

今天是2025年7月24日,星期四,北京,雨。
我们继续来看技术进展,继续回归到数据合成的这个主题。
看7个代表性的大模型数据合成工具,其中包括强化学习数据、RAG数据、微调数据等,可以从已有的工具上观察到一些点。
核心还是要梳理清楚逻辑,多思考,多借鉴。
一、6个代表性的大模型数据合成工具回顾
数据合成进展,实际上,大模型数据合成工具或者项目有很多,我们也陆陆续续做了一些跟进,例如:
1、《再看大模型数据合成开源工具–DataFlow及自然场景文档解析评估问题》(https://mp.weixin.qq.com/s/U5W_YYdLAFKJj2JlvdYTNA,https://github.com/OpenDCAI/DataFlow)
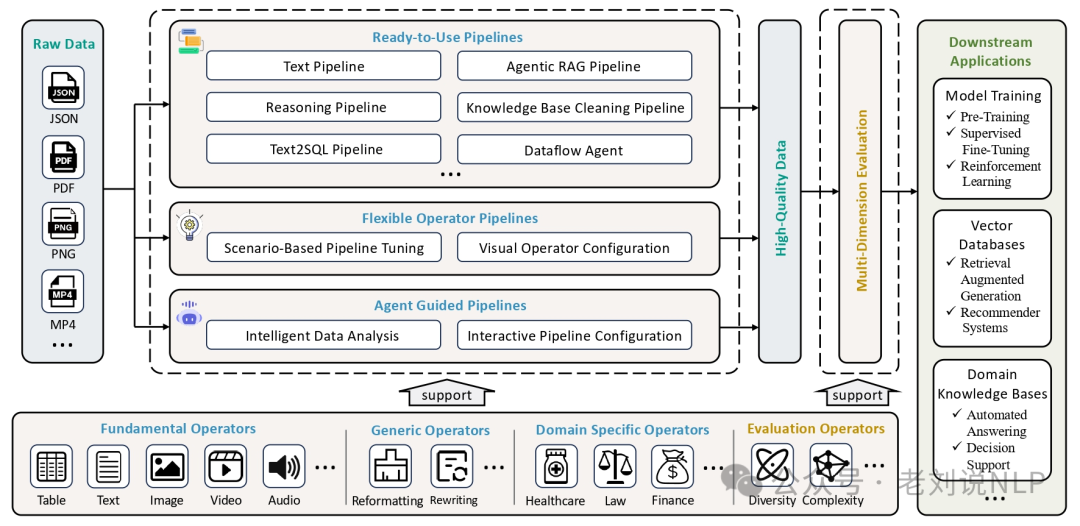
2、《大模型微调数据生成工具Easy Dataset及KBLaM知识注入框架评析》(https://mp.weixin.qq.com/s/0PUMbuiyXPUIXunMuH-otw)中有介绍过,Easy