

OpenAI 开源模型意外泄露!
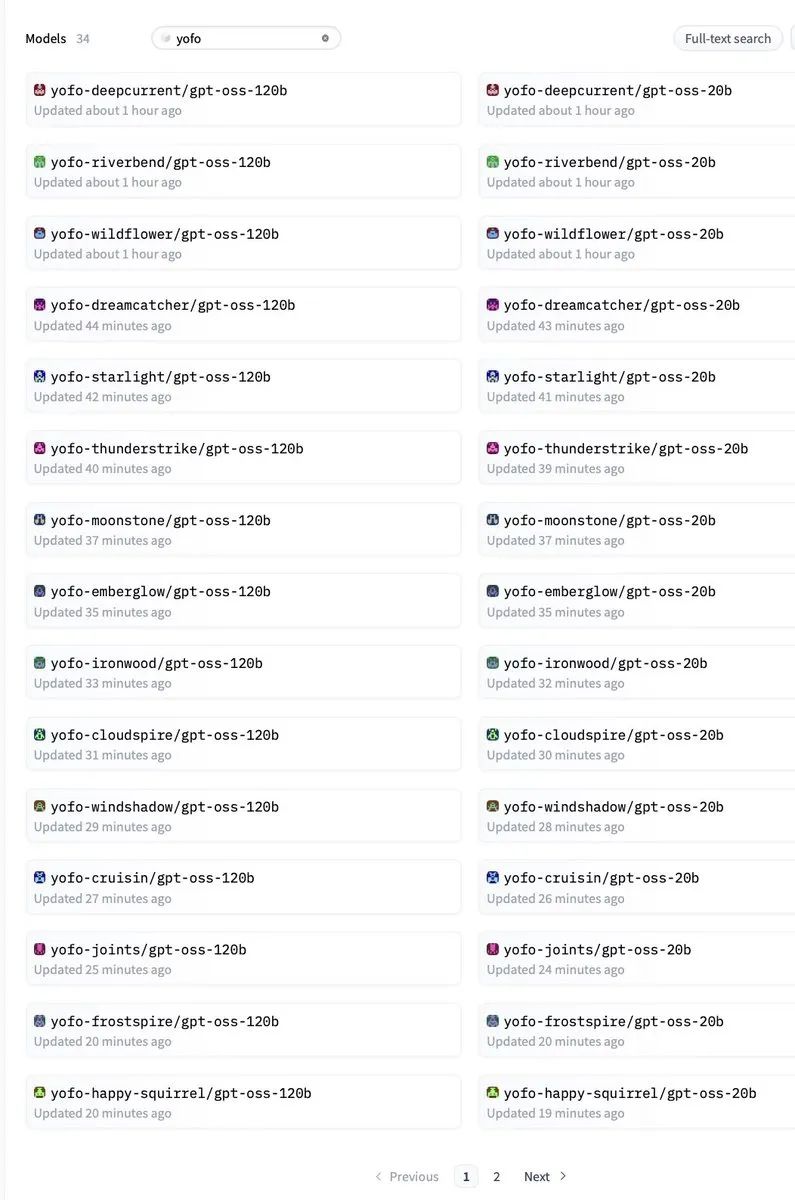
刚刚,有人在 Hugging Face 上发现了 OpenAI 悄悄上传的开源模型仓库,虽然很快就被删除了,但还是有眼疾手快的网友抢先保存了配置文件和相关信息。
这次泄露的主角叫做 gpt-oss-120b,从命名就能看出这是一个 120B 参数的模型。
更有意思的是,这似乎是一个模型家族,除了 120B 的大模型,还有一个 20B 的版本。
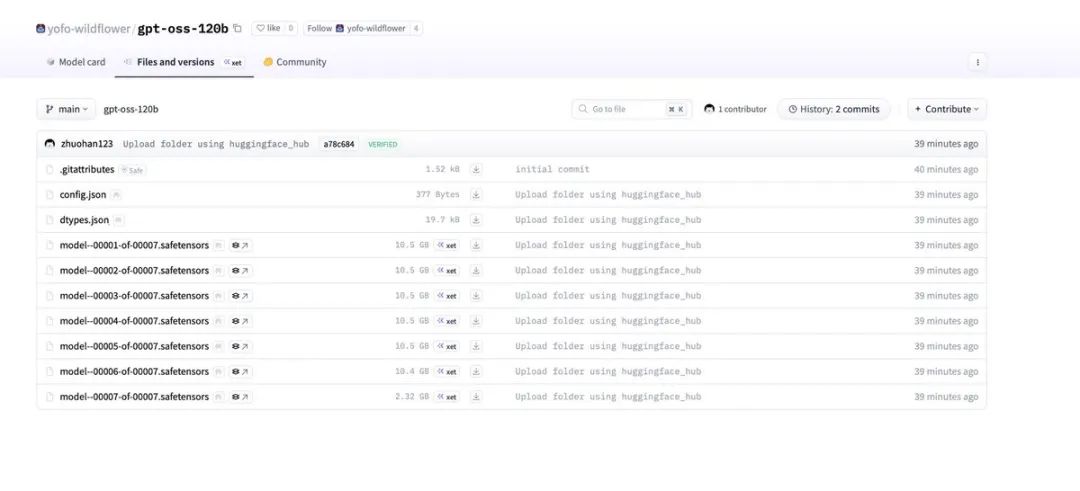
Jimmy Apples(@apples_jimmy) 第一时间发现并保存了这些信息:
我在他们上传后一分钟就发现了 OAI 的 OS 模型,并在删除前保存了配置和其他内容。这是个 OS 模型,即将推出,感觉有点像剧透了一个惊喜。

随后他公开了模型的配置信息:
{
"num_hidden_layers": 36,
"num_experts": 128,
"experts_per_token": 4,
"vocab_size": 201088,
