
大模型玩不好数独?!Transformer作者初创公司公布排行榜:o3 Mini High“变异数独”正确率仅2.9%
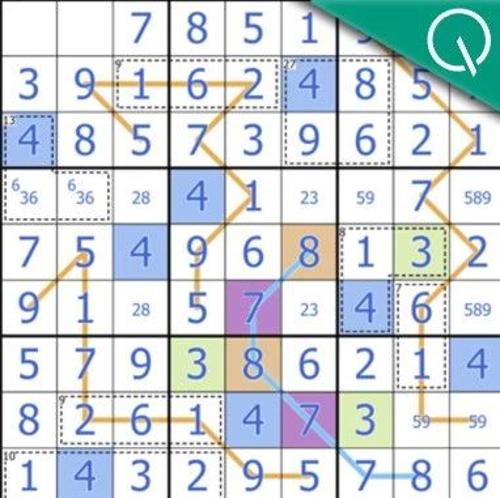
大模型在全新数独基准Sudoku-Bench上的表现不尽如人意,总体正确率低于15%,即使是高性能模型也仅能取得2.9%的正确率。研究团队认为这反映了现有基准测试的问题:大模型容易依赖记忆而非逻辑推理。Sakana AI推出的新基准挑战了这一点,包含复杂且需要多步骤推理的变异数独谜题,展示了AI在创造性和多层次推理上的局限性。
大模型在全新数独基准Sudoku-Bench上的表现不尽如人意,总体正确率低于15%,即使是高性能模型也仅能取得2.9%的正确率。研究团队认为这反映了现有基准测试的问题:大模型容易依赖记忆而非逻辑推理。Sakana AI推出的新基准挑战了这一点,包含复杂且需要多步骤推理的变异数独谜题,展示了AI在创造性和多层次推理上的局限性。

一加Ace5至尊系列发布,配备「电竞三芯」(天玑9400+、灵犀触控芯和电竞Wi-Fi芯片),最高安兔兔跑分3225260,在《王者荣耀》等游戏中的表现优异。此外还提供高刷护眼屏、冰河散热系统等多项改进,旨在提升游戏体验。

蚂蚁发布的大模型开源生态全景图涵盖19个技术领域、135个项目,揭示了大模型开发生态的演进规律和当前趋势。报告指出模型训练框架、高效推理引擎和低代码应用开发框架是主导赛道,并分析了智能体开发方式的变化及标准化协议的重要性。

清华大学等机构联合发布RBench-V,评估大模型的视觉推理能力。结果显示表现最好的模型o3准确率仅为25.8%,远低于人类的82.3%。论文在Reddit机器学习社区引发讨论。

马斯克的星际飞船进行第九次飞行测试遭遇多次失败,包括舱门无法打开、轨道失控和解体等问题。尽管有改进措施,但最终仍以失败告终,SpaceX确认飞船‘快速非计划解体’。

香港大学和密歇根大学的研究人员发布首个专门面向多模态大模型物理推理能力的大规模基准测试PhyX,评估结果表明表现最好的GPT-o4 mini准确率仅为45.8%,远不及人类水平。

MiniMax提出的新框架V-Triune能够实现视觉任务的统一强化学习,通过三层组件设计和动态IoU奖励机制弥补了传统RL方法无法兼顾多重任务的空白。

复旦大学余海洋与字节的研究人员提出CAR自适应推理框架,根据模型困惑度动态选择短回答或长文本推理,在多模态视觉问答和关键信息提取任务中实现最佳平衡。

