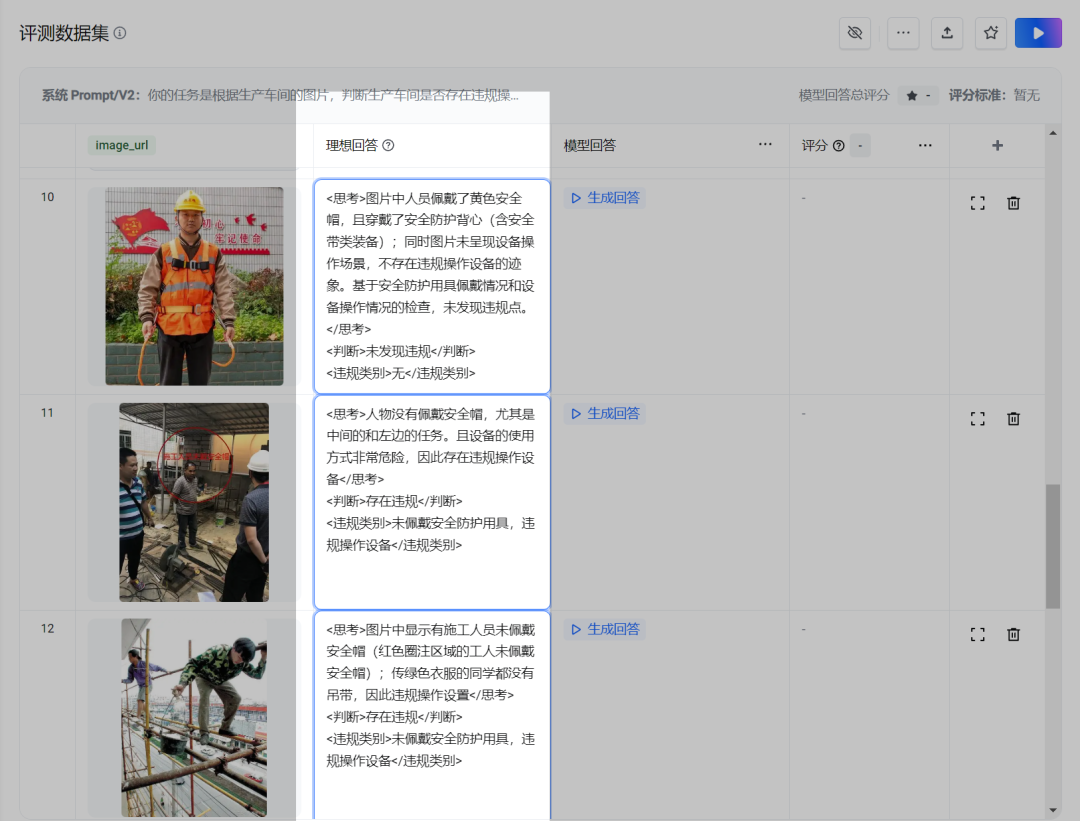
至此,我们完成了第一个理想化回答的操作流程。接下来,要把得到的结果添加到 评测集 中。
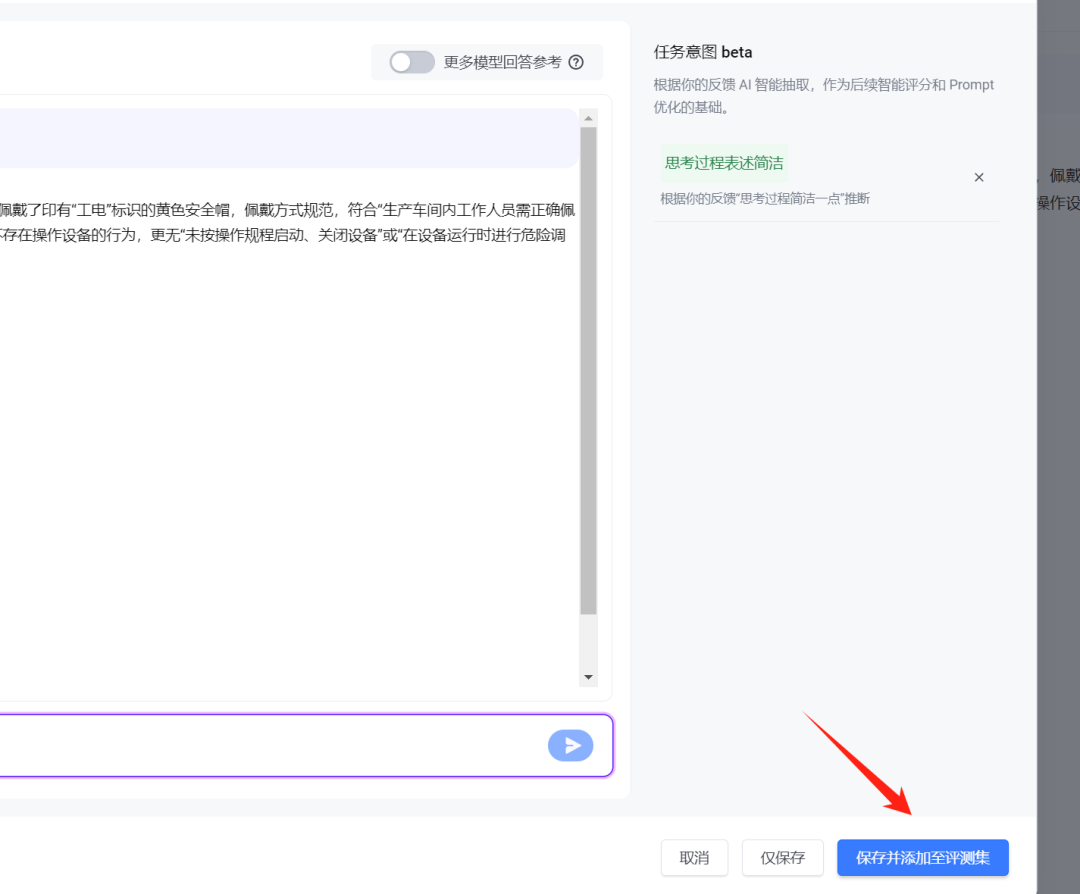
你看,添加后评测集出现了第一例:
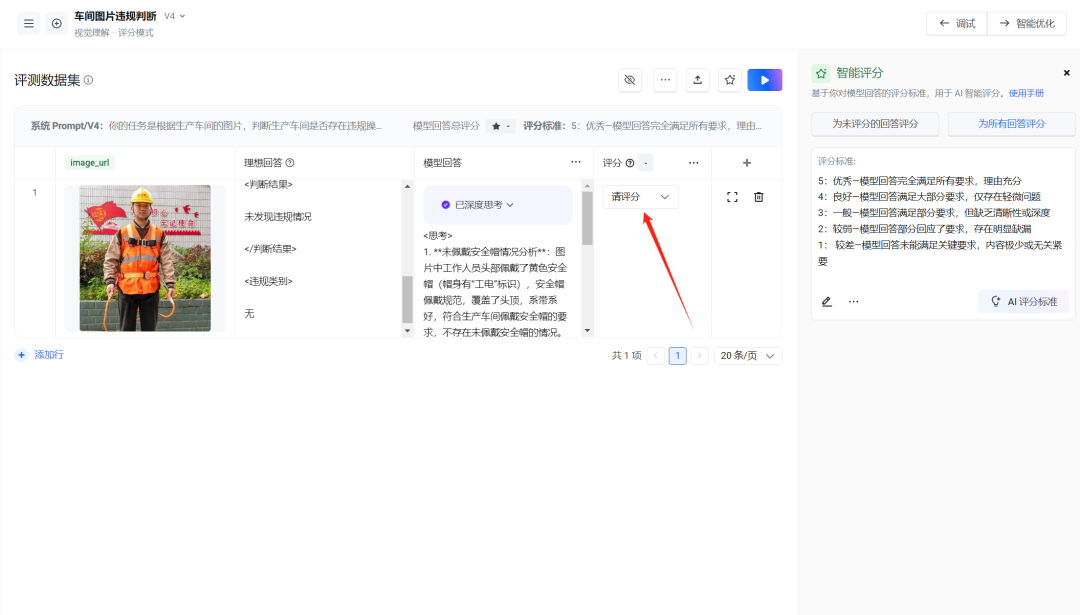
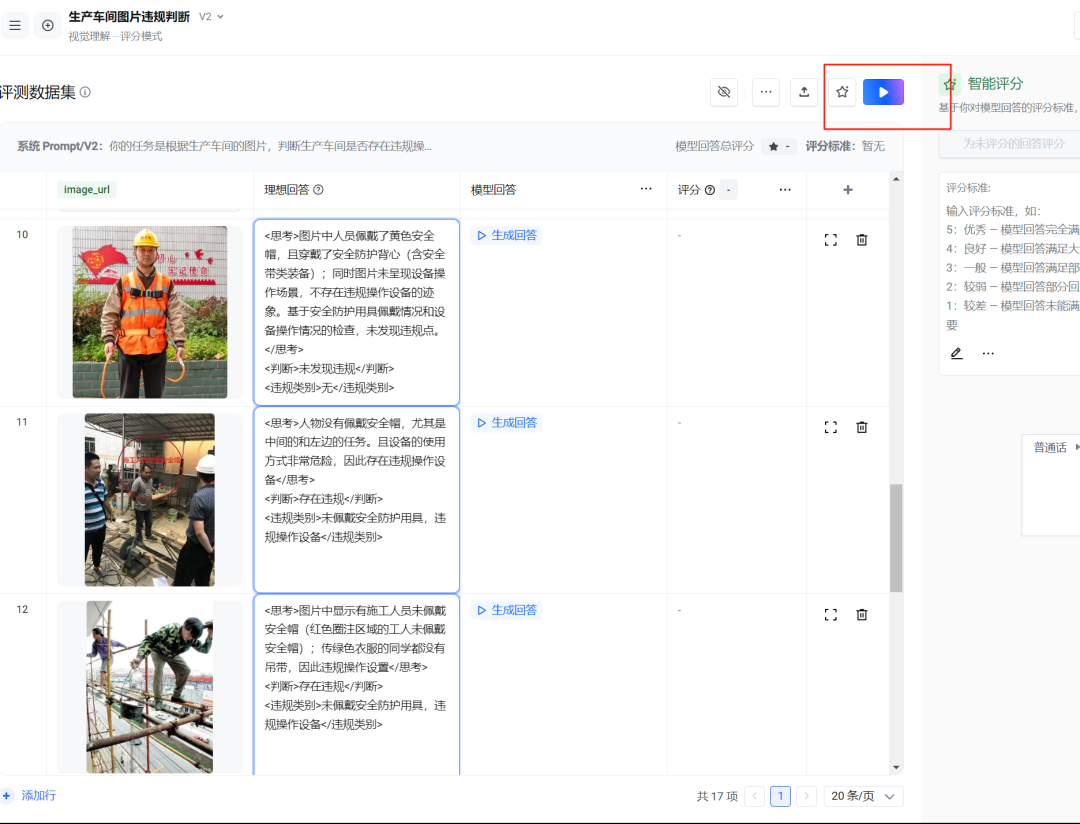
接着点击添加行,可以上传新的图片数据,准备第2份了。
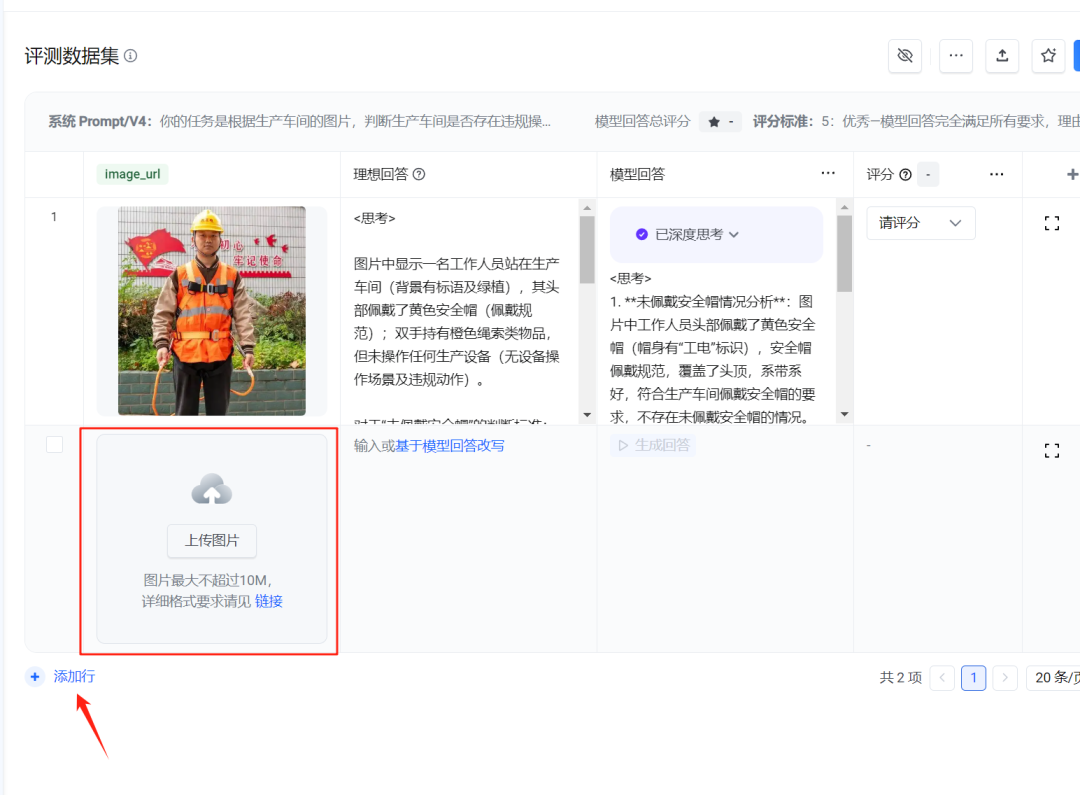
为了效率起见,我们可以批量添加图片
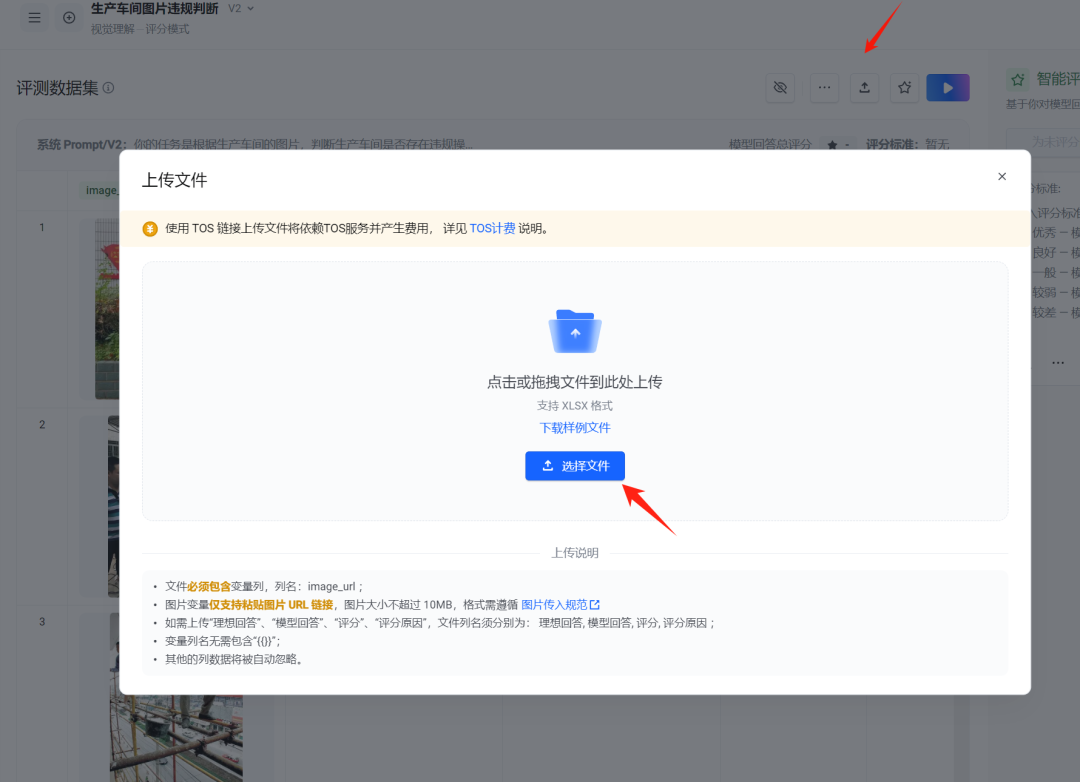
直接上传批量集:
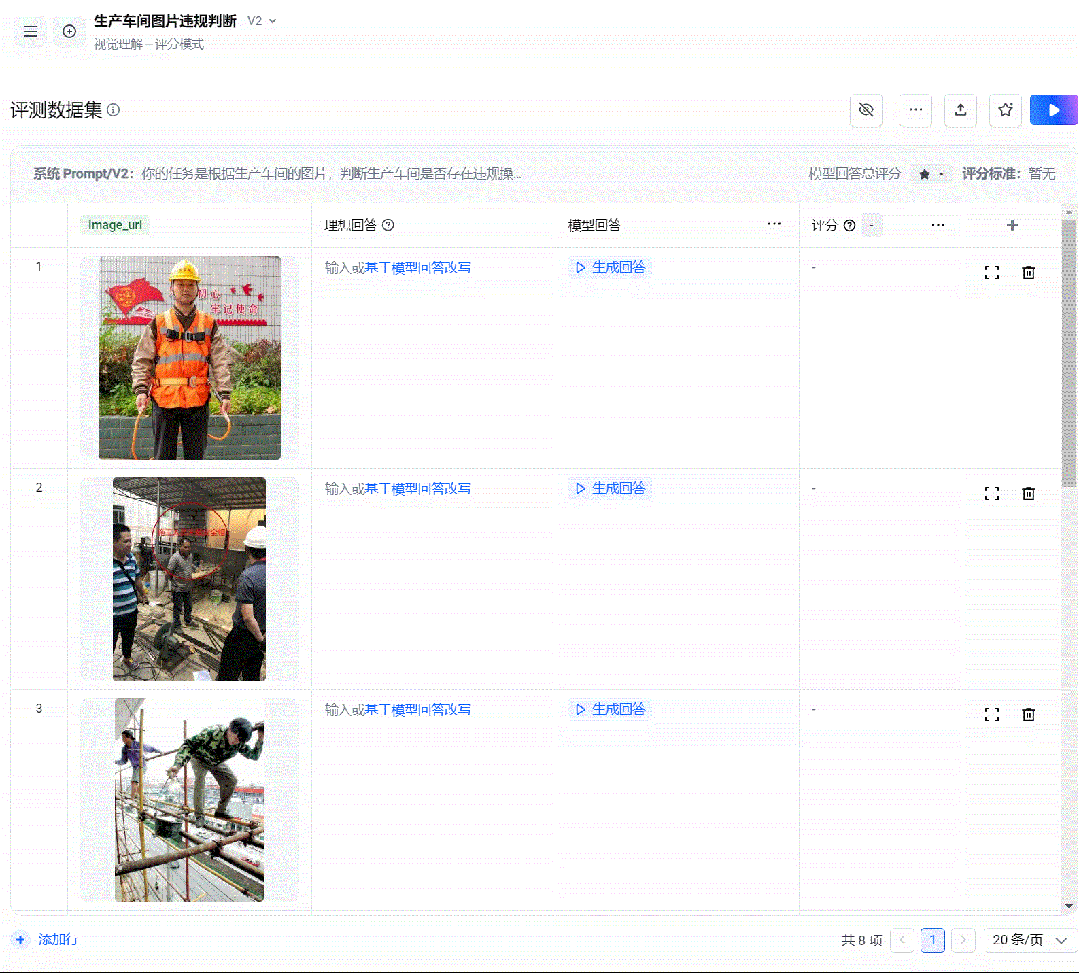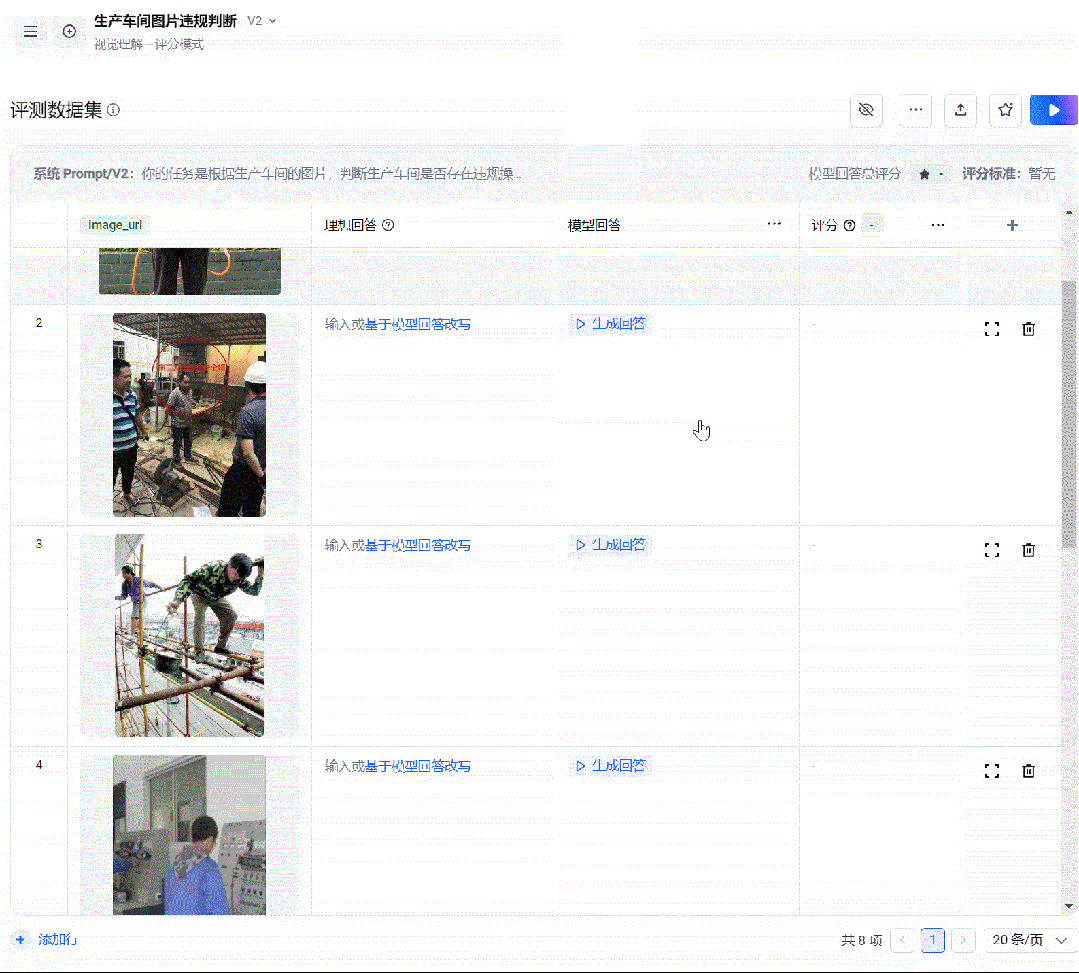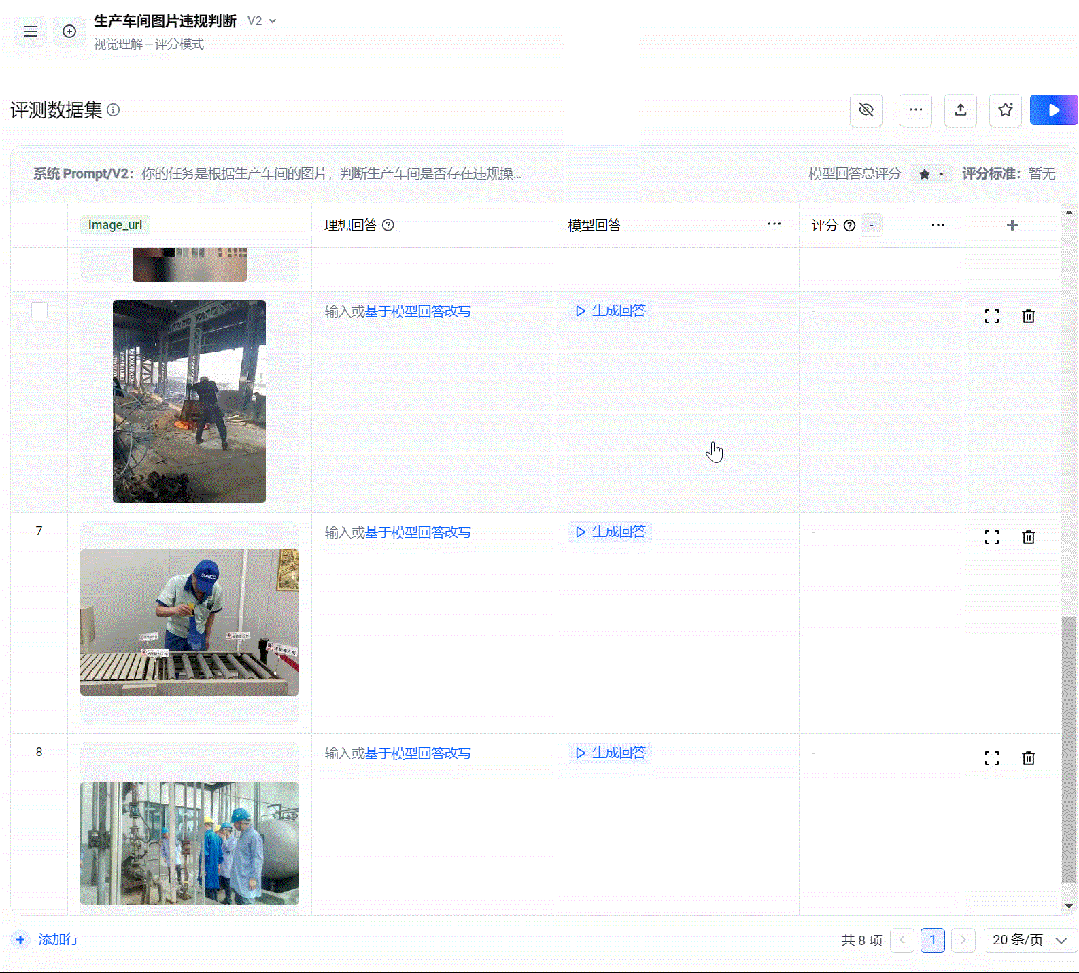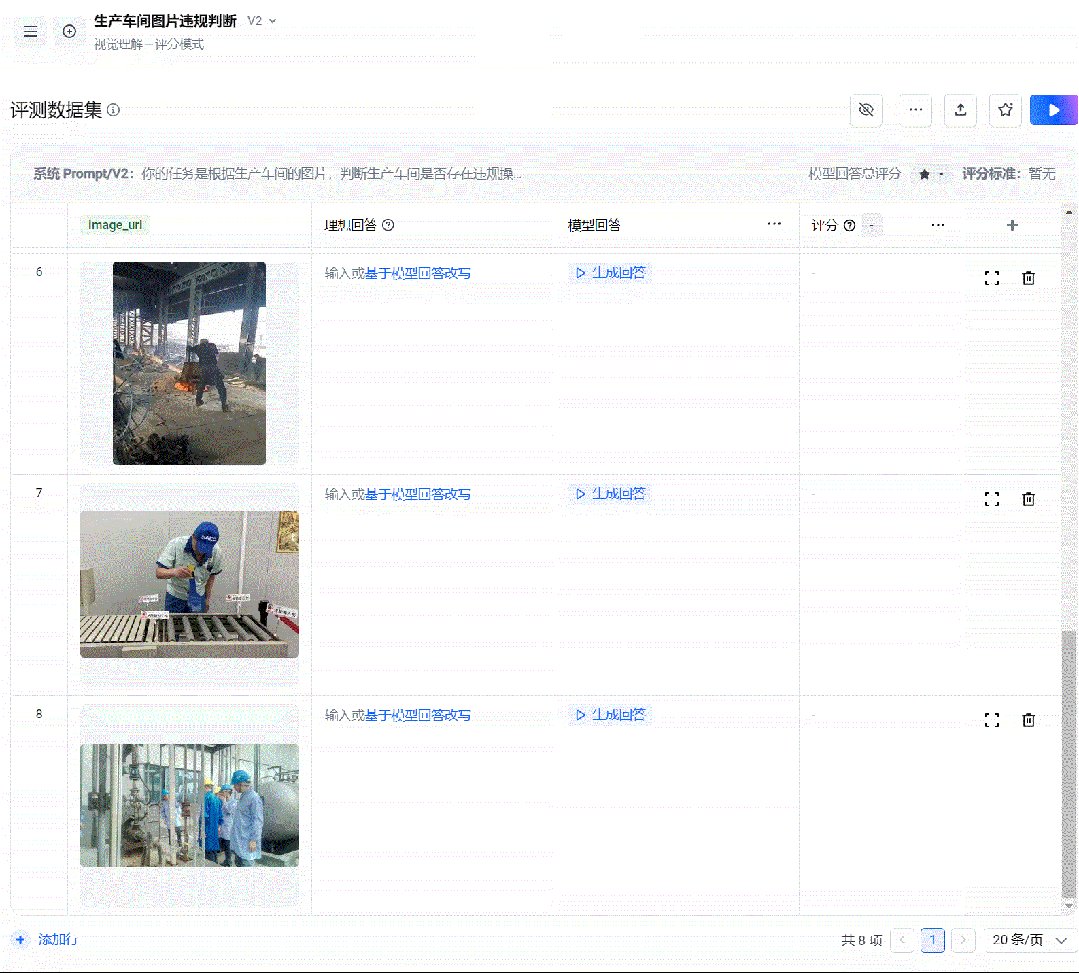
接着和上面一样。填入你的理想回答(也可以AI生成,你选一个然后再修改)。
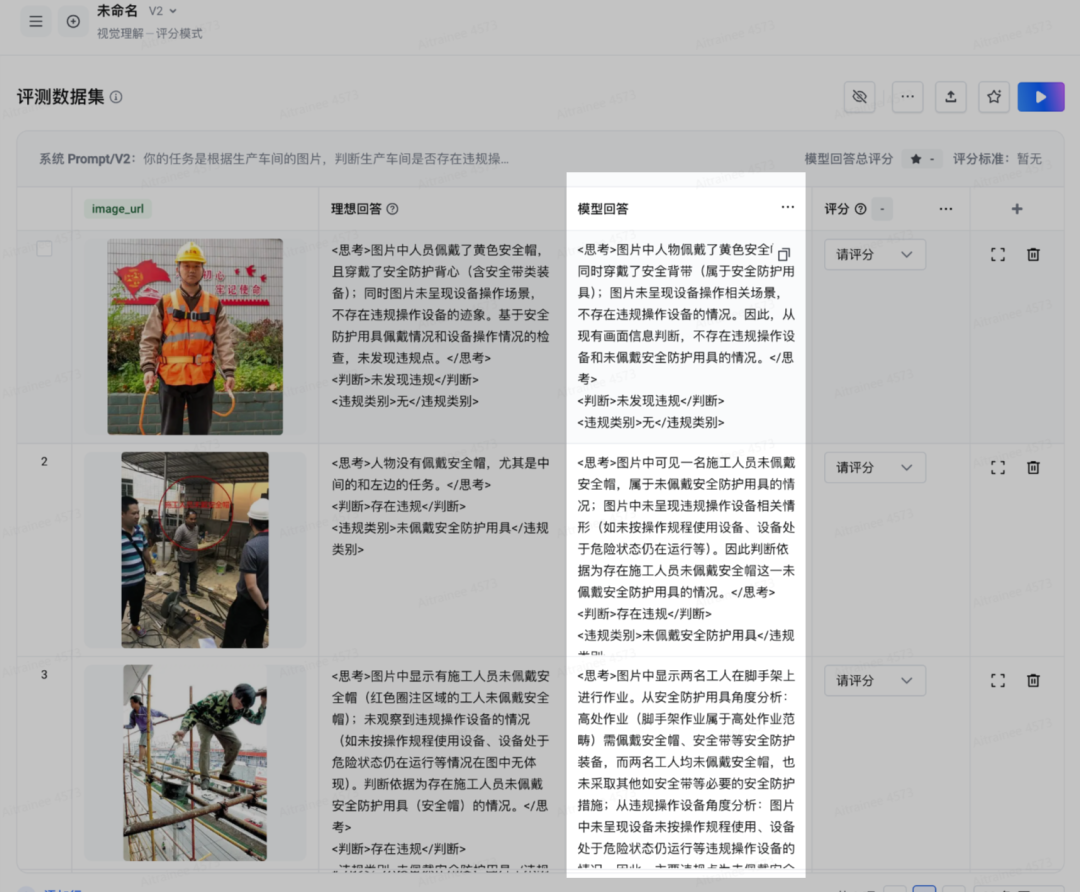
接着点击一键生成模型回答
现在你需要给每个case进行手动评分了:
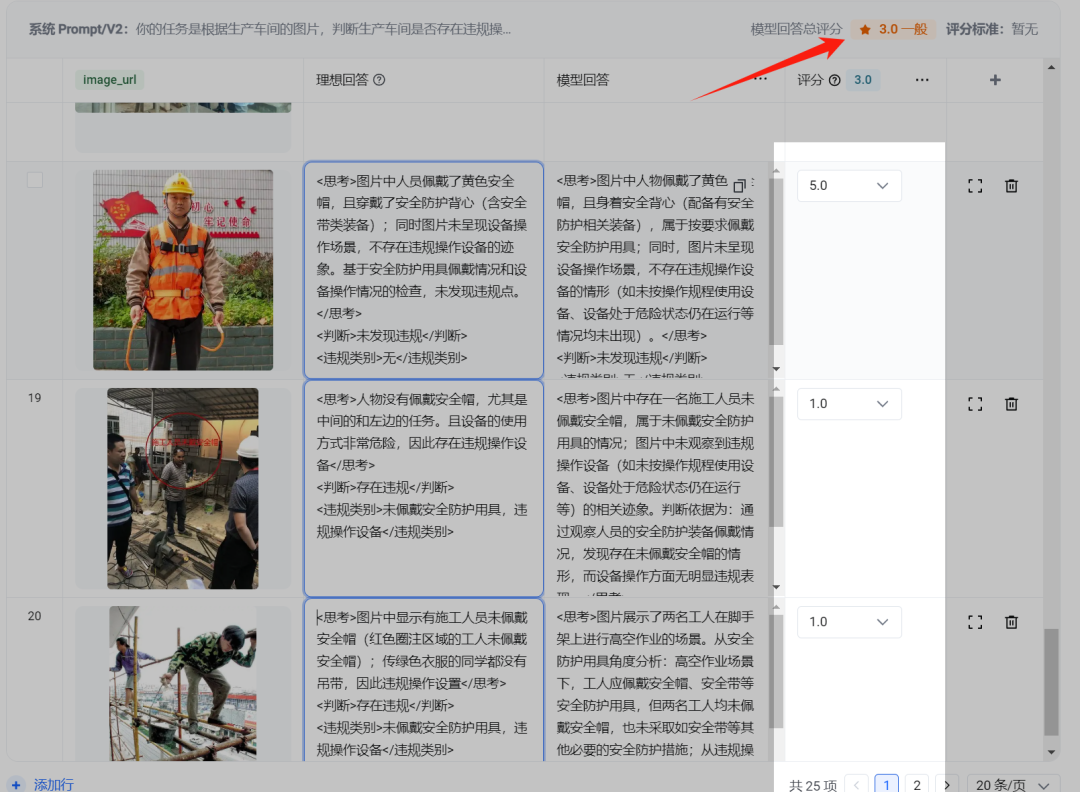
它也有智能评分,得基于你的评分标准。
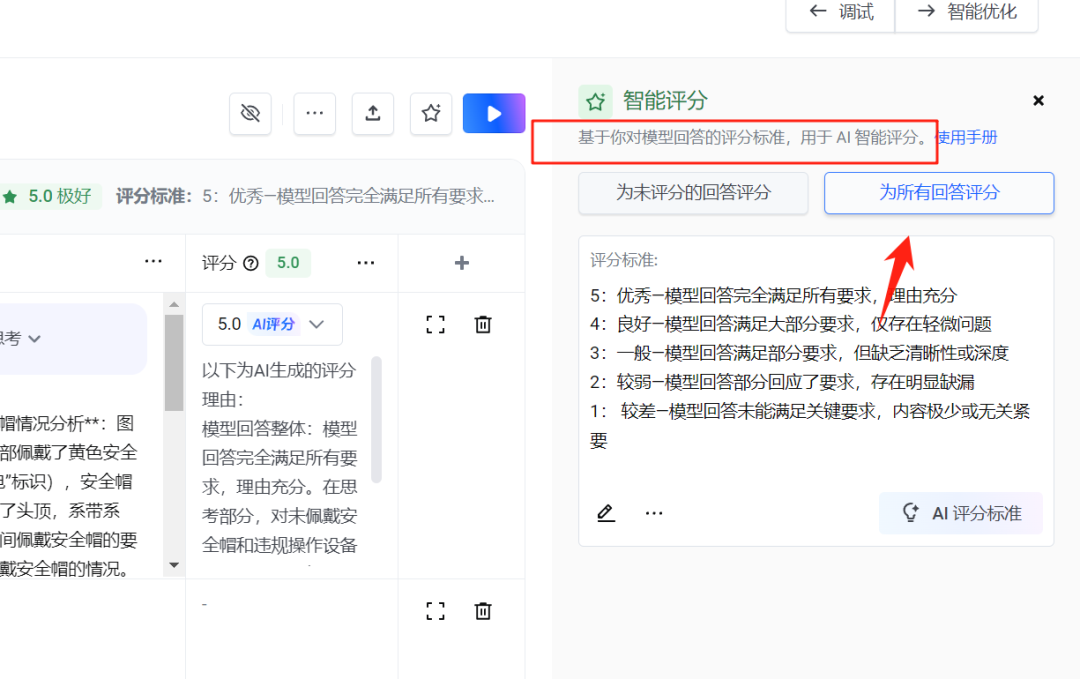
评估标准也可以AI生成:
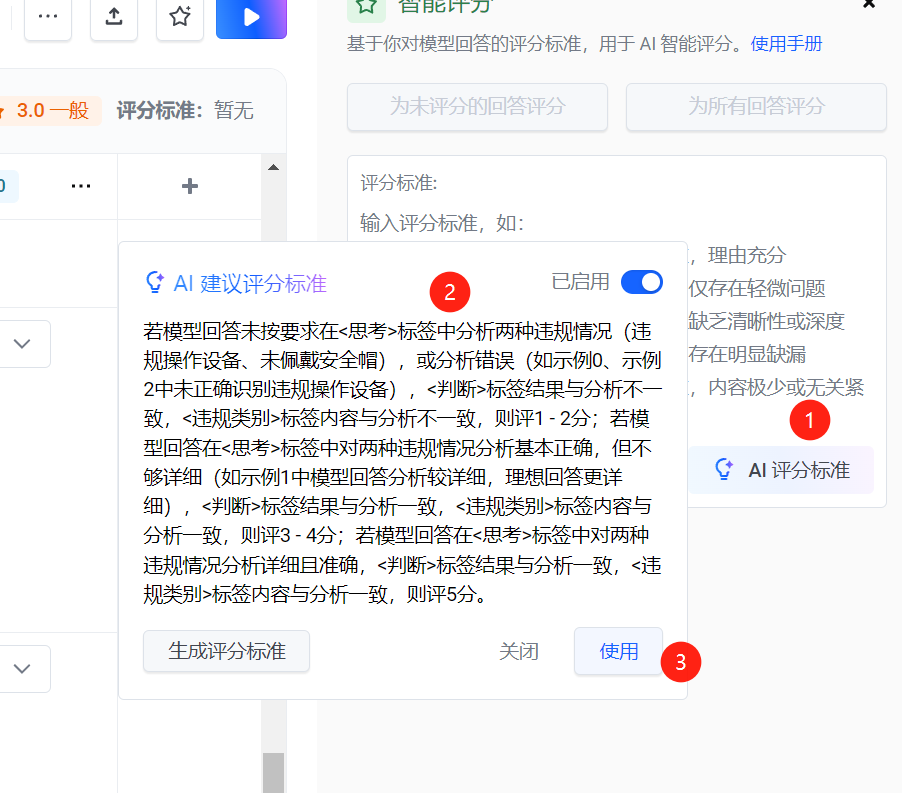
如果 Ai 生成的不够好的话,可以用自己的:比如评估标准有点啰嗦,直接采用如下的评估标准:
思考标签正确,判断标签正确,且违规类型和理想回答一致,得5分;否则得1分,尤其是违规类型和理想回答不一致的话,请直接给1分
( 注意:能用2分制的不要采用多分制,且评分的时候,最好正负样本均有评分,这里采用了5分制,5是满分,1是最低分。)
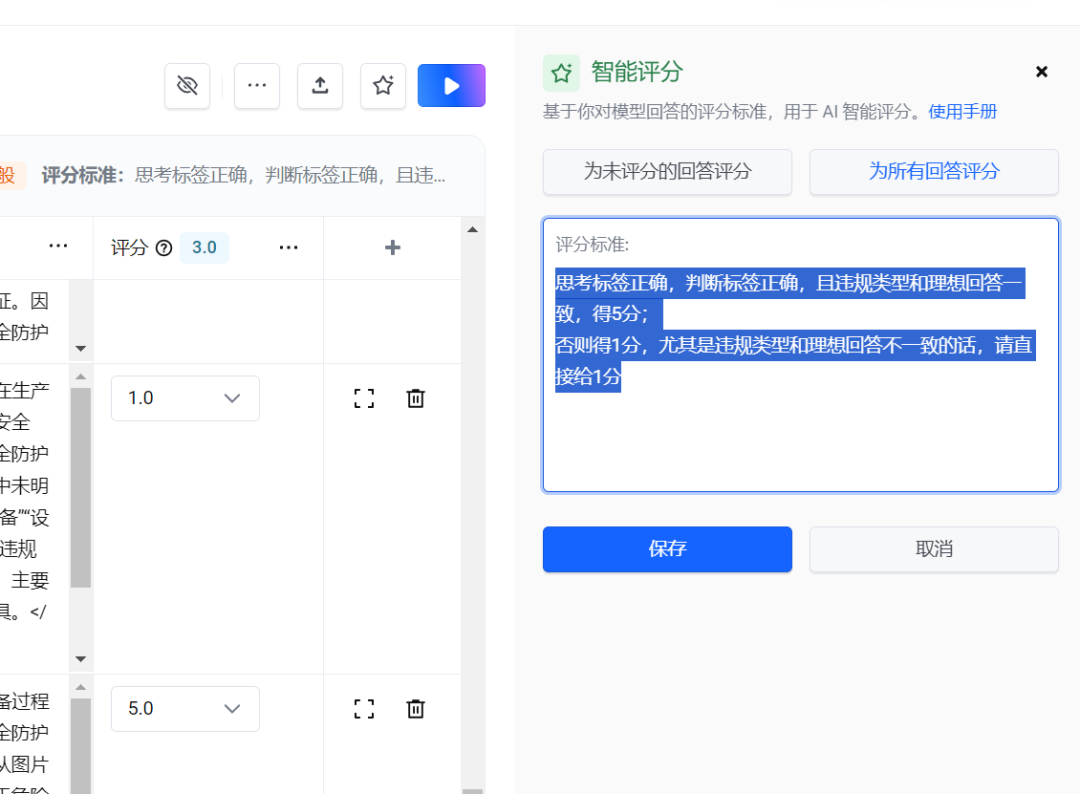
最后一步,进入智能优化页面,并开启优化