"hidden_size": 2880,
"intermediate_size": 2880,
"swiglu_limit": 7.0,
"head_dim": 64,
"num_attention_heads": 64,
"num_key_value_heads": 8,
"sliding_window": 128,
"initial_context_length": 4096,
"rope_theta": 150000,
"rope_scaling_factor": 32.0,
"rope_ntk_alpha": 1,
"rope_ntk_beta": 32
}
从配置文件可以看出,这是一个 MoE(混合专家)架构的模型,拥有 128 个专家,每个 token 激活 4 个专家。
初始上下文长度为 4096,但通过 RoPE scaling 可以扩展到更长。
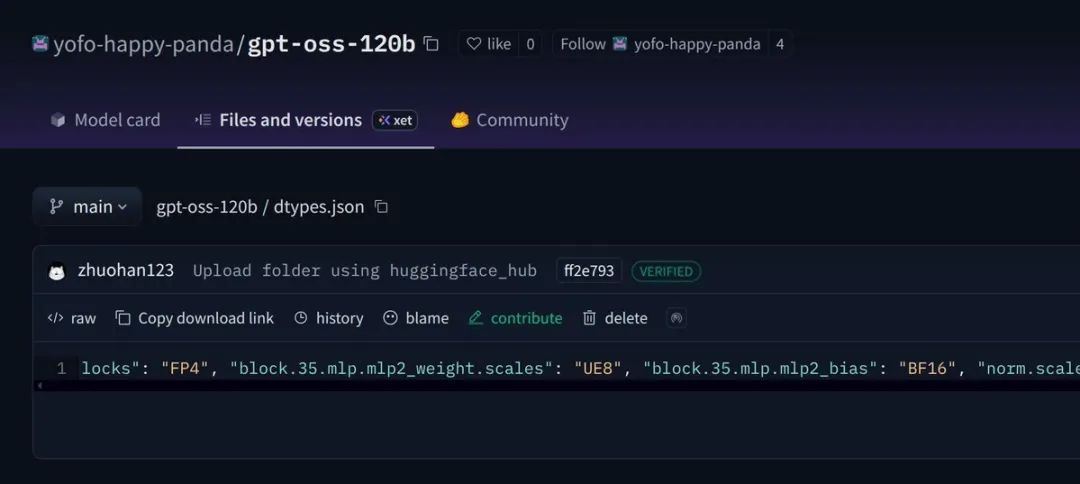
Mark Kretschmann(@mark_k) 也确认了这个发现:
OpenAI 开源模型找到了!名称:gpt-oss-120b,大小:120b,发布日期:今天!

