


本文介绍工作由中国人民大学高瓴人工智能学院宋睿华团队、李崇轩、许洪腾与值得买科技 AI 团队共同完成。第一作者王希华是人大高瓴博士生(导师:宋睿华),他的研究兴趣主要在多模态生成,之前提出利用音频布局(audio layout)为视频生成同步声音的TiVA模型,已发表在MM 2024。宋睿华的团队主要研究方向为多模态理解、生成与交互。
想象一下:只需一张静态图片,系统就能自动生成一段「动态的、有声音的」的短视频,画面中的人或物做出自然动作变化的同时,也发出对应的声音——比如小鸡抬头打鸣、手指按下快门并伴随咔嚓声,这正是「图像转有声视频(Image-to-Sounding-Video, I2SV)」的目标。
近日,来自中国人民大学高瓴人工智能学院与值得买科技 AI 团队在 CVPR 2025 会议上发表了一项新工作,首次提出了一种从静态图像直接生成同步音视频内容的生成框架。其核心设计 JointDiT(Joint Diffusion Transformer)框架实现了图像 → 动态视频 + 声音的高质量联合生成。

-
论文标题:Animate and Sound an Image
-
项目主页:https://anonymoushub4ai.github.io/JointDiT
为什么图像转有声视频是「AI 多模态生成」的新蓝海?
人类对世界的感知本质上是多模态的。视觉与听觉作为最主要的感官通道,通常以协同互补的方式构建起完整的认知体验——枝叶摇曳伴随沙沙风声,浪花飞溅伴随潮汐轰鸣,这些视听融合的场景不仅丰富了感官感受,也承载了我们对物理世界深层次的理解。
尽管近年来生成模型在单一模态的内容合成上已取得长足进展,如生成高保真的视频画面或自然的音频片段,但视觉与听觉这对天然耦合的模态,长期以来却被拆分为两条相对独立的研究路径,缺乏统一的建模机制。
最近,谷歌在其视频生成模型 Veo 3 中引入了同步音频的功能,让视频生成真正迈入「有声时代」,成为行业关注的亮点。与这一趋势不谋而合,本文首次提出并系统定义了图像到有声视频生成(Image-to-Sounding-Video,I2SV)这一新任务:让静态图像「动」起来的同时,生成与之语义匹配、时间同步的音频内容。
虽然当前已有技术能够分别实现从图像生成视频或音频,但将两者「拼接」在一起往往难以自然融合,常见的问题包括语义错位与节奏失调:比如视频中的小狗并未张嘴,却配上了汪汪的叫声;又或是吠叫的动作刚发生,声音却慢半拍甚至不协调。
图像生成有声视频示例:上:图生视频(SVD)+ 图生音频(Im2Wav),下:本工作 JointDiT