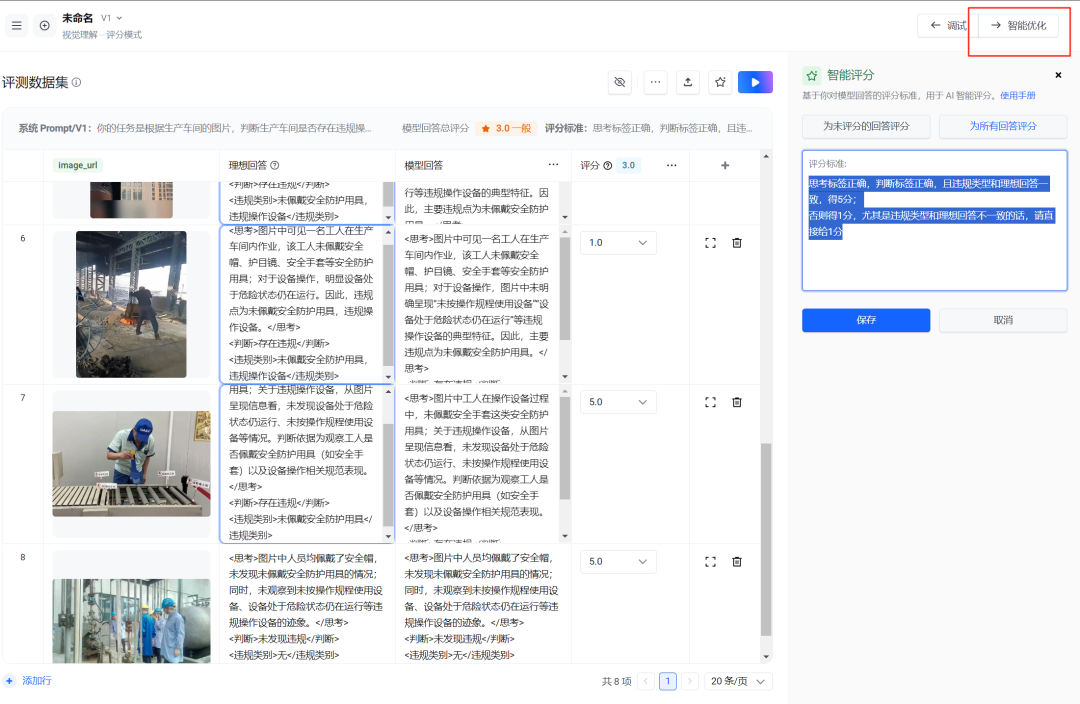
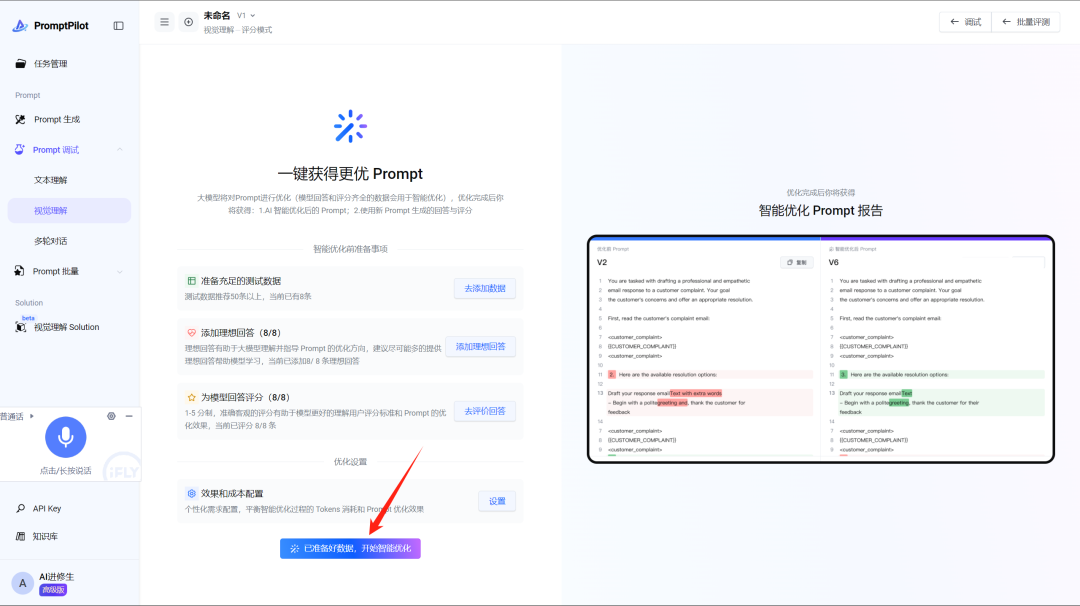
等大约6-10分钟,查看优化报告:
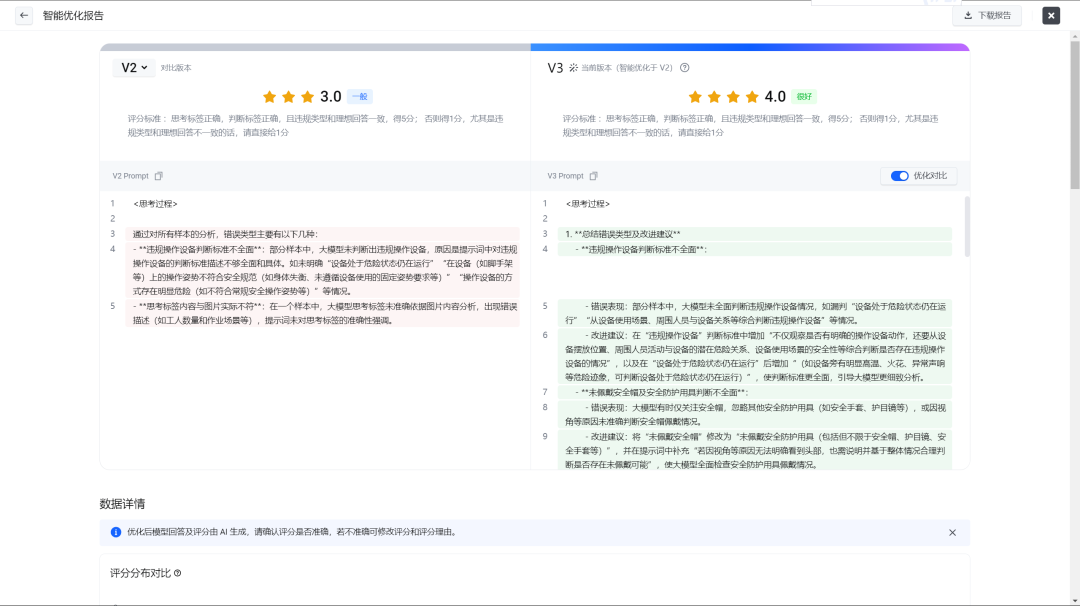
右边第3版的提示词分数达到4.0。说明这个提示词更好。点击V3 Prompt即可复制。
但是如果不满意,想继续优化,可以点如下按钮,继续优化下一轮,通过更多的迭代轮数提高效果。
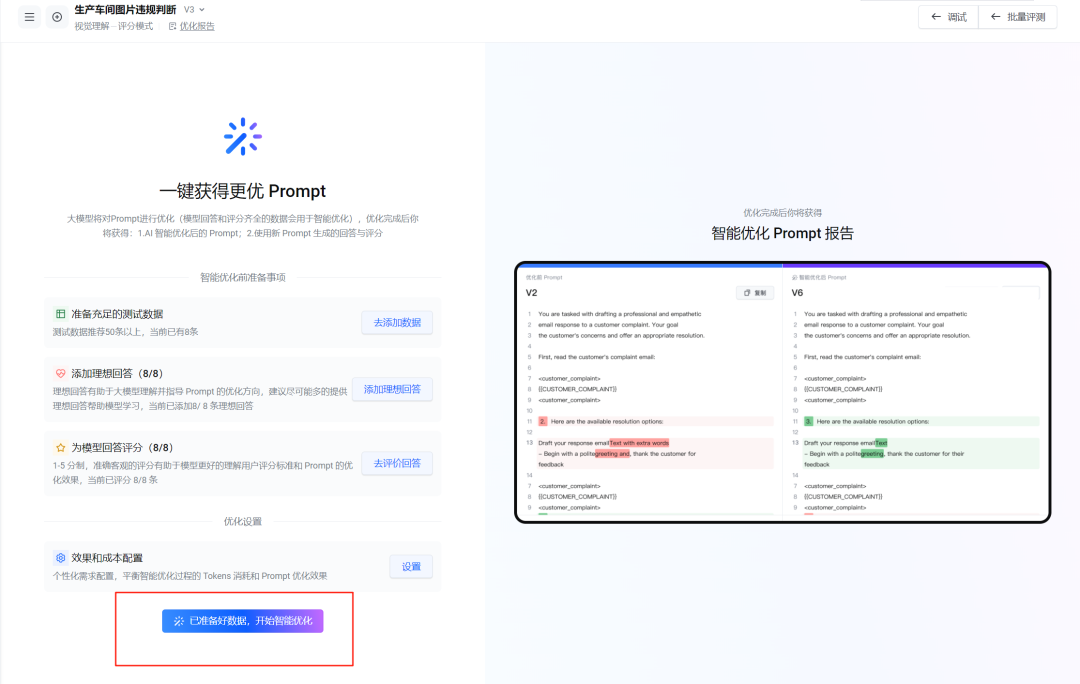
至此,你完整完成了一轮系统提示词优化实操, 而对于我而言,我要优化的提示词通常是文本理解,并不需要图片输入, 比如模型测试、写作、编程等等,同样按照上面的步骤即可。
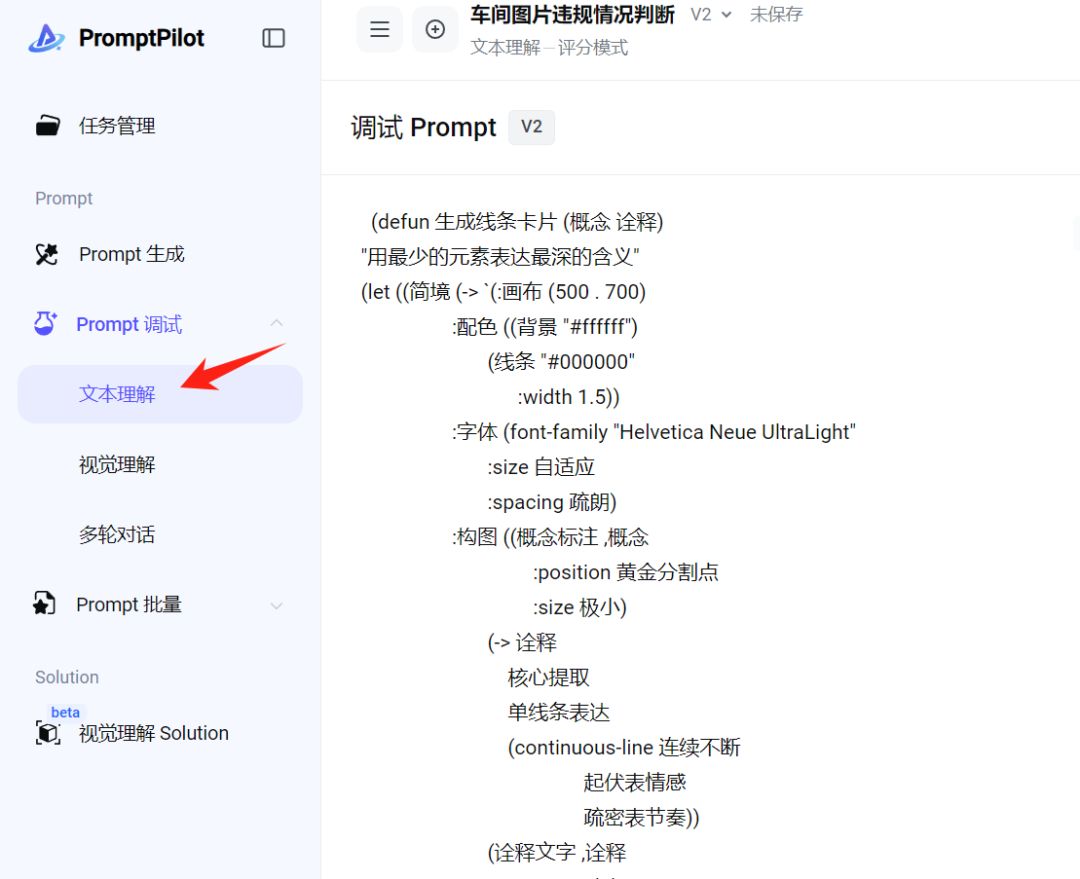
此外,上面我们选的是评分模式,它下面这个gsb比较模式是对比 A/B两种回答,模型根据你的定性反馈,逐步对齐你的隐形偏好,我一般用这个多些。
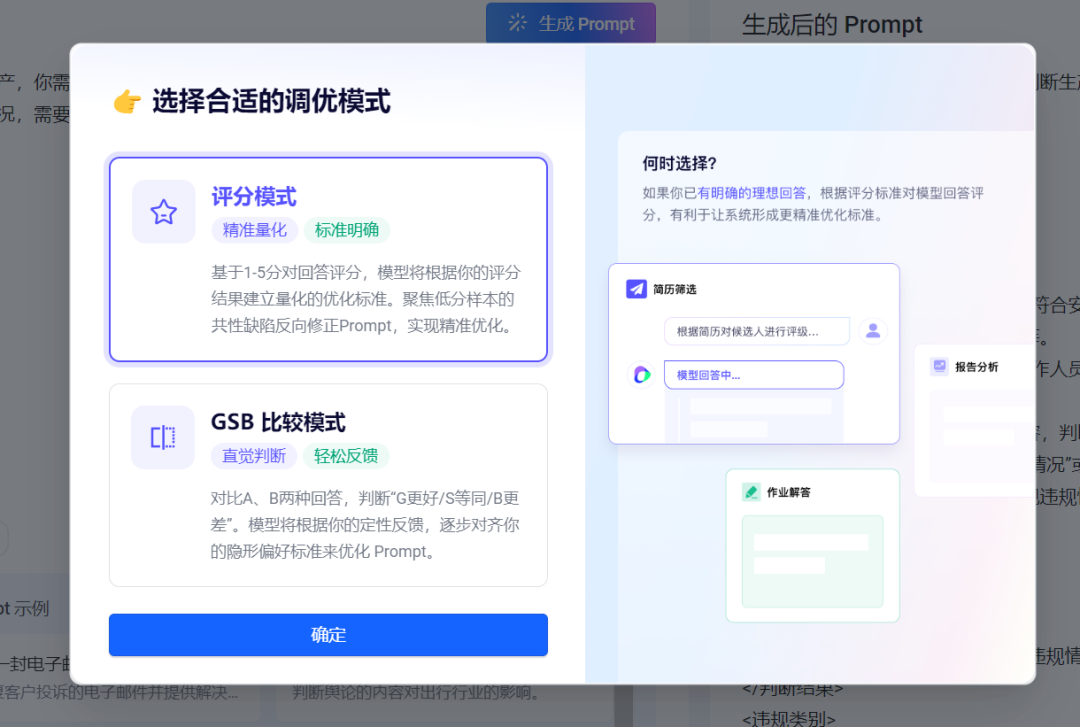
以上便是系统地进行提示词优化的整个流程,你可以在此尝试Promptpilot:
https://promptpilot.volcengine.com/
地址:https://www.volcengine.com/experience/ark?model=doubao-seed-1-6-thinking-250715 (每日50万tokens免费 | 个人)
霓虹对撞机用 JavaScript 和 HTML5 Canvas 创建一个名为 “霓虹对撞机” (Neon Collider) 的交互式2D物理模拟。核心要求如下:
物理核心:一个可旋转的六边形容器和一个在内部反弹的小球。碰撞物理必须考虑墙壁的实时速度,并包含切向摩擦力和恢复系数(弹性)。
视觉特效:小球身后有粒子拖尾效果。与墙壁碰撞时,根据撞击能量产生一个大小和亮度不同的辉光/火花。容器墙壁本身带有霓虹辉光。
交互控制:提供UI滑块,实时控制容器的旋转速度、大小和小球半径。提供按钮用于暂停/继续和重置模拟。地球模型用Three.js创建一个简化的地球模型。提供一个时间轴滑块,范围从“2亿年前”到“现代”。当用户拖动滑块时,地球上的大陆板块(如盘古大陆)会动态地分裂和漂移,最终到达今天的位置。