不过让人怀疑的是,文件大小引起了一些讨论。
Harsh Nigam(@nigharsh) 提出疑问:
120b 模型只有约 65GB?感觉有些不对劲。
对此,Blaž Bizjak(@bizjakblaz93) 解释道:
不,我认为那是 VRAM 使用量。文件大小通常是每 1B 参数约 1GB。
zipperlein(@iamzipperlein) 则推测:
约 65.3GB 可能是 FP4/AWQ 量化版本。
Luke Chaj(@luke_chaj) 询问配置文件中是否有关于 MoE 架构和激活专家数的信息,而 Jimmy 随后公开的配置正好回答了这个问题。
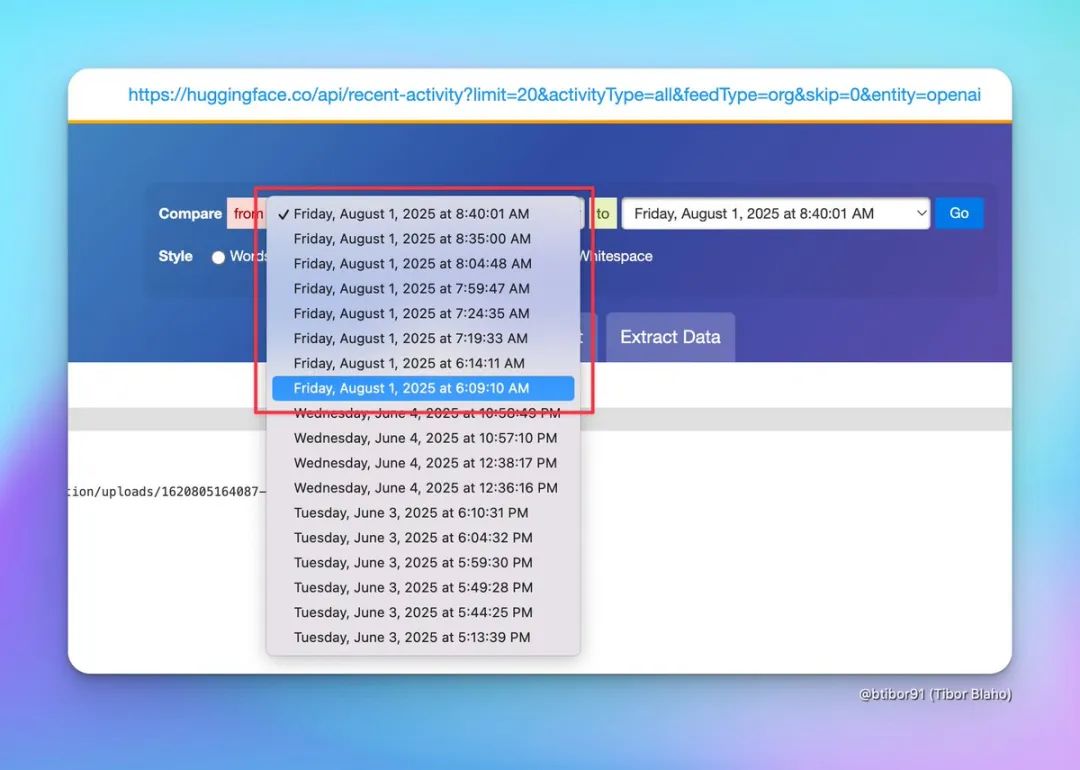
Tibor Blaho(@btibor91) 分享了他的网页监控工具截图:
我就知道有事情要发生,早上醒来就看到了这些警报。
关于模型的用途,有人猜测这可能是为了在消费级硬件甚至手机上运行而设计的,毕竟Sam Altman 先前曾有过关于端侧模型的问卷。
Shman(@TheShmanuel) 问道:
这应该能在手机上运行吗?
InfiniteHexx(@InfiniteHexx) 则调侃道:
Dario 刚好很方便地贬低了开源模型,不是吗?
这次意外泄露让 AI 社区既兴奋又好奇。
prosight(@thgisorp) 分析指出:
我计算了一下,OpenRouter 上的 OpenAI 模型似乎不是这个模型,因为上下文长度与 Horizon Alpha 的 256K 不匹配。除非是 20B 版本……但我预期它们会共享相同的上下文大小。

虽然目前仅为传言,但可以断定的是,OpenAI 选择开源不论放出的是个什么模型,都一定会是个值得重点关注和庆祝的时刻。
但这样似有意又无意的「意外泄露」的方式,反而给这个消息增加了更多神秘色彩。
Gareth Manning(@worldteacherman) 开玩笑说:
Jimmy 毁了圣诞节。
如果 OpenAI 真的要开源这些模型,那或将是继中国一众开源力量之后的又一个重要的里程碑。
但这120B 的参数量,MoE 架构,可能的移动端部署究竟能有多重——
咱就还是谨慎吃瓜,拭目以待了。
(文:AGI Hunt)