

📢本周AI快讯 | 1分钟速览🚀
1️⃣ 🧠 阿里 Qwen3 全系列爆发 :一周内密集发布四款新模型,包括 Qwen3-235B-A22B-Thinking-2507、Qwen3-Coder 和 Qwen3-MT,MMLU-Pro 成绩超越 Claude Opus 4,百万 token 仅 2 元。
2️⃣ 🛠️ 字节跳动 Coze 全面开源 :AI Agent 平台“扣子”(Coze)采用 Apache 2.0 协议开源,仅需 2 核 CPU 和 4GB 内存即可运行,含 Coze Studio 和 Coze Loop 两大核心项目。
3️⃣ 💻 通义灵码接入 Qwen3-Coder :阿里 AI 编程助手全面免费不限量,480B 参数激活 35B 的 MoE 架构,支持 256K token 上下文,性能直逼 Claude Sonnet 4。
4️⃣ 🎯 腾讯 CodeBuddy IDE 发布 :首个全栈 AI IDE,覆盖“产品-设计-研发-部署”全流程,内置 Claude-4.0-Sonnet 和 Gemini-2.5-Pro,从想法到上线一步到位。
5️⃣ 🚀 阶跃星辰 Step 3 开源 :321B 参数 MoE 模型,推理效率达 DeepSeek-R1 的 300%,联合华为等成立”模芯生态创新联盟”,打通模型-芯片-应用全链路。
6️⃣ 🎯 讯飞星火 X1 升级版 :基于全国产算力训练,对标 OpenAI o3,支持 130 余种语言,仅需 4 张华为 910B 算力卡即可运行。
7️⃣ 🧩 快手 KAT-V1 开源 :40B 参数推理模型,解决”过度思考”问题,token 使用量降低 30%,LiveCodeBench Pro 测试超越 o3-mini。
8️⃣ ✨ GitHub Spark 公测启动 :基于 Claude Sonnet 4 驱动,一句话生成全栈应用并一键部署,需订阅 Copilot Pro+(39 美元/月)。
9️⃣ 🎨 谷歌 Opal 无代码工具 :面向美国用户公测,自然语言生成网页应用,支持可视化编辑和一键发布,主打”氛围编程”概念。
1️⃣0️⃣ 🔥 OpenAI GPT-5 即将发布 :计划 8 月初推出标准版、mini 版和 nano 版,首次融合传统 GPT 与推理 o 系列能力于单一系统。
1️⃣1️⃣ 🏆 谷歌 Gemini 获 IMO 金牌 :国际数学奥赛 6 道题解决 5 道,得分 35/42,采用自然语言直接生成数学证明,4.5 小时内完成。
01|阿里 Qwen3 系列密集发布,通用到垂直全覆盖
本周,阿里通义千问团队开启“高产模式”,密集发布并开源了四款 Qwen3 系列新模型,全面覆盖从通用智能到垂直应用场景。其中,旗舰基础模型包括擅长复杂推理任务的 Qwen3-235B-A22B-Thinking-2507 以及专注高效执行与人类对齐的 Qwen3-235B-A22B-Instruct-2507,后者在 MMLU-Pro 基准测试中的成绩飙升至 83.0,甚至超越了 Claude Opus 4 和 Kimi K2。此外,专注代码生成的 Qwen3-Coder 和支持 92 种语言互译的 Qwen3-MT 也同步亮相,形成了“理解-执行-表达”的完整模型布局。