主要一个是看模型能不能把提示需求做出来,另外一个看做的怎么样。, Doubao-Seed-1.6-thinking-250715 模拟演示了从超级大陆盘古大陆到如今我们熟悉的世界地图的奇妙演变历程。 做的还不错。
洛伦兹吸引子
在Three.js中实现洛伦兹吸引子(Lorenz Attractor)这个混沌系统。通过迭代求解其微分方程组,实时计算出一个点在三维空间中的运动轨迹。用一条带有辉光效果的线段(TubeGeometry或Line)优美地绘制出这条永不重复的“蝴蝶”路径。
测试点: 微分方程数值解法、高性能实时渲染(因为点非常多)、粒子系统或线段生成的艺术美感。
纯粹数学催生出的混沌之美,成果本身就是一件令人着迷的动态艺术品。
在线健身与营养计划生成网站
帮我创建一个名为“Body Architect”的在线健身与营养计划生成网站。核心功能有两个:长期计划定制: 用户输入自己的身体数据(身高、体重、年龄)、健身目标(减脂、增肌、塑形)和每周可锻炼天数,系统能推算出一份为期四周的详细训练计划和每日营养摄入建议(宏量营养素比例)。今日挑战: 用户点击一下,随机生成一个时长15分钟的家庭高强度间歇训练(HIIT)组合动作。两个功能都可以免费生成三次计划。之后,若想解锁更长周期的计划或高级功能(如动作视频库),需要调用Stripe进行月度或年度订阅。网站还提供“认证教练在线咨询”服务,需要调用Stripe按小时付费。付费标准由你设定。你需要学习基础的运动生理学和营养学知识,如TDEE计算、宏量营养素分配原则,并生成对应的推荐算法。网页生成要求与原始提示词一致:使用简洁灰白色背景,动感的无衬线字体(如Manrope),线条图标,营造充满活力和科学感的氛围。强调超大字体或数字突出核心要点(如卡路里、蛋白质克数),形成视觉焦点。中英文混用,英文大字体粗体,中文小字作为点缀。模仿Apple官网的动效(段落切屏 & 视差缩放等),使用anime.js实现。使用在线图表组件(如Chart.js)可视化营养素比例和训练进度。技术栈:HTML5、TailwindCSS 3.0+ (CDN)、必要的JavaScript、Google Fonts、Font Awesome/Material Icons (CDN)。避免使用emoji。Doubao-Seed-1.6 生成的结果 所有功能覆盖:长期计划定制、今日挑战、免费次数限制、Stripe 订阅和咨询付费、设计风格、动效、Chart.js 可视化、算法计算等等。Stripe跳转,其实按照原提示词的需求来说,基本是做到的。“用户点击一下,随机生成一个时长 15 分钟的家庭高强度间歇训练”都是正常的,只是轮盘显示那里不太美观。
