
 PaperAgent
PaperAgent

DeepSeek知识库,持续更新!免费领取!

国产大模型 DeepSeek 成为高频关键词,帮助职场人提升效率和创造价值。精心整理的『DeepSeek 知识库』涵盖最新资讯、技术文档等资源,助力快速上手。
让RAG更聪明,通义实验室ViDoRAG开启视觉文档检索增强生成新范式,重塑大规模文档集合迭代推理!
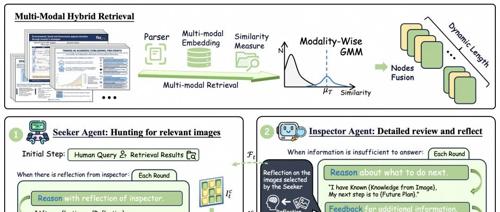
里的精妙布局,再到医疗档案中的多维数据展示,这些富含视觉元素的文档,不仅仅是简单的文字堆砌,而是融合
2025首篇关于多模态大模型在富文本图像理解上的全面研究综述
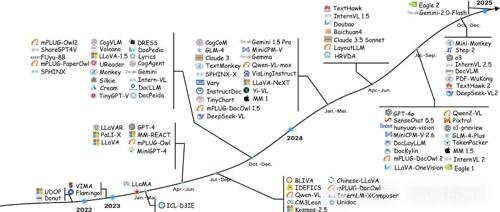
文本丰富的图像理解(TIU)涉及感知和理解两个核心能力。MLLMs通过模态对齐、指令对齐和偏好对齐等方法进行训练,并使用多样化的数据集和基准测试评估性能。

LangGraph全新4大预构建Agents框架登场

LangGraph预构建Agents生态新增5个开源项目:多智能体Swarm、记忆管理库LangMem、工具调用库trustcall以及层次化多智能体系统langgraph-supervisor,支持流式处理、长期记忆管理和复杂JSON结构操作。

聪明人已经抓住DeepSeek风口发表SCI了

科研圈又有新进展!意大利研究团队借助DeepSeek模型在知名期刊发表论文,从投稿到接收仅用一天。清华大学出版《DeepSeek:从入门到精通》,详细介绍这一深度学习和人工智能工具的使用方法。此外,还有大模型实战系列课和华为全联接大会上的大模型免费试用机会。