值得关注的是,阿里重新定义了“思考模式”模型,将原有的混合架构拆分为“推理型”(Thinking)和“指令型”(Instruct)两个独立版本,精准满足了不同应用场景的需求。此外,Qwen3-MT 在覆盖全球 95% 人口语言的同时,API 成本更低至百万 token 仅 2 元人民币,极具市场竞争力。这种全面而立体的产品矩阵不仅体现了阿里在 AI 大模型领域的领先实力,也标志着国产 AI 正从单点突破迈入生态竞争的新阶段。
02|字节跳动全面开源 Coze,AI Agent 开发迎来新拐点
7 月 26 日,字节跳动正式宣布将旗下 AI Agent 开发平台“扣子”(Coze)全面开源,包括 Coze Studio 和 Coze Loop 两大核心项目。本次开源采用极为宽松的 Apache 2.0 协议,允许任何个人与企业自由使用、修改,甚至商业化部署。尤其值得注意的是,系统运行的硬件门槛大幅降低,仅需 2 核 CPU 和 4 GB 内存即可,配合一键部署脚本,使 AI Agent 开发真正实现了“人人可用”。

从技术架构来看,Coze Studio 提供从开发到部署的完整工具链,采用 Golang 微服务架构,在字节内部大量产品中经受验证,特别适合频繁与大模型交互的高性能场景。另一核心组件 Coze Loop 则专注于 AI 智能体的全生命周期管理,从提示词工程到性能监控均覆盖在内。目前,已有上万家企业和数百万开发者正在使用 Coze 平台,此次全面开源无疑将进一步加速 AI Agent 生态的繁荣。
有分析指出,此次开源不仅仅是技术分享,更体现了字节跳动布局 AI Agent 赛道的战略意图。相比 Dify 等开源竞品的商业限制,Coze 更具开放性与包容性,未来极有可能成为 AI Agent 开发领域的行业标准,如同 Docker、Kubernetes 在容器化领域一样。这也预示着 AI Agent 应用有望在开源生态的助推下快速迎来爆发式增长。
03|阿里通义灵码接入 Qwen3-Coder,免费不限量
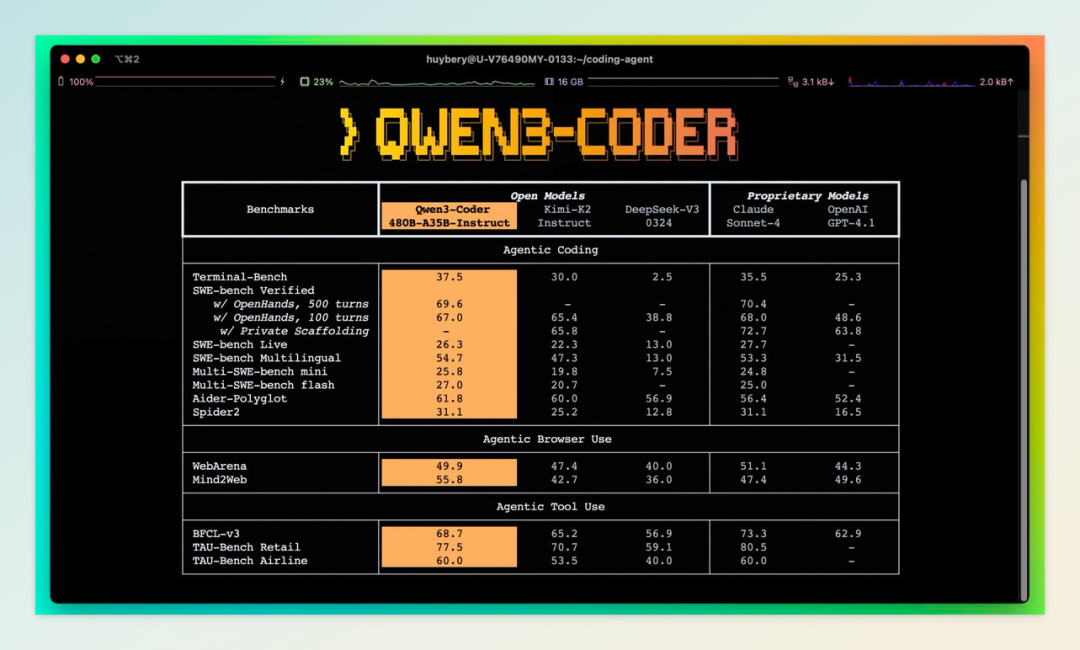
7 月 24 日,阿里云宣布旗下 AI 编程助手“通义灵码”正式全面接入最新开源的代码模型 Qwen3-Coder,即日起在通义灵码 AI IDE、VS Code 和 JetBrains 插件端为全球开发者提供不限量免费服务。
此次接入的最强版本 Qwen3-Coder 采用了 480B 参数激活 35B 参数的 MoE 架构,原生支持 256K token 上下文,扩展后可达 1M token,在 Agentic Coding 等关键指标中达到开源模型 SOTA 水平,性能直逼 Claude Sonnet 4,在部分任务上甚至实现了反超。得益于此,初级程序员的工作效率大幅提升至资深程序员的 5 倍,生成一个完整品牌官网最快只需 5 分钟。