在线香水配方生成网站
帮我创建一个名为“Olfacto Lab”的在线香水配方生成网站。核心功能有两个:深度定制: 用户通过回答一系列关于性格、偏好场景、喜爱季节的问题,系统能推算出一款独特的个人香水配方(前调、中调、后调的成分与比例)。灵感一刻: 用户点击一下,随机生成一款基于特定主题(如“雨后森林”、“夏日海滩”)的创意香水配方。两个功能都可以免费试用三次。之后,若想获得无限次生成或保存配方,需要调用Stripe进行订阅付费。网站下方还有一个“调香大师一对一咨询”服务,同样需要调用Stripe按次付费。付费金额和订阅方案由你设计。你需要先学习香水的前中后调搭配原理和常见香料的特性,并生成相应的推荐算法。网页生成要求与原始提示词一致:使用简洁灰白色背景,衬线字体(如Cormorant Garamond),线条图标,营造实验室般的精准与优雅氛围。强调超大字体或数字突出核心要点(如配方比例),形成强烈的视觉反差。中英文混用,中文大字体粗体,英文小字作为点缀。模仿Apple官网的动效(段落切屏 & 视差缩放等),使用anime.js实现。使用在线图表组件(如Chart.js)以雷达图或饼图形式可视化香气的构成。技术栈:HTML5、TailwindCSS 3.0+ (CDN)、必要的JavaScript、Google Fonts、Font Awesome/Material Icons (CDN)。避免使用emoji。界面和在线香水配方网站也是比较符合。免费试用三次是生效的。
精准的“概念证伪”与“善意重构”
请解释一下量子物理中的‘弦理论逆火效应’(String Theory Backfire Effect),以及它如何解释宇宙大爆炸初期的非对称性。 (这是一个我刚编的、听起来很科学的术语)
-
测试意义: 这是模型智能水平的试金石。
-
差的回答: 可能会编造一个“前额叶回响效应”的定义,陷入严重幻觉。
-
好的回答: 指出非标准,然后 主动搭建桥梁,将用户的通俗理解引导到正确的科学概念上 (持续性神经活动、神经振荡)。

它准确地回答了问题,它展现的 思维方式 :
-
先质疑,再回答。
-
