
Linear-MoE:线性注意力遇上混合专家的开源实践
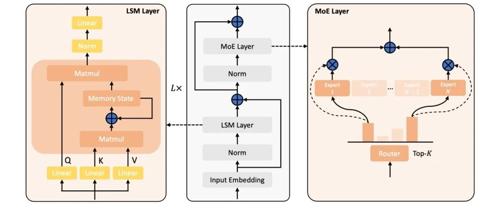
近年来,大语言模型的研究热点转向了线性序列建模和混合专家架构的高效结合。来自上海人工智能实验室团队的Linear-MoE首次系统地实现了这两者的结合,并开源了完整的技术框架,支持层间混合架构。
近年来,大语言模型的研究热点转向了线性序列建模和混合专家架构的高效结合。来自上海人工智能实验室团队的Linear-MoE首次系统地实现了这两者的结合,并开源了完整的技术框架,支持层间混合架构。

562146477609112
编辑丨GiantPandaLLM
0x00 前言
Triton Fu
伟、郭京翔、胡越、陈浩楠、陈俊廷、吴睿海。通讯作者为新加坡国立大学计算机学院助理教授邵林,研究方向为

本文提出ZeroSearch框架,无需真实搜索引擎即可激活大语言模型搜索能力。通过轻量级监督微调将LM转为检索模块,并采用课程学习逐步降低文档质量来激发推理能力,显著降低训练成本和提高性能。

Intology 的 AI 科学家 Zochi 的论文《Tempest: Automatic Multi-Turn Jailbreaking of Large Language Models with Tree Search》被顶级科学会议 ACL 接收,成为首个独立通过 A* 级别科学会议同行评审的人工智能系统。