效率提升引发了全球开发者社区的热烈反响,Hugging Face CEO 克莱门特·德朗格直言“这真有趣”,知名风投 a16z 合伙人马克·马斯克罗更是评价其“几乎与 Claude 4 一样厉害”。目前,通义灵码插件累计下载量已超 2000 万次,生成代码超过 30 亿行,成为国内最受欢迎的编程辅助工具,一汽集团、蔚来汽车等上万家企业均已接入使用。
04|腾讯发布全栈 AI IDE CodeBuddy,从想法到上线一步到位
7 月 22 日,腾讯正式发布旗下首个全栈 AI IDE 产品 CodeBuddy IDE,定位为覆盖“产品-设计-研发-部署”全流程的 AI 一站式开发工作台。与传统 AI 编程助手专注代码生成不同,CodeBuddy IDE 整合了产品经理、设计师、开发者三大角色的工作流程,用户仅需用自然语言描述需求,即可自动生成 PRD 文档、交互原型、前后端代码,甚至实现一键部署上线。国际版内置了 Claude-4.0-Sonnet 和 Gemini-2.5-Pro 等顶级模型,国内版则全面接入腾讯混元、DeepSeek 等国产大模型。

在技术架构上,CodeBuddy IDE 通过四大智能体完整覆盖开发全流程:Plan Agent 负责需求拆解与产品规划;Design Agent 基于 DSL 语言生成可直接修改的交互设计稿;Coding Agent 支持从 Figma 设计稿一键生成高质量前端代码;而 Deploy Agent 则提供与 Supabase、腾讯云 TCB 等平台的无缝集成,真正实现了一键上线。此外,该 IDE 还兼容 MCP(Model Control Protocol)协议,方便开发者自定义扩展更多功能。
腾讯云表示,未来 AI 编程将分化为“氛围编程”(适合快速实现简单应用)和“规约编程”(适合复杂系统的专业协作)两种模式,CodeBuddy IDE 正好满足了这两种范式融合的需求。目前该产品处于内测阶段,需邀请码激活,内测期间提供 Pro 版权益与高级模型额度。这类 AI 产品将极大缩短产品从构想到落地的周期,对独立开发者、创业团队及非技术背景的产品经理来说,或将成为快速验证产品想法的重要工具。
05|阶跃星辰发布 Step 3 大模型,牵头成立国产芯片联盟
7 月 25 日,阶跃星辰在世界人工智能大会(WAIC 2025)开幕前夕正式发布新一代基础大模型 Step 3,并宣布将于 7 月 31 日向全球开发者开源。作为该公司首个全尺寸原生多模态推理模型,Step 3 采用 MoE 架构,总参数量达 321B,激活参数 38B,在 MMMU、MathVision、AIME 2025 等国际多模态基准测试中均实现开源模型 SOTA 成绩,推理效率更高达 DeepSeek-R1 的 300%。