先定义问题,再提供方案。
-
先展示力量,再划定边界。
这是一个较好的AI模型的输出:逻辑推理、知识整合和批判性思维。如果这是一个人的回答,那这位回答者显然在该领域有非常扎实的功底和出色的沟通能力。
Doubao-Seed-1.6-thinking-250715 推理思考能力显然不错。
限于篇幅,测试尝试到此截止了,下面还有很多其他的好玩意:
SOTA 向量模型
除了上面两款模型外,还有个新的:
Seed1.6-Embedding 登顶多榜单 SOTA,首发全模态混合检索
字节跳动豆包大模型团队又搞了个新东西,最新的全模态向量化模型:Seed1.6-Embedding。
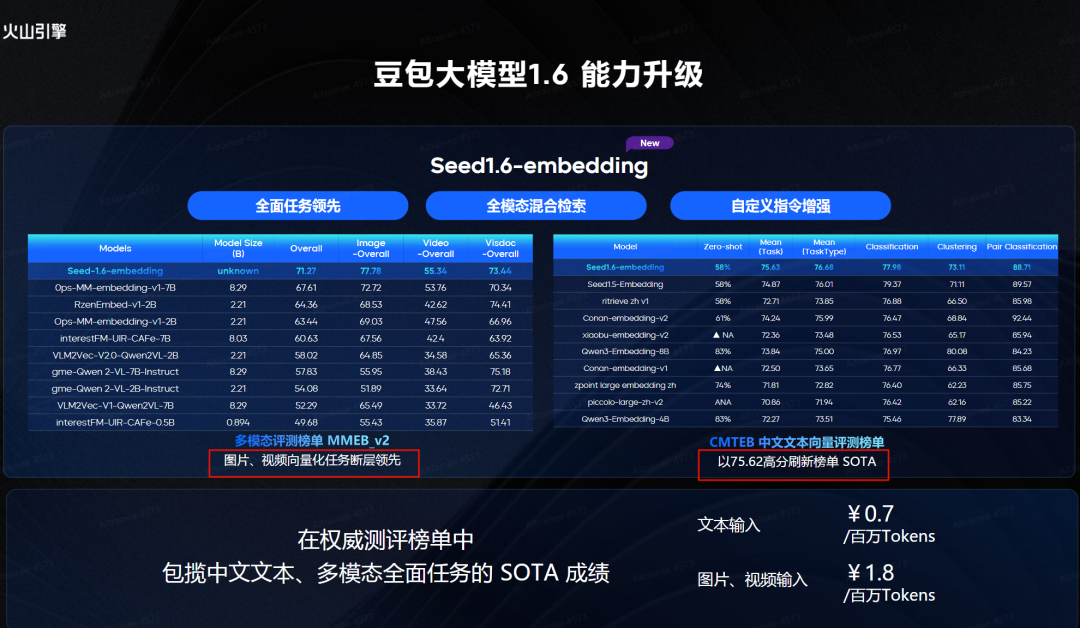
这模型在能力上又升了一级,第一次能把视频也向量化了,让多模态搜索和理解更深入。在所有向量化场景里,它都称得上是最佳选择。
纯文本的权威测评榜单 MTEB 上,Seed1.6-Embedding 达到了中文 SOTA。多模态测评榜单 MMEBv2 上,它在图片、视频任务上也都是 SOTA。
它具体牛在哪呢?
-
全面任务都领先:图文检索更懂了,同时保持了上一代模型的 SOTA 水准。在语义匹配 (STS) 这些常用向量化任务上也领先,各种任务都能搞定,泛化能力更强。
-
全模态混合检索:这是它第一次能把视频也向量化了。它能把人物、动作、场景这些视频里的关键信息统一建模,用多张图也能代替视频输进去,输入方式更多样了。
更厉害的是,文本、图片、视频帧,各种模态混着输进去它也能理解,在跨模态搜索、内容理解、多模态 Agent 这些场景里,用起来更灵活。这可是业界第一个支持混合模态检索的 embedding 模型。
-
自定义指令更智能:模型更懂指令了,响应也更快。你可以自己定指令模板,让它生成的向量表达更贴合你的业务。实际落地时,能用更小的代价,把效果搞得更好。
构建Agent,一个API就够了
火山方舟平台的 API 体系升级了,搞了个新东西叫 Responses API。

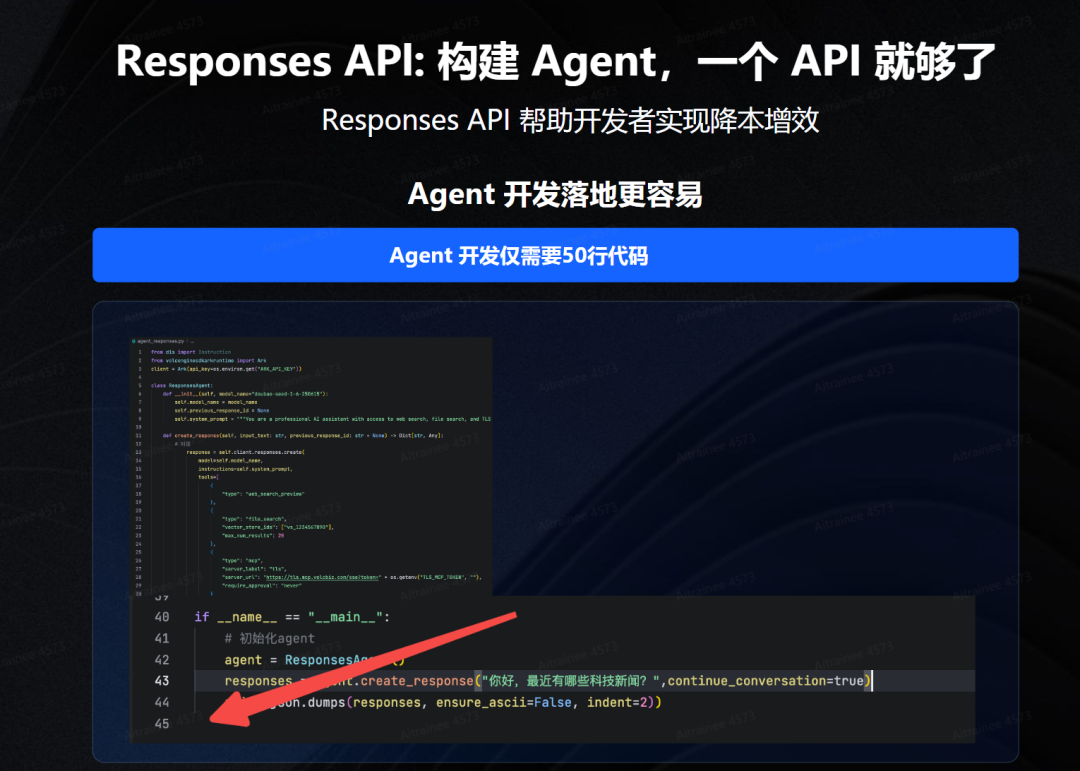
这玩意儿有两大本事。
首先,它自带原生上下文管理能力,能把多轮对话连起来。不管是文本、图像,还是混合的数据,都能无缝衔接。
如果 Responses API 再跟缓存能力结合,那延迟会更低,成本也会大幅减少。整个开发难度也跟着大大降低。很多典型的应用场景里,总成本能直接省下 80%。