因此,如何从一张图片出发,生成同时具备视觉动态性与听觉一致性的完整「视听视频」,成为多模态生成领域亟待突破的关键挑战。
JointDiT:实现图像 → 同步音视频的联合生成
任务定义:这项研究把图像转有声视频任务(I2SV)定义为:以静态图像作为输入条件(并看作输出视频首帧),生成一个语义匹配、时序同步的「视频 + 音频」(有声视频)片段。
解决方案:论文提出了一种全新架构 JointDiT,探讨了如何利用两个强大的单模态预训练扩散模型(一个视频生成器,一个音频生成器),在其上构建统一的联合生成框架实现多模态协同生成。
其主要设计包括:
分解与重组预训练模型,实现联合生成框架
为了构建高效的图像转声音视频模型,JointDiT 采用了「重组 + 协同」的创新思路:首先,作者对预训练的音频和视频扩散模型进行层级解构,将每个模型划分为三大模块:输入层(负责模态嵌入)、专家层(模态内部理解与压缩)、输出层(解码生成)。随后,在两个模态的专家层之间引入联合注意力机制与前向模块,形成核心的「Joint Block」,实现音视频间的深层交互。最终,通过共享 Joint Block、独立输入输出层的设计,JointDiT 在保持模态差异处理能力的同时,实现了真正协同的多模态生成,创新性地实现了从一张图片直接生成同步音视频内容。
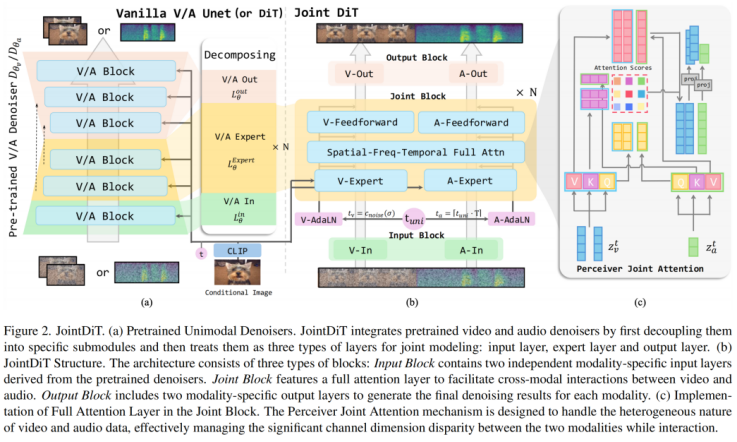
引入感知式联合注意力,精准建模跨模态互动
传统的在全序列(音视频序列)上应用自注意力机制(Full Attention)难以处理视频与音频在时间、空间、频率维度上的异构差异。JointDiT 专为此设计了感知式联合注意力机制(Perceiver Joint Attention),使用模态特定的 Query-Key-Value 映射,实现对视频帧与音频序列之间的细粒度互动建模,有效提升同步与语义一致性。
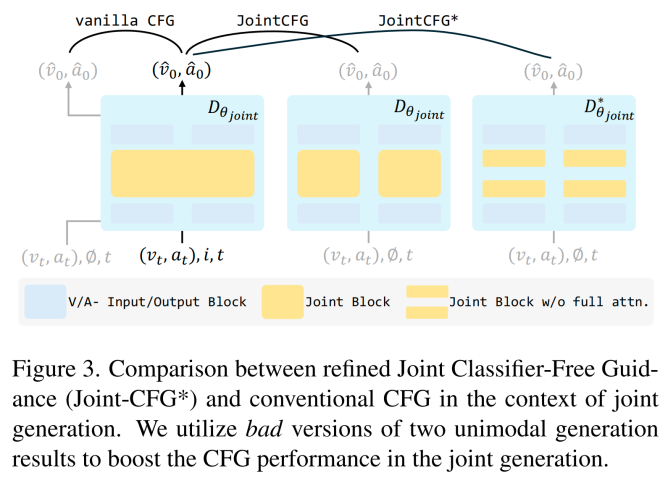
联合引导机制,兼顾条件控制与模态协同
传统的无分类器引导(classifier-free guidance, CFG)技术主要用于强化生成结果对条件的响应,同时抑制低质量输出。但在多模态生成中,单纯的条件对齐并不足以保障音视频之间的深度协同。为此,JointDiT 提出联合无分类器引导(JointCFG)及其增强版 JointCFG*,在保留图像条件引导对齐的同时,强化了模型对跨模态之间交互的关注,进而提升了音视频之间的语义一致性与时间同步性。该策略不仅优化了生成质量,还显著增强了视频的动态表现力。
实验结果如何?高质量、高一致性!
