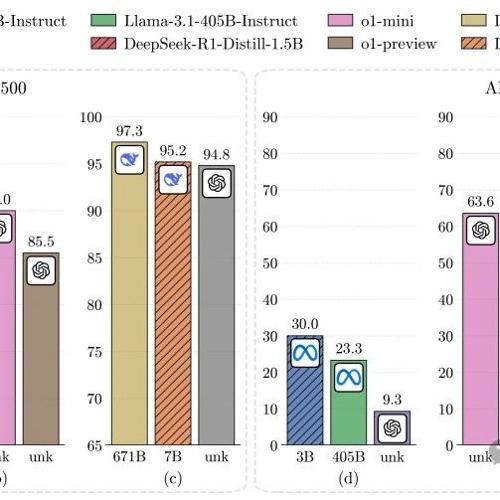
哥德尔-Prover超过DeepSeek-Prover,陈丹琦团队造出当前最强形式化推理模型
近日,普林斯顿大学团队开源了用于自动定理证明的形式化推理模型Goedel-Prover,并在数学问题的自动形式化证明生成任务上达到了SOTA。该模型利用大规模形式化定理数据集和专家迭代方法训练,提高了解题正确率并在排行榜中取得优异成绩。
近日,普林斯顿大学团队开源了用于自动定理证明的形式化推理模型Goedel-Prover,并在数学问题的自动形式化证明生成任务上达到了SOTA。该模型利用大规模形式化定理数据集和专家迭代方法训练,提高了解题正确率并在排行榜中取得优异成绩。

X-R1 是一个低成本且易入门的强化学习训练框架,旨在降低 R1 的复现门槛。通过使用0.5B预训练模型,在4张3090/4090显卡上仅需2小时就实现了 ‘aha Moment’,展示了极小模型也能触发Aha Moment的现象。

奥特曼在推文中公布了OpenAI的产品路线图,强调将发布GPT-4.5和未来的GPT-5模型,并将其与多种技术整合到ChatGPT和API中。

HyperAI超神经上线一键部署DeepSeek-R1-70B教程,帮助用户告别服务器繁忙问题。教程包含详细步骤并提供免费试用资源。

eQuant的后训练量化(PTQ)方法,通过引入等价的仿射变换扩展了优化范围,显著降低了量化误差,尤

DeepScaleR-1.5B-Preview 成功复现 Deepseek-R1 的训练方法,成本仅需4500美元。该模型在AIME2024竞赛中超越了O1-Preview,展示了小模型通过强化学习也能实现飞跃的潜力。
大语言模型(LLMs)的注意力头功能与工作机制引起了广泛关注。《Attention Heads of Large Language Models》综述论文整合了现有研究,提出四阶段认知框架和详细分类,并梳理实验方法与评估基准,为LLM可解释性研究提供了系统性的理论支持与实践指导。