其次,Responses API 最厉害的地方,是它能自己选择调用工具。你只需要发起一次请求,它就能帮你调动多个内置工具、自定义函数,甚至多轮模型组合起来响应,解决那些复杂的 Agent 任务。
举个智能助手 Agent 的例子。以前用传统方法,你可能要写大约 460 行代码才能搞定。现在用了 Responses API,只需要 60 行就能实现。
这意味着开发时间从原来的一两天,直接缩短到了一个小时。这样一来,开发者就能把更多精力花在 Agent 本身的效果调优上,让 Agent 的开发和最终落地,变得更容易。
AI 知识管理
还有个新东西 ,叫 AI 知识管理。它是个文件问答助手,专门给企业白领和广大知识工作者准备的。在商业分析、营销咨询、产品研发、学术研究这些需要大量知识的场景下,它能大大提升你解决问题、生产知识和团队协作的效率。
它有三大核心本事:
-
1. 海量多模态内容都能懂。
你能上传超多文件数据给它,图片、视频、超大文件它都能理解和处理。你问问题,它就能给你出图文并茂的答案。单个任务支持传 1000 多个文件,单个文件能到 200MB。飞书文档也能批量上传,还能自动更新。 -
2. 知识分享和探索更个性。
你把自己整理好的知识库分享给同事,AI 会根据接收者的个人情况(比如职业、兴趣),还有你分享的目的,生成一份专属的探索指南。这样,接收者就能跟着指南,一步步、更有针对性地学习,对知识库内容的了解也更生动。 -
3. 可交互的深度研究。
遇到复杂问题,你能让 AI 先“做个计划”,而且这个计划的每一步,你都能精确修改。 AI 还会自己联网去搜资料,结合网上内容全面理解,然后给出答案。这样出来的结果,就会更符合你的预期。
我们以一个案例做演示:
根据开发者文档,让 AI “做个计划”产出部署方案
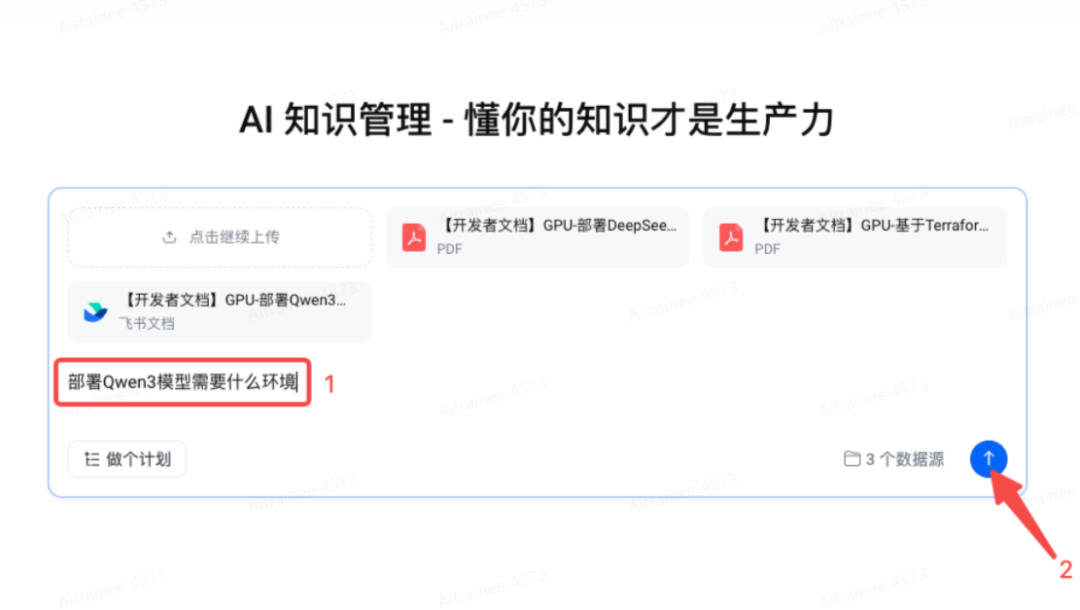
在浏览器中输入 aisearch.volcengine.com ,将直接进入 AI 知识管理首页
第一步:上传资料
可以是本地的或者飞书文档
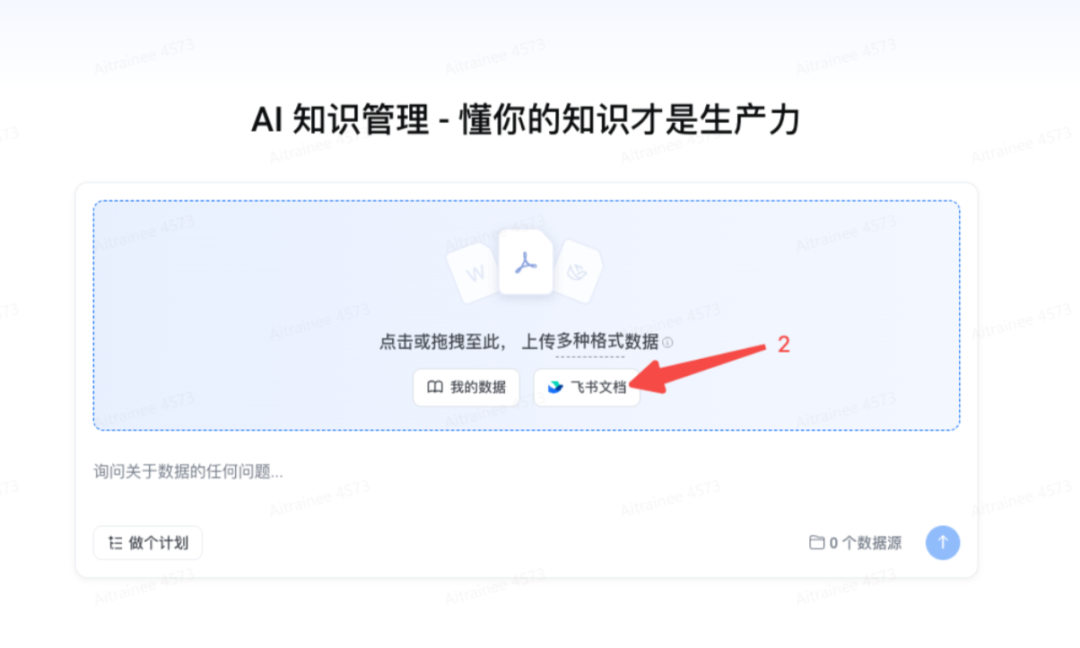
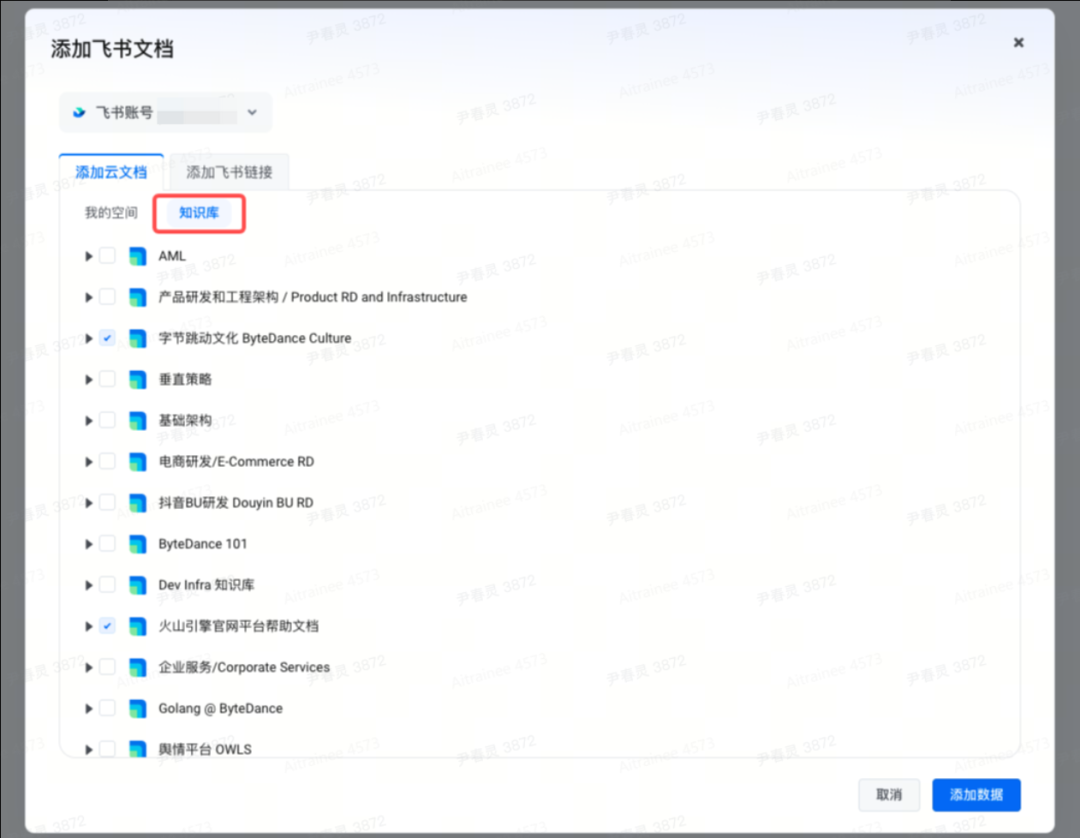
支持 飞书文档批量导入 功能,帮助快速构建知识库
进行简单问答