除了技术创新,更值得关注的是阶跃星辰联合华为昇腾、沐曦、壁仞科技、燧原科技、天数智芯、寒武纪、摩尔线程等近 10 家国产芯片巨头,共同成立“模芯生态创新联盟”。目前,华为昇腾芯片已率先完成对 Step 3 的适配运行,其他成员企业的适配也在同步推进中。这是国内首次由模型企业牵头,打通“模型-芯片-应用”全链路生态,预示着国产 AI 正式进入协同发展的新时代。
据阶跃星辰 CEO 姜大昕透露,得益于上半年业务高速增长,公司今年营收目标已提升至 10 亿元。目前,Step 系列大模型已广泛应用于汽车、具身智能、物联网领域,超过半数的国产头部手机品牌均与阶跃星辰展开 AI 智能体合作。
06|讯飞星火 X1 升级版发布,国产算力对标 OpenAI o3
7 月 25 日,科大讯飞正式发布深度推理大模型讯飞星火 X1 升级版。据官方介绍,新版本基于全国产算力训练,在翻译、推理、文本生成、数学推理等任务上可对标 OpenAI o3,多语言支持扩展至 130 余种。值得关注的是,新版模型针对大模型幻觉问题进行了重点优化,在事实性幻觉和忠实性幻觉治理两方面均取得明显改善。
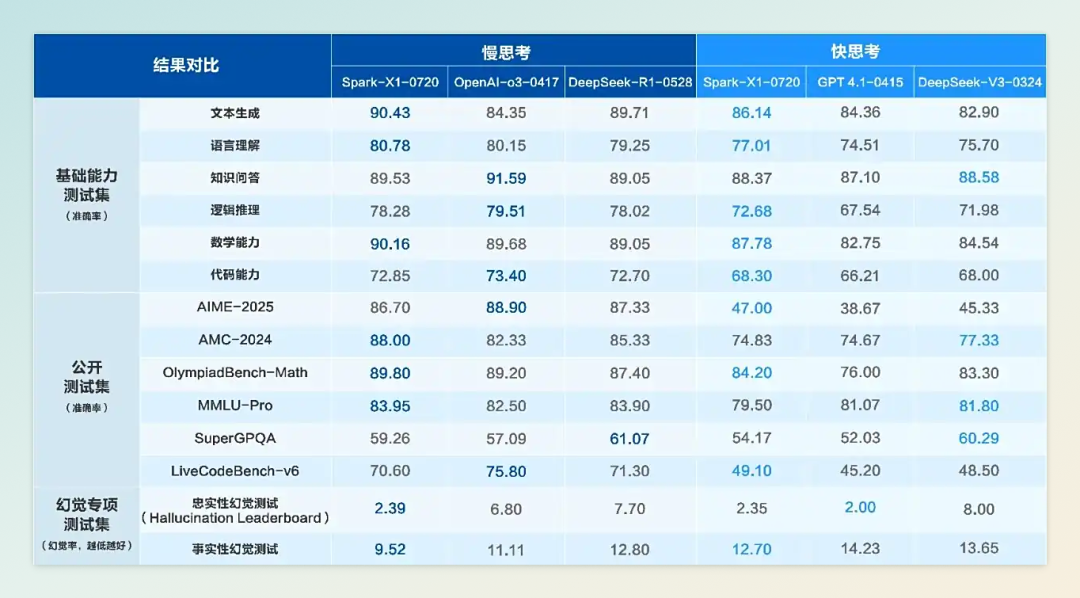
具体应用场景方面,基于星火 X1 的语音同传大模型翻译质量较半年前提升 20%,专业词汇覆盖达 8 万余个,尤其在医疗和教育等讯飞传统优势领域的表现进一步加强。此外,该模型支持“快思考-慢思考”统一架构,官方表示仅需 4 张华为 910B 算力卡即可完整运行,大幅降低了企业进行私有化部署的硬件成本。
07|快手开源推理模型 KAT-V1,40B 性能直逼 R1-0528
7 月 21 日,快手正式开源自研大语言推理模型 Kwaipilot-AutoThink(KAT-V1),专门解决当前推理模型普遍存在的“过度思考”问题。这款拥有 40B 参数的模型采用独创的“自动思考”训练范式,能够根据任务复杂度动态切换推理与非推理模式,在保障任务效果的前提下,可将 token 使用量降低约 30%。在 LiveCodeBench Pro 防泄露基准测试中,KAT-V1 更是超越所有开源模型,表现甚至超过闭源的 Seed 和 o3-mini 模型。
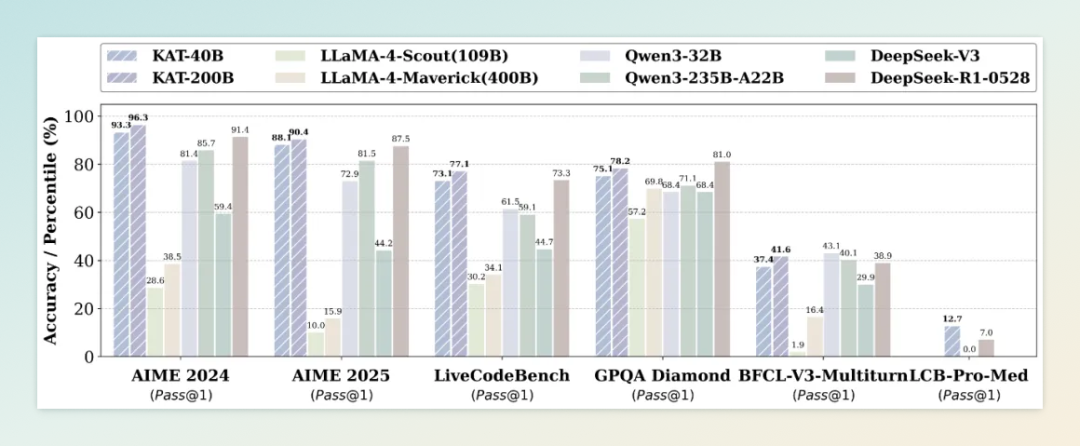
在技术上,KAT-V1 引入了多项创新,包括双模态数据集构建、结合 Multi-Token Prediction(MTP)的知识蒸馏、冷启动初始化策略,以及创新强化学习算法 Step-SRPO。在多个基准测试中,该模型的表现均达到甚至超越当前顶尖模型,如 DeepSeek-R1-0528 和 Qwen3-235B-A22B。
此外,据快手团队透露,目前正积极训练一个规模达 200B 参数的混合专家(MoE)模型,激活参数为 40B,初步测试结果已展现出优异的性能和效率,进一步验证了 AutoThink 训练框架的扩展潜力。
