
学术





ICLR 2025 比MoE快6倍,成本暴降83%!字节发布超稀疏架构UltraMem

文章介绍了字节跳动豆包大模型团队提出的新稀疏模型架构 UltraMem,该架构有效解决了 MoE 推理时高额的访存问题,推理速度提升2-6倍,成本降低83%。
第二十四届中国计算语言学大会(CCL 2025)征稿启事

MLNLP社区是国内外知名的机器学习与自然语言处理社区,CCL 2025将于8月在山东济南举行,聚焦计算语言学最新学术和技术成果。会议征集原创研究和应用论文,接收中文和英文投稿,并提供多种期刊发表机会。


仅128个token达到ImageNet生成SOTA性能!MAETok:有效的扩散模型的关键是什么?
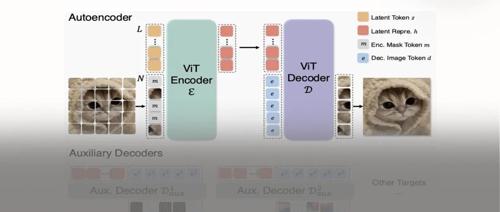
ETok在仅使用128个token的情况下,于256×256和512×512分辨率的ImageNet