ICCV 2025 视觉Token跳起来!上交大×蚂蚁联手推出多模态通用加速框架

近日,上海交通大学人工智能研究院晏轶超副教授联合蚂蚁集团的研究团队提出Skip-Vision框架,无需额外预训练或重新训练大模型,在SFT流程中插入即可加速视觉-语言模型。该框架通过跳过冗余视觉Token和使用Summary Token机制在保留理解能力的同时显著降低计算开销和延迟。
大语言模型
近日,上海交通大学人工智能研究院晏轶超副教授联合蚂蚁集团的研究团队提出Skip-Vision框架,无需额外预训练或重新训练大模型,在SFT流程中插入即可加速视觉-语言模型。该框架通过跳过冗余视觉Token和使用Summary Token机制在保留理解能力的同时显著降低计算开销和延迟。

文章介绍了科研过程中的方法和技巧,强调了实践的重要性超过单纯阅读文献。它推荐了一门由顶级学术会议主席讲授的系统课程,涵盖选题、实验设计等多个环节,帮助新手快速提升论文发表能力。
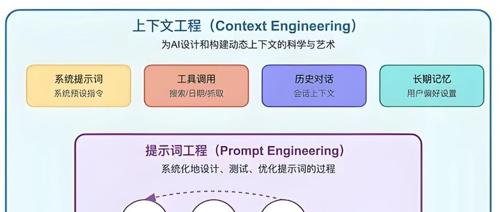
AI 智能体通过上下文工程管理‘心智世界’。它涉及信息选择、组织和注入方式,以及上下文的动态性、可扩展性和准确性,以高效填充LLM的上下文窗口。

华为盘古模型项目负责人王云鹤被指剽窃成果、技术造假。文章指出,王云鹤调集资源将国产昇腾芯片训练体系替换为NVIDIA方案,并通过135B模型的署名问题进一步曝光人才流失情况。

法国AI研究机构Kyutai Labs开源最新文本转语音技术Kyutai TTS,支持实时交互场景,性能卓越,已在GitHub和Hugging Face开放源码与模型权重。

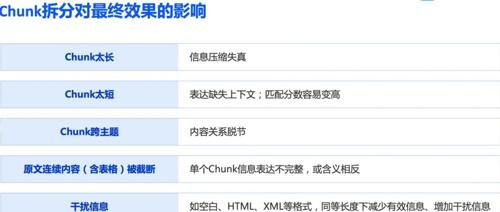
2025年7月9日,北京晴天。文章总结了SIGIR 2025 LiveRAG竞赛的评测报告,并介绍了信息抽取和多模态大模型训练的相关方案。强调在轮子同质化背景下,业务know-how的重要性,指出文档解析、RAG及大模型应用出现同质化严重现象。同时提到了两个大模型训练指引资源。

今天回顾了文档版式及表格数据合成的相关工具和技术。其中包括7个OCR合成数据工具和2种文档版式及表格数据合成工具。这些技术将在实际工作中应用,助力提升效率。老刘也分享了自己的开源项目及其心得。