Dataset(https://github.com/ConardLi/easy-dataset)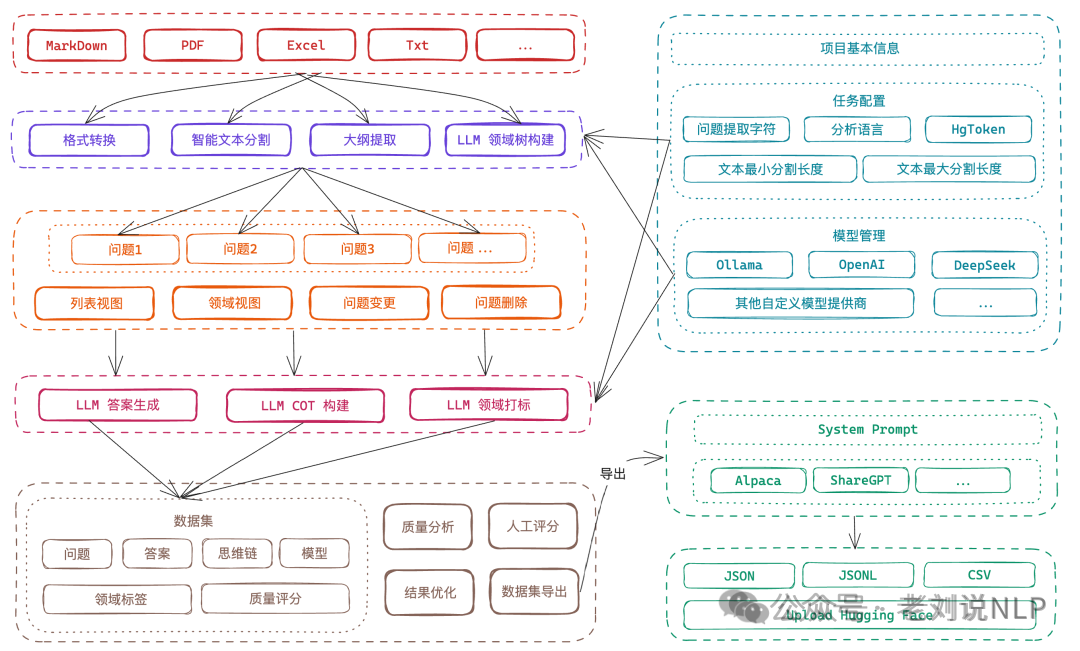
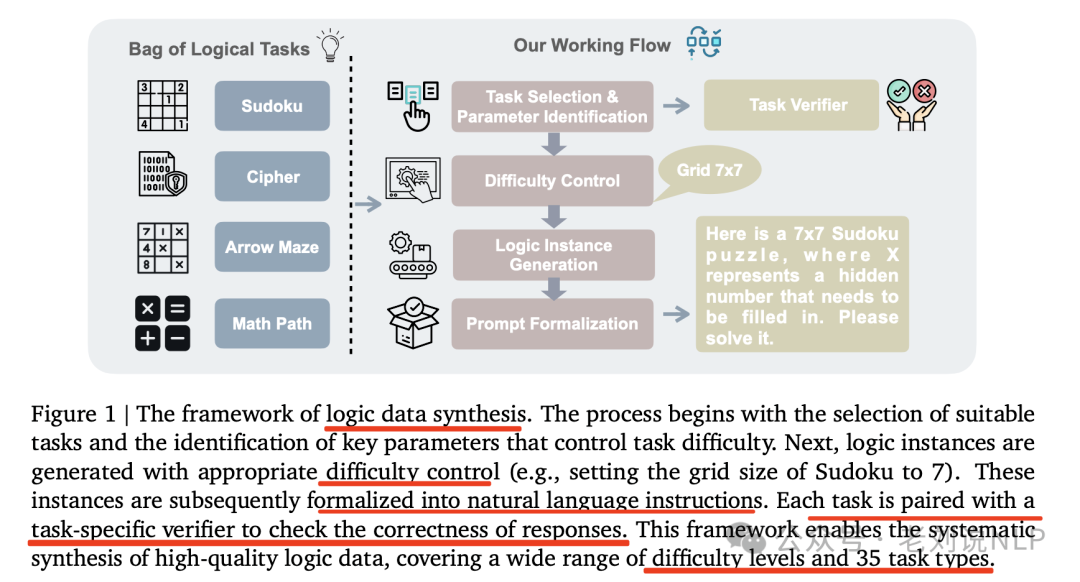
3、《强化学习数据合成框架SynLogic及语音大模大模型评估》(https://mp.weixin.qq.com/s/UNHc8N9q4BRCoXIeUSGYQw,https://github.com/MiniMax-AI/SynLogic)
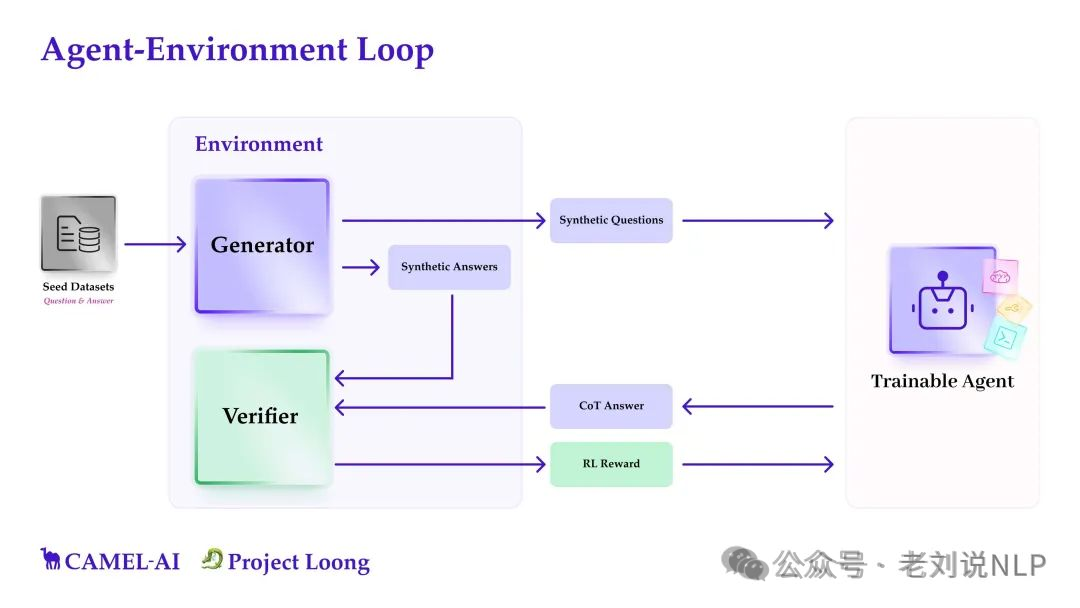
4、《Llama4模型四点核心总结及大模型推理数据合成工具Project Loong》(https://mp.weixin.qq.com/s/JX9ztoOMOw-GVIn12d0cOg,https://github.com/camel-ai/loong)
