学术


参数减少99.5%,媲美全精度FLUX!字节跳动等发布首个1.58-bit FLUX量化模型

通过1.58-bit FLUX量化模型,显著降低了存储需求和推理内存,同时保持与全精度FLUX相当的性能,在文本生成图像基准测试中表现出色。
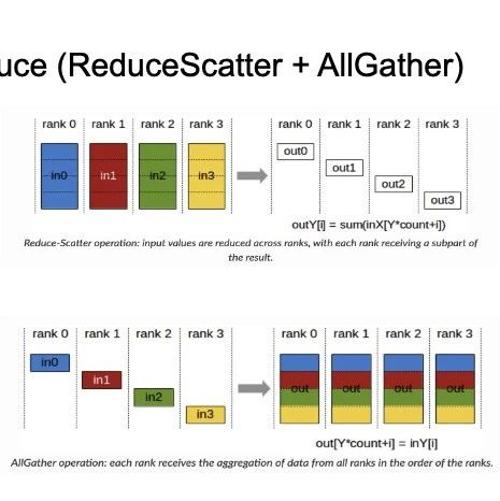
AAAI 2025 SparseViT:参数高效的稀疏化视觉Transformer
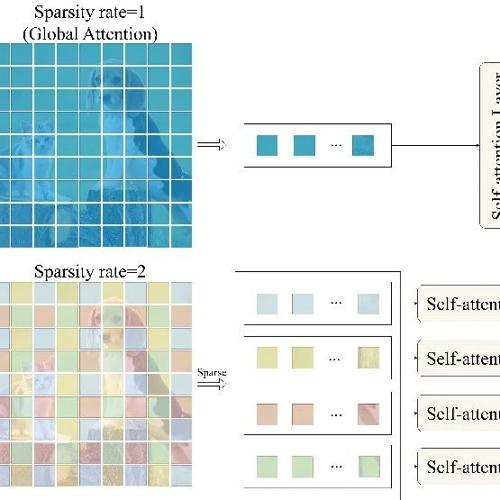
四川大学吕建成团队与澳门大学合作提出SparseViT,这是一种针对图像篡改检测的稀疏化视觉Transformer。通过稀疏自注意力机制和可学习的多尺度监督机制,实现了对非语义特征的自适应提取,并在多个基准数据集上展现了卓越性能。
理解生成协同促进?华为诺亚提出ILLUME,15M数据实现多模态理解生成一体化

华为诺亚方舟实验室提出统一多模态大模型ILLUME,仅使用约15M图文对数据实现视觉理解、生成等任务的出色表现,并采用自提升式多模态对齐策略促进理解和生成能力协同进化。

AI教父、诺奖得主Hinton支持起诉OpenAI,阻止「转营利」

OpenAI计划拆分为营利机构和非营利机构引发争议,马斯克起诉阻止其转型。青年倡导组织Encode支持马斯克的诉讼请求,认为此举将破坏OpenAI以安全和技术造福公众的使命。