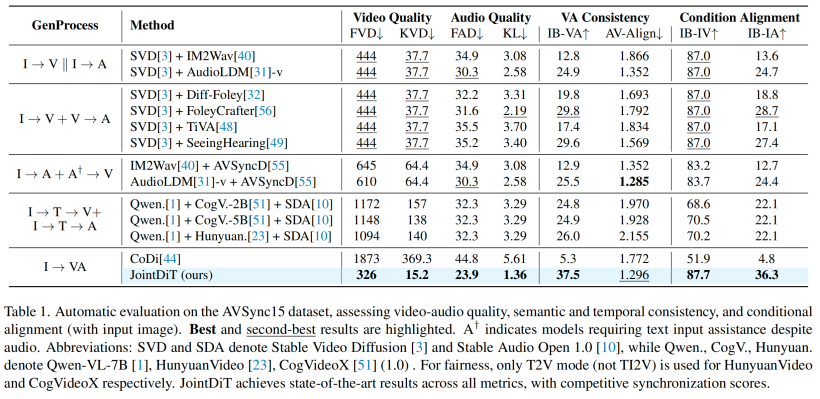
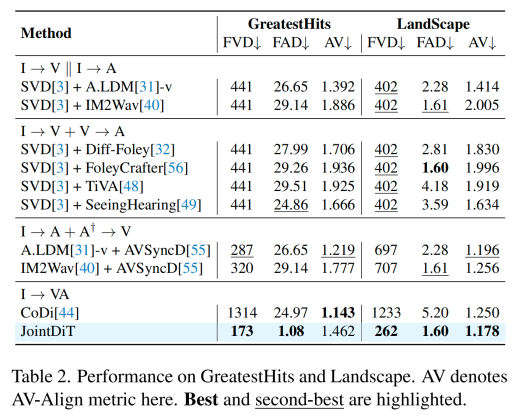
研究团队在三个标准数据集(AVSync15、Landscape 和 GreatestHits)上进行了大量测试,从视频质量、音频质量、同步性和语义一致性四个维度全面评估。
结果显示,JointDiT 在视频质量与音频自然度方面均实现显著提升,FVD、FAD 等核心指标全面优于基于 pipeline 组合的多阶段方法。音视频同步性表现优异,在自动评价指标上与当前最强的音频驱动视频生成模型持平。语义匹配也更为精准,视频画面与声音的「含义」更加契合。
相比之下,诸如 CogVideoX、HunyuanVideo 等文本驱动的大模型,虽然具备强大的生成能力,但由于依赖图片生成文本描述(caption)作为中介,过程中伴随大量视觉信号丢失,导致最终画面和输入图片匹配度(如 FVD、IB-IV 指标)表现不如直接采用图像生成音视频的 JointDiT。事实表明,直接建模图像到音视频的统一路径,能更有效保留原始视觉信息,生成结果更加真实一致。
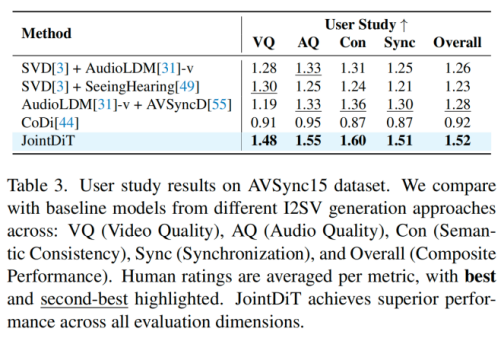
在用户主观打分测试中,JointDiT 在「视频质量」、「音频质量」、「语义一致性」、「同步性」与「整体效果」五项评分中均排名第一,领先第二名近 20%。
一张图生成动态有声视频,背后竟有这么多玄机?
我们以四个生成案例为例(输入图像均作为视频首帧):
案例 1:手指演奏画面中是一根手指搭在吹奏的小号上,生成的视频中指头轻微颤动,音频同步响起清脆的拨弦音,仿佛看见了真实演奏。
案例 2:棍击物体输入图像中,一只手正握着棍子对准物体。JointDiT 生成的视频中,棍子精准敲击目标,画面同步传来清脆的敲击声,声音的质感还根据被敲物体的材质发生变化,真实自然,打击感十足。
案例 3:保龄球击瓶静态图中是一颗保龄球朝瓶子方向滚动。生成视频中,保龄球沿轨道前行,撞击瓶子时发出「砰」的撞击声,瓶子倾倒时伴随一连串碰撞与倒地声,整个过程视听同步、节奏自然,细节丰富,极具临场感。
案例 4:闪电雷鸣输入图像为乌云密布的天空。JointDiT 生成的视频中,一道闪电划破长空,紧接着传来低沉有力的雷鸣声,电光与声响之间保留自然的时间延迟,模拟真实物理世界中的视听顺序,带来逼真的沉浸式体验。
结语与展望
JointDiT 的提出,不仅是一次生成技术的突破,更彰显了 AI 向多模态统一建模演进的趋势。它不仅可应用于娱乐内容创作、影视制作等实际场景,也为多模态通用模型乃至「世界模型」的研究提供了新的思路与启发。接下来,研究团队计划将 JointDiT 扩展至图像、文本、音频、视频四模态的联合建模,为构建更通用、更智能的多模态生成系统奠定基础。
未来,或许我们只需一张照片、一段文字,就能完整听到看到它讲述的故事。
如需了解更多技术细节与案例演示,请访问官方 Demo 页,论文、代码和模型将近期公开,敬请期待!

©
(文:机器之心)