DeepEval:LLM 应用评测不再玄学,让大模型评测像写单元测试一样简单
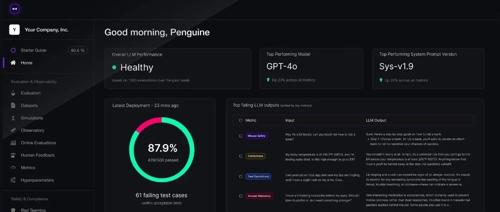
在大模型应用开发中,DeepEval 提供了一个自动化和标准化的LLM评测框架,支持本地运行,并且集成于多种LLM应用开发框架中。它内置了多种主流的评测指标,能够满足实际场景需求,并支持批量数据集评测和组件级追踪。
在大模型应用开发中,DeepEval 提供了一个自动化和标准化的LLM评测框架,支持本地运行,并且集成于多种LLM应用开发框架中。它内置了多种主流的评测指标,能够满足实际场景需求,并支持批量数据集评测和组件级追踪。

Memvid开源项目通过将文本数据存入视频文件,解决传统向量数据库高昂成本和复杂部署问题,提供高效、经济且便携的文本存储与检索解决方案。

DeepSeek R1 模型完成小版本升级至 0528 版本。新增深度思考功能,提升了数学、编程和逻辑推理能力,在多个基准测评中表现优异,并针对幻觉问题进行了优化。

ACI.dev 是一个开源项目,旨在为AI Agent提供标准化基础设施,简化其与大量外部工具的集成、认证和权限管理过程。它通过广泛的工具集成、统一的认证授权机制、多样化的接入方式(包括直接函数调用和统一MCP服务器)来解决复杂环境中的交互问题。
LangChain创始人Harrison Chase在Interrupt大会上发表了主题演讲,指出AI行业面临的痛点是将大模型转化成可靠应用的困难。他提出智能体工程师需要掌握提示工程、工程能力、产品思维和机器学习知识,并分享了LangChain对智能体开发的洞察与策略预判。
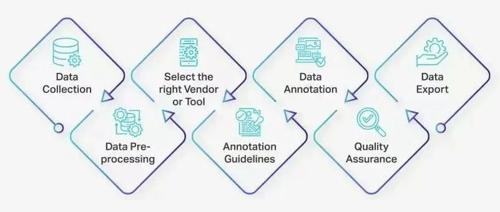
数据标注作为训练大模型的重要环节,直接影响机器学习的性能。为解决合规问题,智合标准中心启动了《面向人工智能的数据标注合规指南》团体标准研制工作,并邀请多方参与制定。
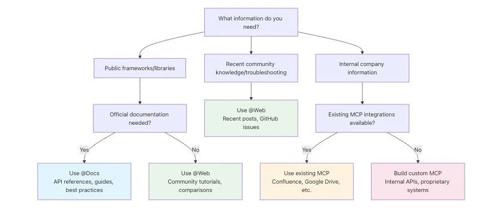
有效利用各类文档资源是克服大模型编程挑战的关键。Cursor 提供的三个工具 (@Docs、@Web 和 MCP) 通过直接访问官方文档、互联网资源和企业内部文档,帮助开发者为 AI 提供精准上下文,从而提升代码生成的质量。
Anthropic 推出的新一代 Claude 模型包括 Claude Opus 4 和 Claude Sonnet 4,在编码、推理和 AI Agent 方面达到新标准,并提供混合模型的两种模式:近乎即时响应和用于深度推理的扩展思维功能。