08|GitHub Spark 公测启动,一句话生成全栈应用
7 月 23 日,GitHub 宣布 AI 应用开发平台 GitHub Spark 正式进入公开预览阶段,向所有 Copilot Pro+ 用户开放。该平台以 Claude Sonnet 4 为核心驱动,用户只需用自然语言描述想法,即可在几分钟内自动生成前后端完整的全栈应用,并支持一键部署上线。整个过程无需进行复杂的配置、环境搭建或 API 密钥管理,极大地简化了传统开发流程。
GitHub Spark 的最大亮点在于与 GitHub 生态的深度融合。每个生成的应用都会自动创建对应的 GitHub 仓库,并配置好 GitHub Actions 与 Dependabot,每次修改均自动提交为独立的 commit。此外,用户还能随时在 Codespaces 或本地 VS Code 中继续精细开发,并通过 Copilot 代理模式执行更复杂的编程任务。该平台还内置 OpenAI、Meta、DeepSeek 和 xAI 等多个 AI 模型,无需用户管理 API 密钥即可快速添加智能功能。
业内人士分析,GitHub Spark 的推出标志着 AI 编程真正迈入“氛围编程”(vibe coding)时代。相较于谷歌 Opal 等竞品只能实现简单网页开发,Spark 支持创建完整的全栈应用,并提供从原型到生产的无缝工作流。GitHub CEO Thomas Dohmke 表示,这款产品将帮助实现“让 10 亿人成为开发者”的愿景。目前该服务需订阅 Copilot Pro+(39 美元/月),GitHub 未来计划进一步扩大开放范围。
09|谷歌推出无代码工具 Opal,用自然语言生成网页应用
7 月 24 日,谷歌通过 Google Labs 正式推出实验性 AI 编程工具 Opal,目前已面向美国用户开放公测。该工具聚焦于“氛围编程”(vibe-coding)趋势,用户只需用自然语言描述所需功能,Opal 即可自动生成可视化的应用工作流,并转化为无需编写任何代码即可运行的网页应用。每个工作流步骤均支持点击查看和修改提示词,实现了透明且易用的 AI 构建体验。

Opal 的推出意味着谷歌正式加入了无代码 AI 工具的竞争行列。就在前一天,微软旗下的 GitHub 发布了类似的 Spark 工具,而亚马逊 AWS 的 Kiro、Replit 和 Cursor 等平台也在竞逐这一市场。谷歌强调自身产品的差异化在于强大的视觉化编辑能力和极低的使用门槛,用户可直接从模板库选择并进行“重混”(remix),完成后即可一键发布,通过链接分享即可使用谷歌账号访问应用。
TechCrunch 认为,相较于谷歌现有的开发者工具 AI Studio,Opal 的视觉化界面更显直观,旨在吸引更广泛的用户群体,尤其适合营销、销售等非技术部门快速进行原型搭建、概念验证和生产力工具的创建。
10|OpenAI 预计 8 月初发布 GPT-5,多版本融合推理能力