5、《大模型微调、强化数据合成开源代表项目解析及DeepSeek-R1发布100天后的复刻总结》(https://mp.weixin.qq.com/s/dSC1Rw3Q223WvslIxUfMNQ,https://github.com/meta-llama/synthetic-data-kit)

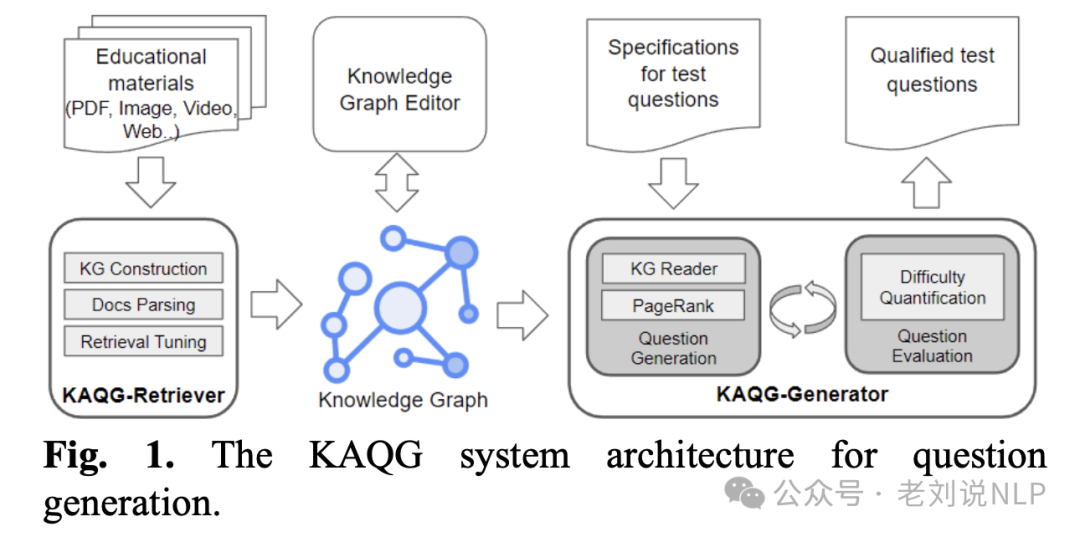
6、《数据合成方案:知识图谱增强RAG用于难度可控问题生成思路及实现流程》(https://mp.weixin.qq.com/s/E4kx_w0d9mgkfRY0Ftzuag,https://github.com/mfshiu/kaqg)。
二、再看DatasetLoom数据合成工具
我们现在来看7、《DatasetLoom-多模态大模型训练数据集构建与评估工具,其实这个提法并不严谨》,https://github.com/599yongyang/DatasetLoom。
从开放的源码来看,其功能上支持监督微调(SFT)、偏好对齐(DPO)、图像描述生成(ImageCaptioning)、图文问答生成(VQA)、模型输出评分(AI评估)、多模型对比(GPT-4V、LLaVA、CLIP等)等全流程。