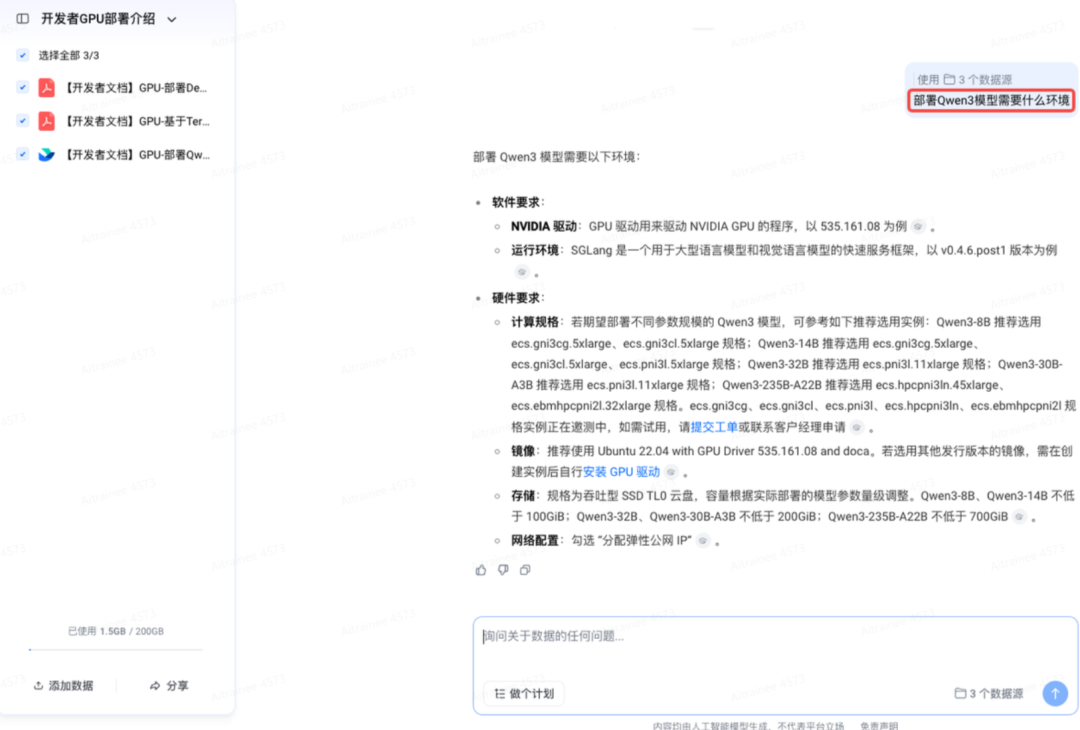
做个计划
打开“做个计划”进行提问
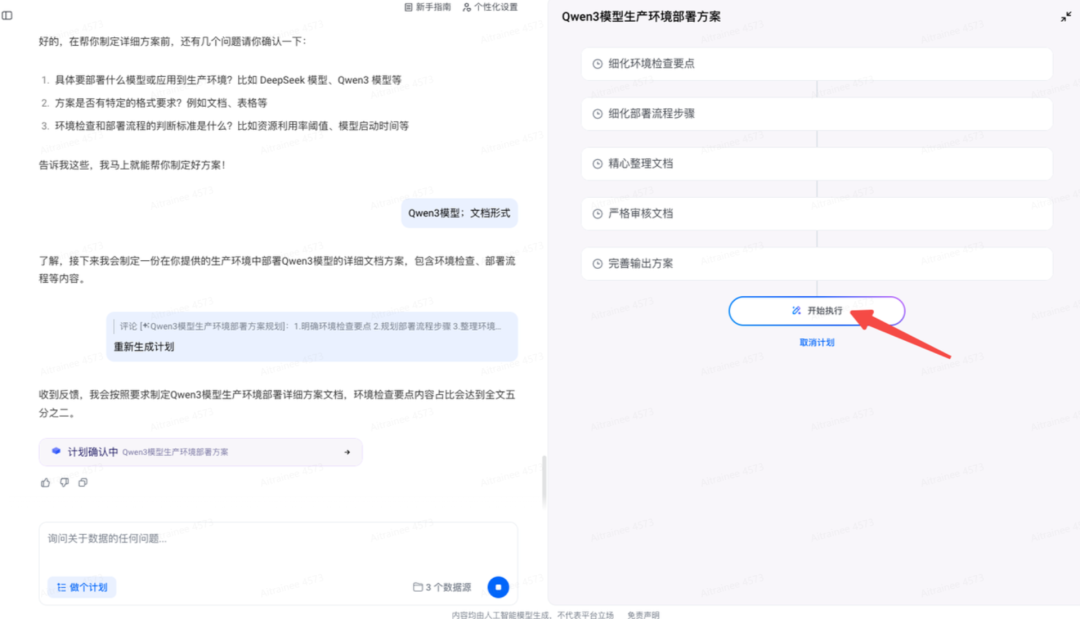
根据自己生产环境,让“做个计划”根据开发者文档帮你生成一份详细的部署方案:
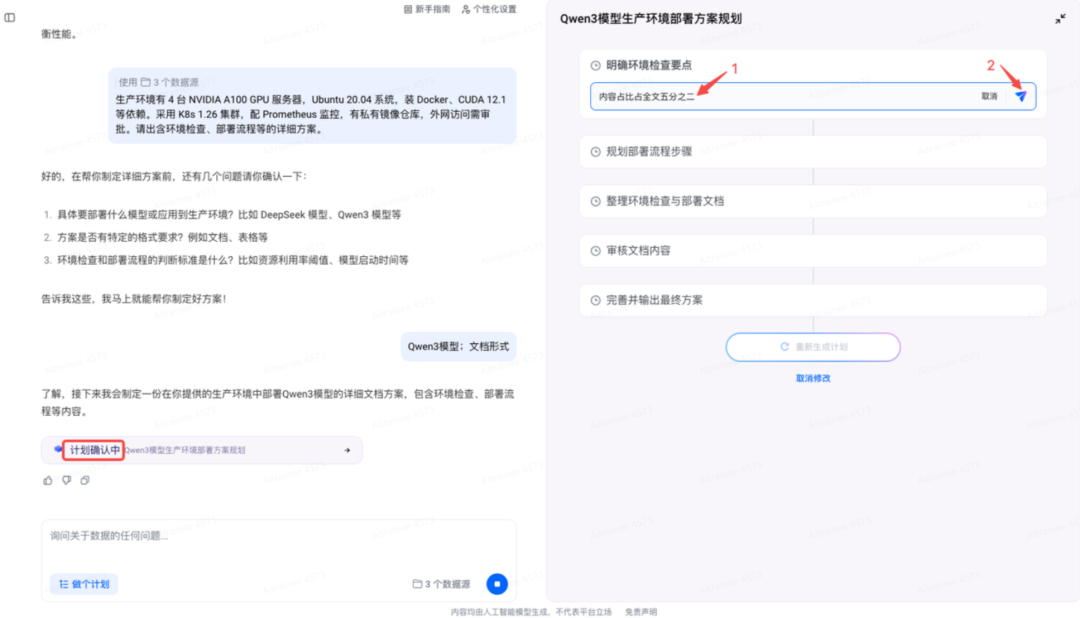
示例:生产环境有 4 台 NVIDIA A100 GPU 服务器,Ubuntu 20.04 系统,装 Docker、CUDA 12.1 等依赖。采用 K8s 1.26 集群,配 Prometheus 监控,有私有镜像仓库,外网访问需审批。请出含环境检查、部署流程等的详细方案。

对计划进行修改
示例:内容占比占全文五分之二
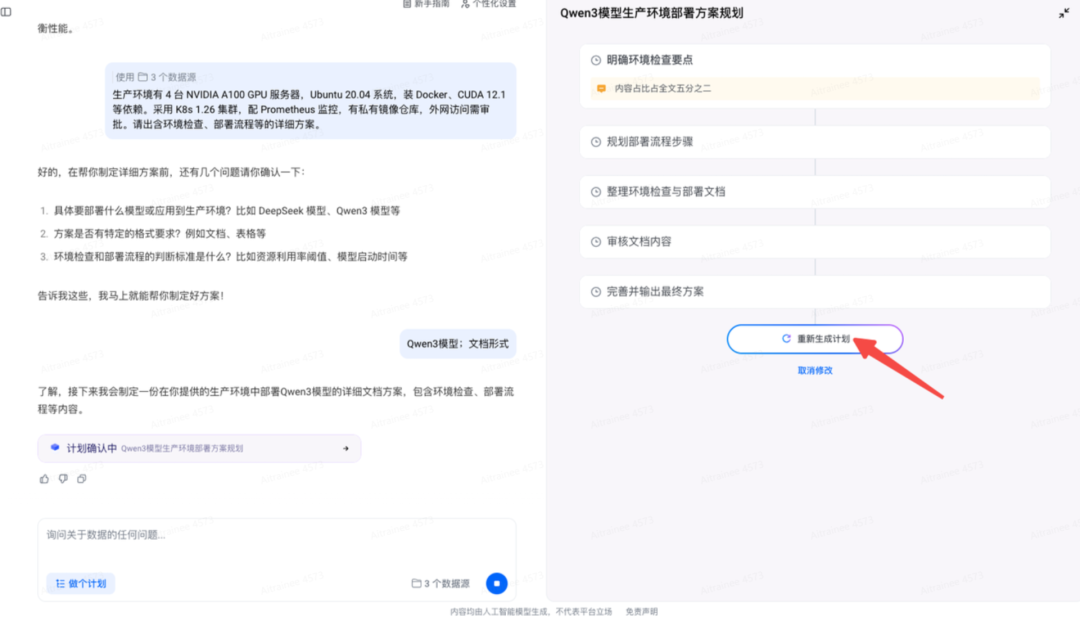
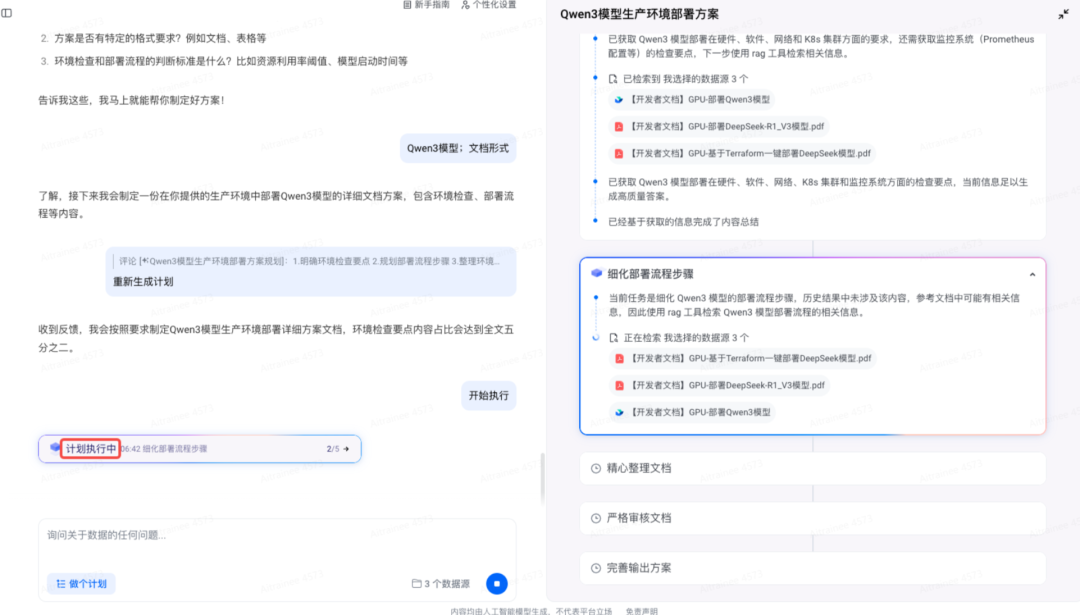
执行计划
执行计划的时间较长。在执行计划的过程中,可以切换到其他任务、开启新任务,或者进行其他工作,让计划在后台继续运行。 在此建议可以尝试下一个任务“ AI 知识管理 PRD 问答”
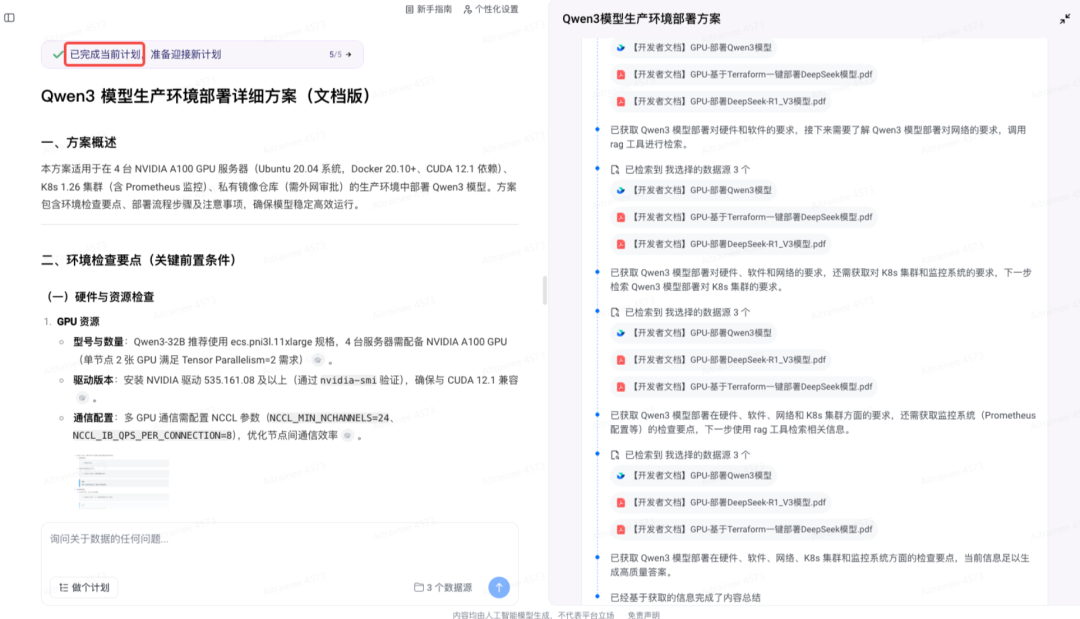
查看结果
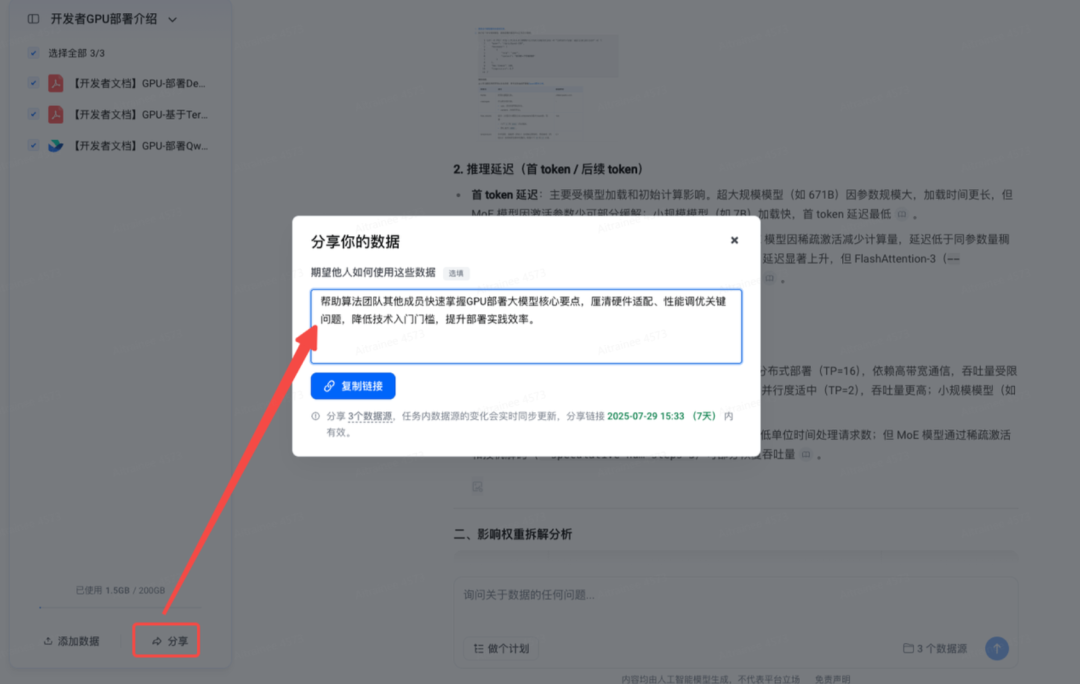
分享数据
示例:帮助算法团队其他成员快速掌握GPU部署大模型核心要点,厘清硬件适配、性能调优关键问题,降低技术入门门槛,提升部署实践效率。
最后,附加个教程 —— AI 知识管理开通 & 使用教程:
https://bytedance.larkoffice.com/wiki/C9UUwcf04i8g9kkl2VGc70tVnte
豆包多模态模型+知识库
还有一个多模态的知识库
详情在这:https://console.volcengine.com/auth/login?redirectURI=%2Fvikingdb%2Fknowledge%2Fregion%3Avdb-knowledge%2Bcn-beijing%2Fcollection%2Flist
Viking:字节的知识库和向量库
VikingDB 是字节自研的高性能云原生向量数据库。这东西可不一般,从 2019 年就开始支撑抖音的推荐系统了。经过这么多年打磨,性能在全球都是领先的。