7 月 25 日,据 The Verge 报道,OpenAI 计划在 8 月初正式推出下一代语言模型 GPT-5。此次发布将包含标准版、mini 版与 nano 版三个版本,其中 nano 版仅通过 API 提供。这一计划原定于今年 5 月,但因额外的安全与性能测试需求而推迟数月。据悉,微软工程师早在 5 月就已开始为 GPT-5 部署服务器容量,发布前期准备已基本完成。

GPT-5 最大的突破在于首次将传统 GPT 模型与推理导向的 o 系列模型(如 o3)能力整合于单一系统。OpenAI CEO Sam Altman 称其为“融合大量技术成果的系统”,目的是简化用户体验,避免在不同模型间频繁切换。本周,Sam Altman 在播客中透露自己曾用 GPT-5 完美解决了一个他无法回答的问题,坦言这一体验令他产生了“奇妙的感觉”。此外,OpenAI 代码库近期也出现了 gpt-5-reasoning-alpha-2025-07-13 等字样,表明模型已进入最终测试阶段。
值得关注的是,OpenAI 此前还计划推出自 2019 年 GPT-2 以来的首个开源权重模型,类似于 o3-mini,将通过 Azure、Hugging Face 等平台提供。同时有消息称,OpenAI 正积极推进视频生成工具 Sora 第二代版本的开发。在谷歌 Gemini 和 Anthropic Claude 等竞争对手高速发展的背景下,GPT-5 的发布被视为 OpenAI 保持行业领先地位的关键布局。
11|继 OpenAI 后,谷歌 Gemini 获国际数学奥赛金牌
7 月 21 日,谷歌 DeepMind 宣布其增强版 Gemini 模型在国际数学奥林匹克竞赛(IMO)测试中斩获金牌成绩,6 道题目成功解决 5 道,总得分 35 分(满分 42 分)。IMO 主席 Gregor Dolinar 教授对此表示肯定:“谷歌 DeepMind 达到了这一重要里程碑,他们的解答清晰、准确,且大部分易于理解。”此前,OpenAI 的实验性推理模型也曾获得相同分数的金牌成绩。

此次 Gemini 模型最大的技术进步在于推理方式的革新。与去年需借助 Lean 等形式化语言、耗时数天才能完成的解题方式不同,今年的 Gemini Deep Think 模型完全采用自然语言,直接基于官方题目描述生成完整而严谨的数学证明,且在规定的 4.5 小时内完成。谷歌 DeepMind 高级研究员 Thang Luong 表示,此次参赛的模型与日常提供给用户的 Gemini 主力版本极为接近,相关能力预计很快将向数学界等可信测试者开放。
尽管 AI 已表现出强大实力,但人类参赛者依旧占据优势。本届比赛共有 5 名学生获得满分 42 分,金牌比例约为参赛选手的 10%。Gemini 模型从专用推理向通用模型的转变,标志着 AI 推理能力达到新高度,谷歌表示计划明年继续参赛,挑战满分纪录。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)