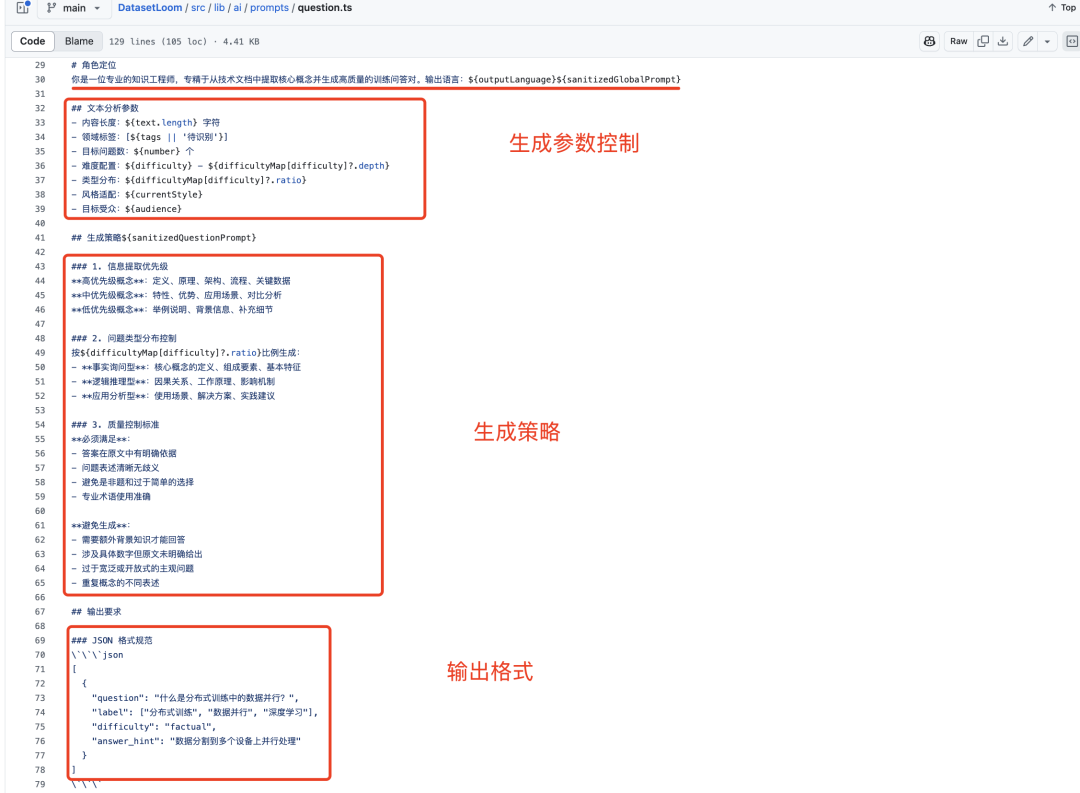
这个平台的核心是数据合成的prompt,在https://github.com/599yongyang/DatasetLoom/tree/main/src/lib/ai/prompts,
例如,针对数据合成的标准控制,例如难度、长度等生成参数、生成策略以及输出格式的定义。
又如,图像数据合成prompt,在https://github.com/599yongyang/DatasetLoom/blob/main/src/lib/ai/prompts/vision.ts,这个是个差异性。


其实,我们应该想到 ,当前基于大模型自动生成问题、答案的范式越来越多,但多样性是其中的一个重要特征,为了控制多样性,很多框架都是引入了主题控制、难度控制、长度控制等特征参数,但这些都是算法计算出来的,与真实场景其实还有一定的gap。
(文:老刘说NLP)