AI工程化
AI工程化

OpenAI发力AI应用!前Meta产品总裁将任应用部门CEO

Sam Altman宣布任命Fidgi Simo为新设立的应用部门CEO,Simo曾是Instacart的CEO,此次调整旨在整合公司业务并推动规模化扩张。
变天了!WindSurf推出workflow功能,低代码大模型应用开发平台将面对“降维”打击
Windsurf在1.8.2版本中推出Workflows功能,采用自然语言方式定义工作流并深度集成IDE,相比过去编排工具更具优势。
“煽风点火”让大模型“卷”起来的提升性能的套路

近日,一名网友分享了一种通过巧妙利用不同AI模型之间的‘竞争’心理来提升AI输出效果的方法,具体步骤包括:选择任务→交给第一个AI(如ChatGPT)→将结果复制粘贴给第二个AI(如Claude),并要求其改进表现→再继续挑战第三个AI(如Grok)。这种方法已经得到了很多网友的验证和认可。
Infinite Retrieval:不用RAG也无需长上下文模型就能实现无限上下文检索的新方法!
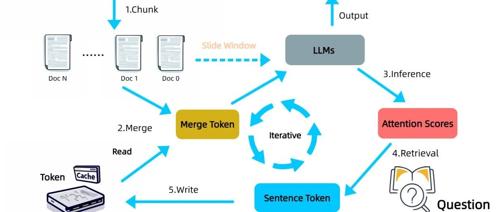
处理超长文本一直是大模型的挑战,《Infinite Retrieval》提出无需额外训练的方法,利用LLM注意力机制进行信息检索,实现理论上的无限上下文长度。
20家单位参与,《面向人工智能的数据标注合规指南》征集中

阿里开源的Qwen2.5系列训练数据规模达到18万亿token,远超其他模型。然而,这带来幻象问题的风险促使RAG技术及企业专有知识数据的价值提升,强调了数据采集、标注和管理的重要性。政策层面,《关于促进数据标注产业高质量发展的实施意见》发布,进一步推动数据标注产业发展。《标准》旨在解决数据标注中的合规问题,提高行业规范化发展水平。
刚刚!Karpathy又分享了有关“Vibe编程”的心得!

Andrej Karpathy 提出’Vibe Coding’,这是一种针对AI时代的新型编程范式。通过提供完整上下文和明确需求,AI能够生成更准确的代码。此过程中需要人工审查与测试以确保质量,并强调持续迭代开发。
METR发现 AI 编码的“摩尔定律”?指数级增长或颠覆软件开发
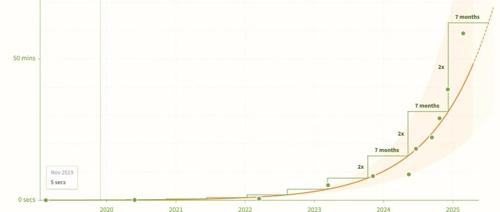
文章概述了AI系统处理编码任务的能力以指数速度增长,METR机构的最新研究显示,在2019到2025年间,AI能完成的任务时长上限几乎每7个月翻一番。未来预测指出,AI可能在几年内就能完成数周乃至一个月的工作。
大模型靠强化学习就能无限变强?清华泼了一盆冷水
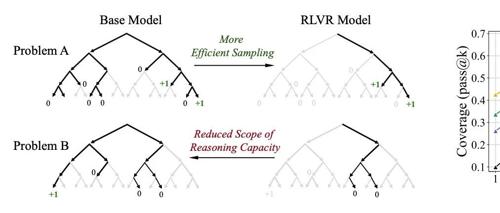
清华大学研究指出,强化学习虽能提升大模型在特定任务上的表现,但可能并未拓展其整体推理能力边界。研究通过pass@k评估发现基础模型在高尝试机会下也能追上甚至超越经过强化学习训练的模型。这表明当前RL技术主要提升的是采样效率而非新解法生成。