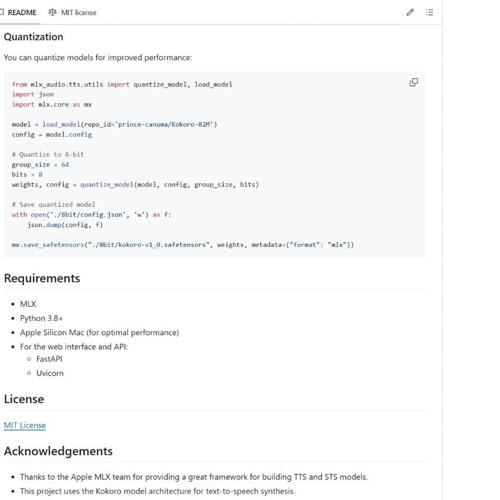
探索LLM如何捕捉和表征领域特定知识
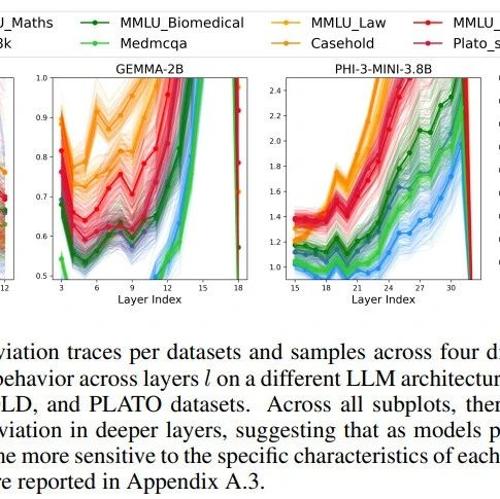
本文揭示了大型语言模型在预填充阶段的隐藏状态中内在地编码了领域特定知识,并提出了一种利用这些轨迹进行查询路由的模型选择策略,显著提高了性能特别是开放式生成任务的表现。
本文揭示了大型语言模型在预填充阶段的隐藏状态中内在地编码了领域特定知识,并提出了一种利用这些轨迹进行查询路由的模型选择策略,显著提高了性能特别是开放式生成任务的表现。
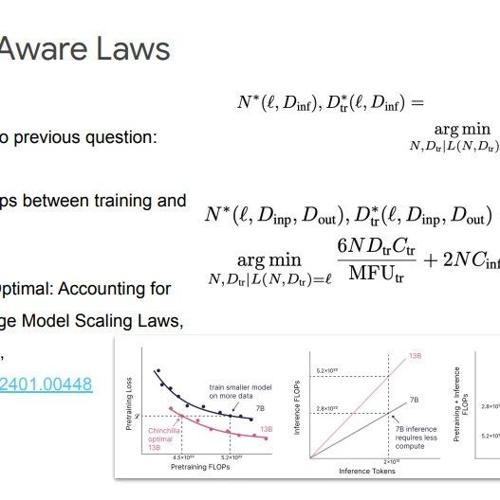
DeepMind专家Vlad Feinberg在普林斯顿的演讲中讨论了模型规模扩展法则的历史、优化策略及未来研究方向,强调小模型客户需求、推理感知扩展法则,并建议开发硬件专用内核和改进量化技术。

微软推出免费生成式AI入门课程,涵盖基础原理到实战项目全流程,支持Python和TypeScript编程语言,还提供后续对接服务、官方社群交流等资源。

研究人员提出TokenShuffle方法显著减少多模态大语言模型中的视觉token数量,提高效率并促进高质量图像生成,超越同类自回归和强扩散模型。

基于DeepSeek-R1微调的DeepSeek-R1T-Chimera模型在保持性能的同时显著缩短了思考时间,可作为DeepSeek-R1的加强版使用。
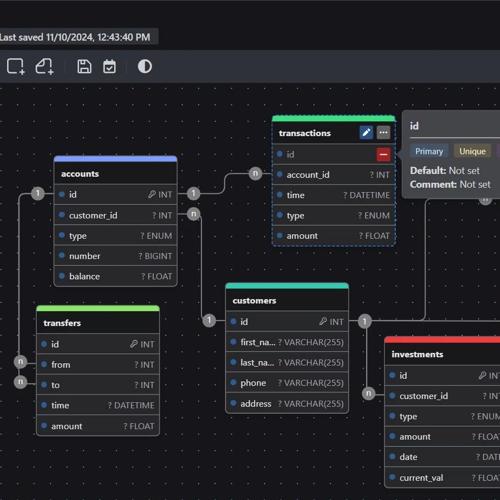
数据库实体关系(DBER)编辑器——drawDB支持可视化编辑库表结构与关系,并可导入现有库表进行梳理,同时具备AI生成SQL功能,部署方便,基于网页应用。