
大模型
大语言模型

模型崩溃自救指南:5行代码实现TTA鲁棒性飞跃,天大×腾讯开源COME方案
文章介绍了测试时适应(TTA)方法中的熵最小化(EM),并指出其存在的过度自信和模型崩溃问题。COME通过显式不确定性建模和自适应熵优化解决了这些问题,显著提升了模型在各种复杂场景下的预测能力。


基于milvus向量数据库的相似度检索问题——稀疏-密集向量检索和混合搜索
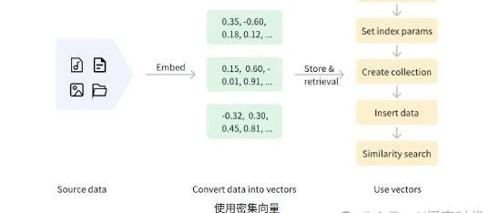
不同的向量类型可能导致相似度检索策略不同。Milvus支持稠密和稀疏向量,以及混合搜索技术。稠密向量用于语义检索,稀疏向量用于精确关键词匹配,混合搜索适用于复杂场景。
谷歌 Prompt Engineering 白皮书中文版来了:DeepL 和沉浸式翻译谁更强?

文章介绍了谷歌《Prompt Engineering》白皮书的中文翻译版本,推荐了DeepL Pro和沉浸式翻译两种方式,并重点推荐了BabelDOC PDF翻译效果最佳。
中文网页检索挑战上线!GPT-4o准确率仅6.2%,这份新基准打脸所有大模型

港科大联合发布的新基准测试集BrowseComp-ZH显示,20多个主流大模型在中文网页检索任务中的准确率普遍低于10%,OpenAI的DeepResearch仅得42.9%。研究强调当前主流模型还需提升多轮搜索和信息整合能力。
WWW 2025 数据洪流→数据精炼:北理工等提出高效文本行人检索新范式

北京理工大学、澳门大学与新加坡国立大学联合提出Filtering-WoRA范式,实现无需全量训练的高效行人检索。该方法通过两阶段数据过滤和Weighted Low-Rank Adaptation(WoRA)显著减少模型参数并提高计算速度。