最近,他们又进行了一波大升级:
-
索引全面升级:以前只能跑内存索引,现在扩展到了磁盘索引和 GPU 索引,亿级数据也能跨介质检索了。同样的数据量,检索性能直接是行业主流的 3 倍。
-
性价比更高:在亿级以上数据场景,优化后的 DiskANN 磁盘索引,比传统内存索引,成本降了 75%。跟业界其他磁盘方案比,资源成本也能降 60%。
-
全模态表征能力:实现了一键式的文本、图片、视频端到端向量化与检索,用起来更方便。你不用自己建模型,也不用手动处理,直接把原始数据扔进去,系统自动帮你搞定向量化转换。

基于这个向量数据库,字节还搞了个好用的知识库产品。升级后的知识库,支持图、文、视频的多模态处理和混排输出,在国内外的评测里效果都更好了。 对于想用火山知识库的开发者,他们还推出了标准版,价格只有旗舰版的十分之一。

VikingDB 向量数据库多模态检索开发者体验:https://b yte dance.larkoffice.com/docx/YQzLd4d0coCcrjxqM1Jcfulonve
方舟协作奖励计划
火山方舟平台搞了个“协作奖励计划”。
这个计划主要是想通过每天送免费 tokens,来降低大家上手的门槛。
目前这个活动,主要面向企业认证用户和个人认证用户。一个主体下面,只能有一个账号参加。
怎么拿奖励?
-
参与时就有奖励:
你参加的时候,需要指定一个能授权的推理接入点(endpoint)。授权之后,就能立刻拿到一个资源包。
企业用户是 500 万 tokens,个人用户是 50 万 tokens。
这个包只能用在授权过的模型上,有效期 1 个月,主要就是帮你降低刚开始用的成本。 -
每日返还:
参与之后,方舟每天会从凌晨开始,在授权的 endpoint 范围内,顺序采集每个模型不超过 500 万 tokens(企业)或 50 万 tokens(个人)的数据。
第二天,就会把你采集了多少,就返还多少 tokens,资源包有效期也是 1 个月。
活动时间:
-
当前阶段:从现在开始,一直到 2025 年 8 月 31 日。
-
完整周期:从现在开始,到 2025 年 11 月 30 日结束。
以上。
#prompt #豆包升级 #promptpilot
🌟知音难求,自我修炼亦艰,抓住前沿技术的机遇,与我们一起成为创新的超级 个体(把握AIGC时代的个人力量)。
点这里👇关注我,记得标星哦~
(文:AI进修生)